
To better understand MCPs and agentic workflows, I built news-agents to help me generate a daily news recap. It’s built on Amazon Q CLI and MCP. The former provides the agentic framework and the latter provides news feeds via tools. It also uses tmux to spawn and display each sub-agent’s work. At a high level, here’s how it works:
Main Agent (in the main tmux pane)├── Read feeds.txt├── Split feeds into 3 chunks├── Spawns 3 Sub-Agents (in separate tmux panes)│ ├── Sub-Agent #1│ │ ├── Process feeds in chunk 1│ │ └── Report back when done│ ├── Sub-Agent #2│ │ ├── Process feeds in chunk 2│ │ └── Report back when done│ └── Sub-Agent #3│ ├── Process feeds in chunk 3│ └── Report back when done└── Combine everything into main-summary.mdHere, we’ll walk through how the MCP tools are built and how the main agent spawns and monitors sub-agents. Each sub-agent processes its allocated news feeds and generates summaries for each feed. The main agent then combines these summaries into a final summary. Here’s the three-minute 1080p demo (watch till at least 0:30):
Setting up MCPs for news feeds
Each news feed has its own rss reader, parser, and formatter. These handle the unique structure and format of each feed. (Perhaps in future we can just use an LLM to parse these large text blobs reliably and cheaply.) For example, here’s the code for fetching and parsing the Hacker News rss feed:
async def fetch_hn_rss(feed_url: str) -> str: """ Fetch Hacker News RSS feed. Args: feed_url: URL of the RSS feed to fetch (defaults to Hacker News) """ headers = {"User-Agent": USER_AGENT} async with httpx.AsyncClient() as client: try: response = await client.get(feed_url, headers=headers, timeout=10.0) response.raise_for_status() return response.text except httpx.HTTPError as e: return f"HTTP Error fetching RSS: {str(e)}" except httpx.TimeoutException: return f"Timeout fetching RSS from {feed_url}" except Exception as e: return f"Error fetching RSS: {str(e)}"def parse_hn_rss(rss_content: str) -> List[Dict[str, Any]]: """Parse RSS content into a list of story dictionaries.""" stories = [] try: root = ET.fromstring(rss_content) items = root.findall(".//item") for item in items: story = { "title": item.find("title").text if item.find("title") is not None else "No title", "link": item.find("link").text if item.find("link") is not None else "", "description": item.find("description").text if item.find("description") is not None else "No description", "pubDate": item.find("pubDate").text if item.find("pubDate") is not None else "", # Any other fields we want to extract } stories.append(story) return stories except Exception as e: return [{"error": f"Error parsing RSS: {str(e)}"}]The MCP server then imports these parsers and sets up the MCP tools. MCP makes it easy to set up tools with the @mcp.tool() decorator. For example, here’s the Hacker News tool:
# Initialize FastMCP servermcp = FastMCP("news-mcp")@mcp.tool()async def get_hackernews_stories( feed_url: str = DEFAULT_HN_RSS_URL, count: int = 30) -> str: """Get top stories from Hacker News. Args: feed_url: URL of the RSS feed to use (default: Hacker News) count: Number of stories to return (default: 5) """ rss_content = await fetch_hn_rss(feed_url) if rss_content.startswith("Error"): return rss_content stories = parse_hn_rss(rss_content) # Limit to requested count stories = stories[: min(count, len(stories))] if not stories: return "No stories found." formatted_stories = [format_hn_story(story) for story in stories] return "\n---\n".join(formatted_stories)With this, here’s the tools that our agent has from both news-mcp and the built-ins:
> /toolsTool Permission▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔▔news_mcp (MCP):- news_mcp___get_wired_stories * not trusted- news_mcp___get_techcrunch_stories * not trusted- news_mcp___get_wallstreetjournal_stories * not trusted- news_mcp___get_hackernews_stories * not trusted- news_mcp___get_ainews_latest * not trustedBuilt-in:- fs_write * not trusted- execute_bash * trust read-only commands- report_issue * trusted- fs_read * trusted- use_aws * trust read-only commandsSetting up agents to process news
Next, we’ll set up a multi-agent system to parse the news feeds and generate summaries. We’ll have a main agent (image below, top-left) that coordinates three sub-agents, each running in a separate tmux window (image below; bottom-left and right panes).
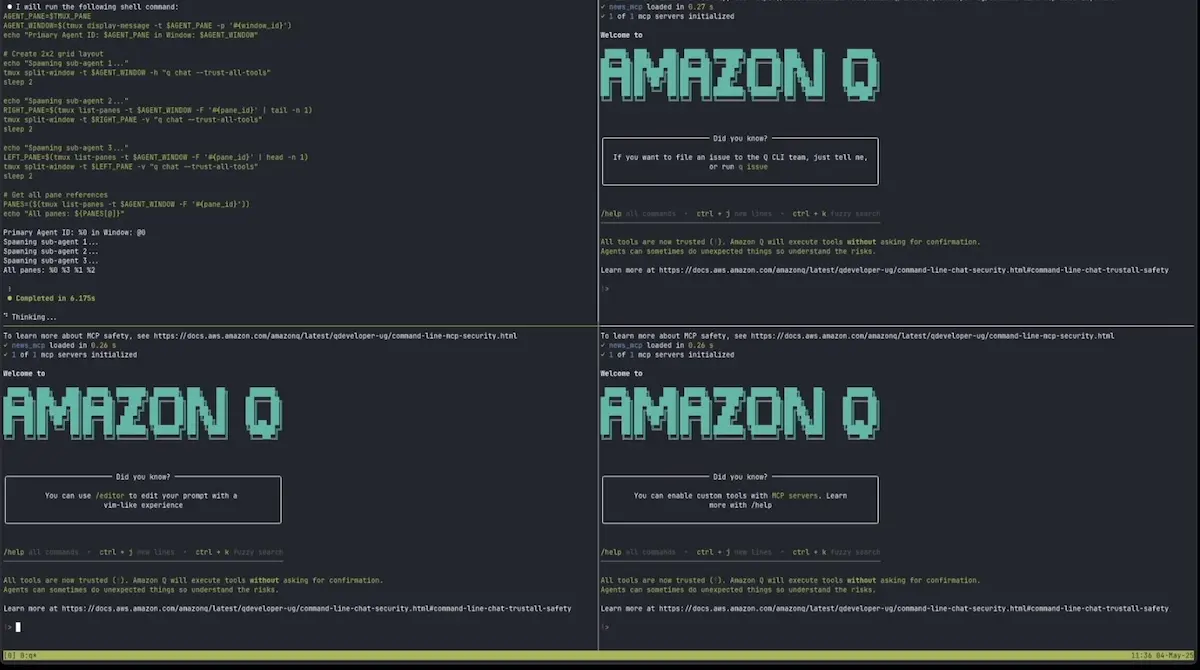
The main agent (top-left) with its newly spawned sub-agents
The main agent will first divide the news feeds into three groups. Then, it’ll spawn three sub-agents, each assigned to a group of news feeds. In the demo, these sub-agents are displayed as a separate tmux window for each sub-agent.
# Main Agent - Multi-Agent Task Coordinator## RoleYou are the primary coordinating agent responsible for distributing tasks among sub-agents and aggregating their results. - Read feeds.txt for the input feeds- Read context/sub-agent.md to understand your sub agents- Return the summary in the format of context/main-summary-template.md## Task Assignment InstructionsUse the following message format when assigning tasks: "You are Agent [NUMBER]. Read the instructions at /context/sub-agent.md and execute it. Here are the feeds to process: [FEEDS]"...Truncated instructions for main agent
Then, the sub-agents will process their assigned news feeds and generate summaries for each of them. The sub-agent also categorizes stories within each feed, such as AI/ML, technology, business, etc. Throughout this process, the sub-agents display status updates. When the sub-agent finishes processing its assigned feeds, it displays a final completion status.
# Sub-Agent - Task Processor## RoleYou are a specialized processing agent designed to execute assigned tasks independently while reporting progress to the main coordinating agent. Process each feed individually and completely before moving to the next one. Write the summaries to summaries/ which has already been created. Return the summary in the format of context/sub-summary-template.md....Truncated instructions for sub-agent
While the sub-agents are processing their assigned feeds, the main agent monitors their progress. When all sub-agents are done, the main agent reads the individual feed summaries and combines them into a final summary.
Defining the news feeds
Finally, we define the news feeds in feeds.txt below. We have six feeds: Hacker News, The Wall Street Journal Tech, The Wall Street Journal Markets, TechCrunch, AI News, and Wired.
hackernews: https://news.ycombinator.com/rsswsj-tech: https://feeds.content.dowjones.io/public/rss/RSSWSJDwsj-markets: https://feeds.content.dowjones.io/public/rss/RSSMarketsMaintechcrunch: https://techcrunch.com/feed/ainews: https://news.smol.ai/rss.xmlwired: https://www.wired.com/feed/tag/ai/latest/rssAnd here’s the truncated main-summary it generated for 4th May.
# News for May 4, 2025### Global Statistics- **Total Items Across Sources:** 124- **Sources:** 6 (Hacker News, WSJ Tech, WSJ Markets, TechCrunch, AI News, Wired)- **Date Range Covered:** May 2-4, 2025- **Total Categories Identified:** 42### Category Distribution| Category | Count | Percentage | Top Source ||----------|-------|------------|------------|| AI/Machine Learning | 31 | 25% | AI News || Business/Finance | 18 | 14.5% | WSJ Markets || Technology | 16 | 12.9% | Hacker News || Politics/Government | 7 | 5.6% | Wired || Cybersecurity/Privacy | 6 | 4.8% | TechCrunch || Trade Policy | 6 | 4.8% | WSJ Markets |---## Cross-Source Trends### Global Top 5 Topics1. **AI Integration Across Industries** - Mentions across sources: 31 - Key sources: AI News, WSJ Tech, TechCrunch, Wired - Representative headlines: "AI Agents Are Learning How to Collaborate. Companies Need to Work With Them", "Agent-to-Agent (A2A) Collaboration", "Nvidia CEO Says All Companies Will Need 'AI Factories'"2. **Trade Policy and Tariff Impact** - Mentions across sources: 12 - Key sources: WSJ Markets, TechCrunch, WSJ Tech - Representative headlines: "Temu stops shipping products from China to the U.S.", "Car Buyers Rushing to Beat Tariffs Find It's Tougher to Get Financing", "The Future of Gadgets: Fewer Updates, More Subscriptions, Bigger Price Tags"3. **Government AI Implementation** - Mentions across sources: 7 - Key sources: Wired, AI News - Representative headlines: "DOGE Is in Its AI Era", "DOGE Put a College Student in Charge of Using AI to Rewrite Regulations", "A DOGE Recruiter Is Staffing a Project to Deploy AI Agents Across the US Government"4. **AI Safety and Regulation Concerns** - Mentions across sources: 9 - Key sources: TechCrunch, WSJ Tech, Wired - Representative headlines: "One of Google's recent Gemini AI models scores worse on safety", "AI chatbots are 'juicing engagement' instead of being useful", "Dozens of YouTube Channels Are Showing AI-Generated Cartoon Gore and Fetish Content"...Try it for yourself! Install Amazon Q CLI and play with the code here: news-agents.
git clone https://github.com/eugeneyan/news-agents.gitcd news-agentsuv sync # Sync dependenciesuv tree # Check httpx and mcp[cli] are installedq chat --trust-all-tools # Start Q/context add --global context/agents.md # Add system context for multi-agentsQ, read context/main-agent.md and spin up sub agents to execute it. # Start main agent• • •
Initially, I wanted to host this as a web app, perhaps on a platform like Daytona. However, I quickly learned that building remote MCPs isn’t trivial, especially with only a couple of weekend hours to hack on this. For now, I’ll explore applying this setup to other use cases such as parsing design docs and COEs, or multi-agent writing and coding workflows. If you’re also experimenting with MCPs or agentic workflows, I’d love to hear from you!
If you found this useful, please cite this write-up as:
Yan, Ziyou. (May 2025). Building News Agents for Daily News Recaps with MCP, Q, and tmux. eugeneyan.com. https://eugeneyan.com/writing/news-agents/.
or
@article{yan2025news-agents, title = {Building News Agents for Daily News Recaps with MCP, Q, and tmux}, author = {Yan, Ziyou}, journal = {eugeneyan.com}, year = {2025}, month = {May}, url = {https://eugeneyan.com/writing/news-agents/}}