
Published on September 29, 2025 7:20 PM GMT
This seems like a good opportunity to do some of my classic detailed podcast coverage.
The conventions are:
- This is not complete, points I did not find of note are skipped.The main part of each point is descriptive of what is said, by default paraphrased.For direct quotes I will use quote marks, by default this is Sutton.Nested statements are my own commentary.Timestamps are approximate and from his hosted copy, not the YouTube version, in this case I didn’t bother because the section divisions in the transcript should make this very easy to follow without them.
Full transcript of the episode is here if you want to verify exactly what was said.
Well, that was the plan. This turned largely into me quoting Sutton and then expressing my mind boggling. A lot of what was interesting about this talk was in the back and forth or the ways Sutton lays things out in ways that I found impossible to excerpt, so one could consider following along with the transcript or while listening.

Sutton Says LLMs Are Not Intelligent And Don’t Do Anything
- (0:33) RL and LLMs are very different. RL is ‘basic’ AI. Intelligence and RL are about understanding your world. LLMs mimic people, they don’t figure out what to do.
- RL isn’t strictly about ‘understanding your world’ except insofar as it is necessary to do the job. The same applies to LLMs, no?To maximize RL signal you need to understand and predict the world, aka you need intelligence. To mimic people, you have to understand and predict them, which in turn requires understanding and predicting the world. Same deal.
- People don’t always have an explicit world model, but sometimes they do, and they have an implicit one running under the hood.Even if people didn’t have a world model in their heads, their outputs in a given situation depend on the world, which you then have to model, if you want to mimic those humans.People predict what will happen all the time, on micro and macro levels. On the micro level they are usually correct. On sufficiently macro levels they are often wrong, but this still counts. If the claim is ‘if you can’t reliably predict what will happen then you don’t have a model’ then we disagree on what it means to have a model, and I would claim no such-defined models exist at any interesting scale or scope.
- That’s not the suggestion. If [X] is often followed by [Y], then the suggestion is not ‘if [X] then you should do [Y]’ it it ‘[X] means [Y] is likely’ so yes if you are asked ‘what is likely after [X]’ it will respond [Y] but it will also internalize everything implied by this fact and the fact is not in any way normative.That’s still ‘learning from experience’ it’s simply not continual learning.Do LLMs do continual learning, e.g. ‘from what actually happens in your life’ in particular? Not in their current forms, not technically, but there’s no inherent reason they couldn’t, you’d just do [mumble] except that doing so would get rather expensive.You can also have them learn via various forms of external memory, broadly construed, including having them construct programs. It would work.Not that it’s obvious that you would want an LLM or other AI to learn specifically from what happens in your life, as opposed to learning from things that happen in lives in general plus having context and memory.
- I don’t see Dwarkesh’s question as a crux.I think Sutton’s response is quite bad, relying on invalid sacred word defenses.I think Sutton wants to draw a distinction between events in the world and tokens in a document. I don’t think you can do that.There is no ‘ground truth’ other than the feedback one gets from the environment. I don’t see why a physical response is different from a token, or from a numerical score. The feedback involved can come from anywhere, including from self-reflection if verification is easier than generation or can be made so in context, and it still counts. What is this special ‘ground truth’?Almost all feedback is noisy because almost all outcomes are probabilistic.You think that’s air you’re experiencing breathing? Does that matter?
- Why is this ‘not substantive’ in any meaningful way, especially if it is a description of a substantive consequence, which speech often is?How is it not ‘surprise’ when a low-probability token appears in the text?There are plenty of times a human is surprised by an outcome but does not learn from it out of context. For example, I roll a d100 and get a 1. Okie dokie.LLMs do learn from a surprising token in training. You can always train. This seems like an insistence that surprise requires continual learning? Why?
- What is Sutton even saying, at this point?Again, this distinction that outputting or predicting a token is distinct from ‘taking an action,’ and getting a token back is not the world responding.I’d point out the same applies to the rest of the tokens in context without CoT.
- Okay, seriously, this is crazy, right?What is this ‘substantive’ thing? If you say something on the internet, it gets read in real life. It impacts real life. It causes real people to do ‘substantive’ things, and achieving many goals within the internet requires ‘substantive’ changes in the offline world. If you’re dumb on the internet, you’re dumb in real life. If you die on the internet, you die in real life (e.g. in the sense of an audience not laughing, or people not supporting you, etc).I feel dumb having to type that, but I’m confused what the confusion is.Of course next token prediction is a goal. You try predicting the next token (it’s hard!) and then tell me you weren’t pursuing a goal.Next token prediction does influence the tokens in deployment because the LLM will output the next most likely token, which changes what tokens come after, its and the user’s, and also the real world.Next token prediction does influence the world in training, because the feedback on that prediction’s accuracy will change the model’s weights, if nothing else. Those are part of the world.If intelligence requires goals, and something clearly displays intelligence, then that something must have a goal. If you conclude that LLMs ‘don’t have intelligence’ in 2025, you’ve reached a wrong conclusion. Wrong conclusions are wrong. You made a mistake. Retrace your steps until you find it.
- Are you kidding me? So symbolic things aren’t real, period, and manipulating them can’t be intelligence, period?
- This seems like backtracking on the Bitter Lesson? At least kinda. Mostly he’s repeating that LLMs are one way and it’s the other way, and therefore Bitter Lesson will be illustrated the other way?
- I do not get where ‘truly scalable’ is coming from here, as it becomes increasingly clear that he is using words in a way I’ve never seen before.If anything it is the opposite. The real objection is training efficiency, or failure to properly update from direct relevant experiences, neither of which has anything to do with scaling.I also continue not to see why there is this distinction ‘human knowledge’ versus other information? Any information available to the AI can be coded as tokens and be put into an LLM, regardless of its ‘humanness.’ The AI can still gather or create knowledge on its own, and LLMs often do.
- Again, the word ‘scaling’ is being used in a completely alien manner here. He seems to be trying to say ‘successful’ or ‘efficient.’You have to have a ‘goal’ in the sense of a means of selecting actions, and a way of updating based on those actions, but in this sense LLMs in training very obviously have ‘goals’ regardless of whether you’d use that word that way.Except Sutton seems to think this ‘goal’ needs to exist in some ‘real world’ sense or it doesn’t count and I continue to be boggled by this request, and there are many obvious counterexamples, but I risk repeating myself.No sense of better or worse? What do you think thumbs up and down are? What do you think evaluators are? Does he not think an LLM can do evaluation?
Sutton has a reasonable hypothesis that a different architecture, that uses a form of continual learning and that does so via real world interaction, would be an interesting and potentially better approach to AI. That might be true.
But his uses of words do not seem to match their definitions or common usage, his characterizations of LLMs seem deeply confused, and he’s drawing a bunch of distinctinctions and treating them as meaningful in ways that I don’t understand. This results in absurd claims like ‘LLMs are not intelligent and do not have goals’ and that feedback from digital systems doesn’t count and so on.
It seems like a form of essentialism, the idea that ‘oh LLMs can never [X] because they don’t [Y]’ where when you then point (as people frequently do) to the LLM doing [X] and often also doing [Y] and they say ‘la la la can’t hear you.’
Humans Do Imitation Learning
- Dwarkesh claims humans initially do imitation learning, Sutton says obviously not. “When I see kids, I see kids just trying things and waving their hands around and moving their eyes around. There’s no imitation for how they move their eyes around or even the sounds they make. They may want to create the same sounds, but the actions, the thing that the infant actually does, there’s no targets for that. There are no examples for that.”
- GPT-5 Thinking says partly true, but only 30% in the first months, more later on. Gemini says yes. Claude says yes: “Imitation is one of the core learning mechanisms from birth onward. Newborns can imitate facial expressions within hours of birth (tongue protrusion being the classic example). By 6-9 months, they’re doing deferred imitation – copying actions they saw earlier. The whole mirror neuron system appears to be built for this.”Sutton’s claim seems clearly so strong as to be outright false here. He’s not saying ‘they do more non-imitation learning than imitation learning in the first few months,’ he is saying ‘there are no examples of that’ and there are very obviously examples of that. Here’s Gemini: “Research has shown that newborns, some just a few hours old, can imitate simple facial expressions like sticking out their tongue or opening their mouth. This early imitation is believed to be a reflexive behavior that lays the groundwork for more intentional imitation later on.”
- At this point I kind of wonder if Sutton has met humans?As in, I do imitation learning. All. The Time. Don’t you? Like, what?As in, I do supervised learning. All. The. Time. Don’t you? Like, what?A lot of this supervised and imitation learning happens outside of ‘school.’You even see supervised learning in animals, given the existence of human supervisors who want to teach them things. Good dog! Good boy!You definitely see imitation learning in animals. Monkey see, monkey do.The reason not to do supervised learning is the cost of the supervisor, or (such as in the case of nature) their unavailability. Thus nature supervises, instead.The reason not to do imitation learning in a given context is the cost of the thing to imitate, or the lack of a good enough thing to imitate to let you continue to sufficiently progress.
- Because we want to create something that has what only humans have and humans don’t, which is a high level of intelligence and ability to optimize the arrangements of atoms according to our preferences and goals.Understanding an existing intelligence is not the same thing as building a new intelligence, which we have also managed to build without understanding.The way animals have (limited) intelligence does not mean this is the One True Way that intelligence can ever exist. There’s no inherent reason an AI needs to mimic a human let alone an animal, except for imitation learning, or in ways we find this to be useful. We’re kind of looking for our keys under the streetlamp here, while assuming there are no keys elsewhere, and I think we’re going to be in for some very rude (or perhaps pleasant?) surprises.I don’t want to make a virtual squirrel and scale it up. Do you?
- You could of course one-shot the process with sufficient intelligence and understanding of the world, what Henrich is pointing out is that in practice this was obviously impossible and not how any of this went down.Seems like Sutton is saying again that the difference between humans and squirrels is a ‘small thing’ and we shouldn’t care about it? I disagree.
- Moravec’s paradox is misleading. There will of course be all four quadrants of things, where for each of [AI, human] things will be [easy, hard].The same is true for any pair of humans, or any pair of AIs, to a lesser degree.The reason it is labeled a paradox is that there are some divergences that look very large, larger than one might expect, but this isn’t obvious to me.
The Experimental Paradigm
- “The experiential paradigm. Let’s lay it out a little bit. It says that experience, action, sensation—well, sensation, action, reward—this happens on and on and on for your life. It says that this is the foundation and the focus of intelligence. Intelligence is about taking that stream and altering the actions to increase the rewards in the stream…. This is what the reinforcement learning paradigm is, learning from experience.”
- Can be. Doesn’t have to be.A priori knowledge exists. Paging Descartes’ meditator! Molyneux’s problem.Words, written and voiced, are sensation, and can also be reward.Thoughts and predictions, and saying or writing words, are actions.All of these are experiences. You can do RL on them (and humans do this).
- That sounds exactly like ‘make number go up’ with extra steps.
- Okie dokie, this does cause confusion with ‘world models’ that minds have, as Sutton points out later, so using the same word for both is unfortunate.I do think we’re stuck with ‘model’ here, but I’d be happy to support moving to ‘network’ or another alternative if one got momentum.
- Okie dokie, again, but these two are not rivalrous actions.If anything they are complements. If you learn from general knowledge and experiences it is highly useful to copy you. If you are learning from local particular experiences then your usefulness is likely more localized.As in, suppose I had a GPT-5 instance, embodied in a humanoid robot, that did continual learning, which let’s call Daneel. I expect that Daneel would rapidly become a better fit to me than to others.Why wouldn’t you want to learn from all sources, and then make copies?One answer would be ‘because to store all that info the network would need to be too large and thus too expensive’ but that again pushes you in the other direction, and towards additional scaffolding solutions.
- Well sure, but there are any number of ways to get that context, and to learn that policy. You can even write the policy down (e.g. in claude.md).Often it would be actively unwise to put that knowledge into weights. There is a reason humans will often use forms of external memory. If you were planning to copy a human into other contexts you’d use it even more.
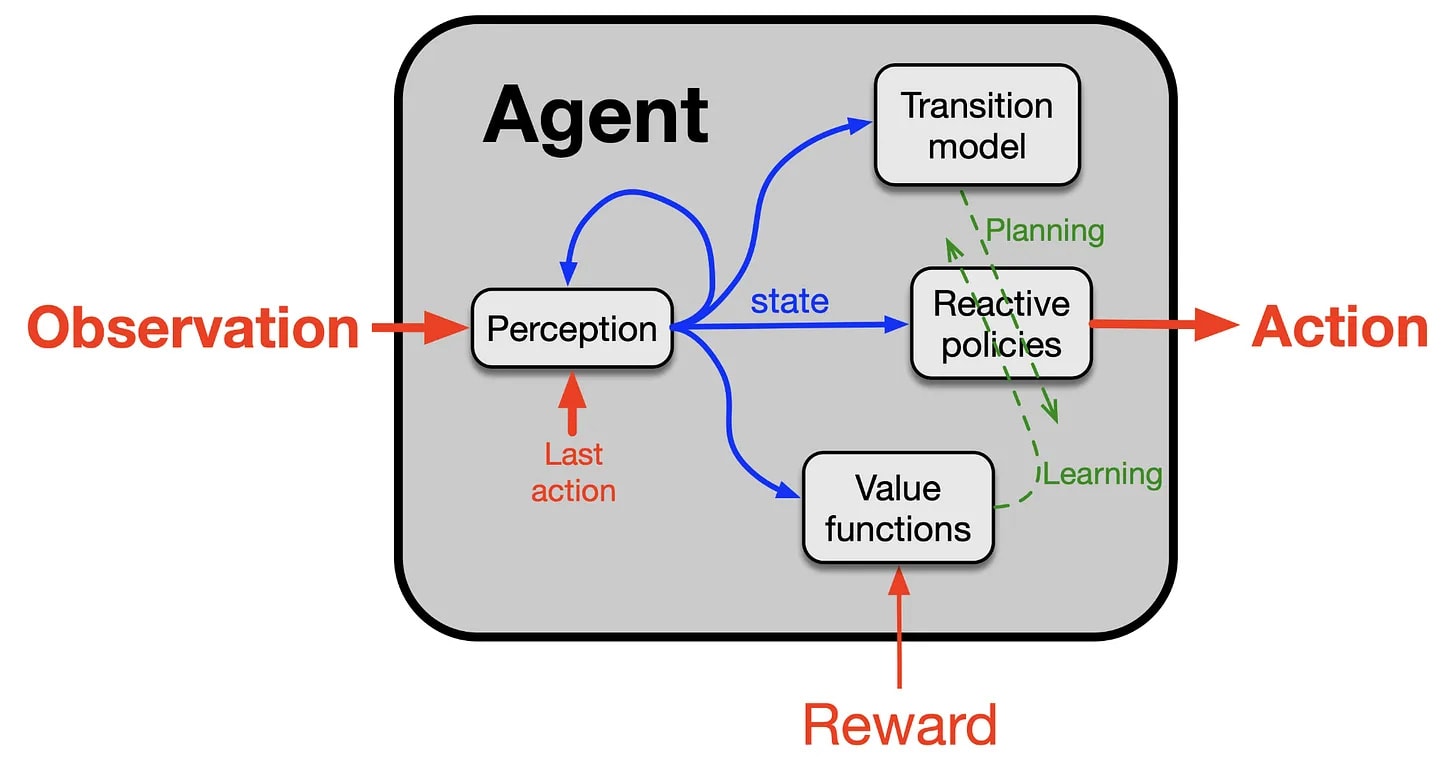
- Sutton lays out the above common model of the agent. The new claim seems to be that you learn from all the sensation you receive, not just from the reward. And there is emphasis on the importance of the ‘transition model’ of the world.
- I once again don’t see the distinction between this and learning from a stream of tokens, whether one or two directional, or even from contemplation, where again (if you had an optimal learning policy) you would pay attention to all the tokens and not only to the formal reward, as indeed a human does when learning from a text, or from sending tokens and getting tokens back in various forms.In terms of having a ‘transition model,’ I would say that again this is something all agents or networks need similarly, and can ‘get away with not having’ to roughly similar extents.
Current Architectures Generalize Poorly Out Of Distribution
So do humans.
- Sutton claims people live in one world that may involve chess or Atari games and and can generalize across not only games but states, and will happen whether that generalization is good or bad. Whereas gradient descent will not make you generalize well, and we need algorithms where the generalization is good.
- I’m not convinced that LLMs or SGD generalize out-of-distribution (OOD) poorly relative to other systems, including humans or RL systems, once you control for various other factors.I do agree that LLMs will often do pretty dumb or crazy things OOD.All algorithms will solve the problem at hand. If you want that solution to generalize, you need to either make the expectation of such generalization part of the de facto evaluation function, develop heuristics and methods that tend to lead to generalization for other reasons, or otherwise incorporate the general case, or choose or get lucky with a problem where the otherwise ‘natural’ solution does still generalize.
- Sutton only thinks you can generalize given the ability to not generalize, the way good requires the possibility of evil. It is a relative descriptor.I don’t understand why you’d find that definition useful or valid. I care about the generality of your solution in practice, not whether there was a more or less general alternative solution also available.Once again there’s this focus on whether something ‘counts’ as a thing. Yes, of course, if the only or simplest or easiest way to solve a special case is to solve the general case, which often happens, and thus you solve the general case, and this happens to solve a bunch of problem types you didn’t consider, then you have done generalization. Your solution will work in the general case, whether or not you call that OOD.If there’s only one answer and you find it, you still found it.This seems pretty central. SGD or RL or other training methods, of both humans and AIs, will solve the problem you hand to them. Not the problem you meant to solve, the problem and optimization target you actually presented.You need to design that target and choose that method, such that this results in a solution that does what you want it to do. You can approach that in any number of ways, and ideally (assuming you want a general solution) you will choose to set the problem up such that the only or best available solution generalizes, if necessary via penalizing solutions that don’t in various ways.
- Very obviously coding agents generalize to problems they haven’t seen.Not fully to ‘all coding of all things’ but they generalize quite a bit and are generalizing better over time. Seems odd to deny this?Sutton is making at least two different claims.The first claim is that coding agents only find solutions to problems they have seen. This is at least a large overstatement.The second claim is that the algorithms will not cause the network to choose solutions that generalize well over alternative solutions that don’t.The second claim is true by default. As Sutton notes, sometimes the default or only solution does indeed generalize well. I would say this happens often. But yeah, sometimes by default this isn’t true, and then by construction and default there is nothing pushing towards finding the general solution.Unless you design the training algorithms and data to favor the general solution. If you select your data well, often you can penalize or invalidate non-general solutions, and there are various algorithmic modifications available.One solution type is giving the LLM an inherent preference for generality, or have the evaluator choose with a value towards generality, or both.No, it isn’t going to be easy, but why should it be? If you want generality you have to ask for it. Again, compare to a human or an RL program. I’m not going for a more general solution unless I am motivated to do so, which can happen for any number of reasons.
Surprises In The AI Field
- Dwarkesh asks what has been surprising in AI’s big picture? Sutton says the effectiveness of artificial neural networks. He says ‘weak’ methods like search and learning have totally won over ‘strong’ methods that come from ‘imbuing a system with human knowledge.’
- I find it interesting that Sutton in particular was surprised by ANNs. He is placing a lot of emphasis on copying animals, which seems like it would lead to expecting ANNs.It feels like he’s trying to make ‘don’t imbue the system with human knowledge’ happen? To me that’s not what makes the ‘strong’ systems strong, or the thing that failed. The thing that failed was GOFAI, the idea that you would hardcode a bunch of logic and human knowledge in particular ways, and tell the AI how to do things, rather than letting the AI find solutions through search and learning. But that can still involve learning from human knowledge.It doesn’t have to (see AlphaZero and previously TD-Gammon as Sutton points out), and yes that was somewhat surprising but also kind of not, in the sense that with More Dakka within a compact space like chess you can just solve the game from scratch.As in: We don’t need to use human knowledge to master chess, because we can learn chess through self-play beyond human ability levels, and we have enough compute and data that way that we can do it ‘the hard way.’ Sure.
Will The Bitter Lesson Apply After AGI?
- Dwarkesh asks what happens to scaling laws after AGI is created that can do AI research. Sutton says: “These AGIs, if they’re not superhuman already, then the knowledge that they might impart would be not superhuman.”
- This seems like more characterization insistence combined with category error?And it ignores or denies the premise of the question, which is that AGI allows you to scale researcher time with compute the same way we previously could scale compute spend in other places. Sutton agrees that doing bespoke work is helpful, it’s just that it doesn’t scale, but what if it did?Even if the AGI is not ‘superhuman’ per se, the ability to run it faster and in parallel and with various other advantages means it can plausibly produce superhuman work in AI R&D. Already we have AIs that can do ‘superhuman’ tasks in various domains, even regular computers are ‘superhuman’ in some subdomains (e.g. arithmetic).
- Help from another agent is experience. It can also directly create experience.The context is chess where this is even more true.Indeed, the way AlphaZero was trained was not to not involve other agents. The way AlphaZero was trained involved heavy use of other agents, except all those other agents were also AlphaZero.
- I agree that things get strange and different and we should ask new questions.Asking whether it is possible for an ASI (superintelligent AI) copy to learn something new and then incorporate it into the original seems like such a strange question.
- It presupposes this ‘continual learning’ thesis where the copy ‘learns’ the information via direct incorporation into its weights.It then assumes that passing on this new knowledge requires incorporation directly into weights or something weird?As opposed to, ya know, writing the insight down and the other ASI reading it? If ASIs are indeed superintelligent and do continual learning, why can’t they learn via reading? Wouldn’t they also get very good at knowing how to describe what they know?Also, yes, I’m pretty confident you can also do this via direct incorporation of the relevant experiences, even if the full Sutton model holds here in ways I don’t expect. You should be able to merge deltas directly in various ways we already know about, and in better ways that these ASIs will be able to figure out.Even if nothing else works, you can simply have the ‘base’ version of the ASI in question rerun the relevant experiences once it is verified that they led to something worthwhile, reducing this to the previous problem, says the mathematician.
- Seems fun to think about, but nothing an army of ASIs couldn’t handle.In general, when imagining scenarios with armies of ASIs, you have to price into everything the fact that they can solve problems way better than you.I don’t think the associated ‘mind viruses’ in this scenario are fundamentally different than the problems with memetics and hazardous information we experience today, although they’ll be at a higher level.I would of course expect lots of new unexpected and weird problems to arise.
Succession To AI
It’s Sutton, so eventually we were going to have to deal with him being a successionist.
- He argues that succession is inevitable for four reasons: Humanity is incapable of a united front, we will eventually figure out intelligence, we will eventually figure out superhuman intelligence, and it is inevitable that over time the most intelligent things around would gain intelligence and power.
- We can divide this into two parts. Let “it” equal superintelligence.Let’s call part one Someone Will Build It.Let’s call part two If Anyone Builds It, Everyone Dies.
- Okay, sure, not quite as you see below, but mostly? Yeah, mostly.
- Counterexample one is that if the intelligence gap is not so large in practical impact, other attributes can more than compensate for this. Other attributes, both mental and physical, also matter and can make up for this. Alas, this seems unlikely to be relevant given the expected intelligence gaps.Counterexample two is that you could ‘solve the alignment problem’ in a sufficiently robust sense that the more intelligent minds optimize for a world in which the less intelligent minds retain power in a sufficiently robust way. Extremely tricky, but definitely not impossible in theory.
- If ‘AI-enhanced, augmented humans’ count here, well, that’s me, right now.I mean, presumably that’s not exactly what he meant.But yeah, conditional on us building ASIs or even AGIs, we’re at least dealing with some form of augmented humans.Talk of ‘merge with the AI’ is nonsense, you’re not adding anything to it, but it can enhance you.
- Designed is being used rather loosely here, but we get the idea.We already have created designed things, and yeah that’s pretty cool.
- It’s not about whether they are ‘part of humanity’ or our ‘children.’ They’re not.They can still have value. One can imagine aliens (as many stories have) that are not these things and still have value.That doesn’t mean that us going away would therefore be non-horrifying.
- So there you have it.I disagree.
- This is interestingly super different and in conflict with the previous claim.It’s fully the other way so far that I don’t even fully endorse it, this idea that change needs to be voluntary whenever it is imposed on people. That neither seems like a reasonable ask, nor does it historically end well, as in the paralysis of the West and especially the Anglosphere in many ways, especially in housing.I am very confident in what would happen if you asked about the changes Sutton is anticipating, and put them to a vote.
Fundamentally, I didn’t pull direct quotes on this but Sutton repeatedly emphasizes that AI-dominated futures can be good or bad, that he wants us to steer towards good futures rather than bad futures, and that we should think carefully about which futures we are steering towards and choose deliberately.
I can certainly get behind that. The difference is that I don’t think we need to accept this transition to AI dominance as our only option, including that I don’t think we should accept that humans will always be unable to coordinate.
Mostly what I found interesting were the claims around the limitations and nature of LLMs, in ways that don’t make sense to me. This did help solidify a bunch of my thinking about how all of this works, so it felt like a good use of time for that alone.
Discuss
