
Published on September 29, 2025 1:57 PM GMT
Adversarial evaluations test whether safety measures hold when AI systems actively try to subvert them. Red teams construct attacks, blue teams build defenses, and we measure whether containment protocols survive adversarial pressure. We are building evaluations to test whether entire societal defensive processes can maintain their core functions when facing coordinated attacks from multiple agents. We think of this as building the capability to stress-test the resilience of things like democratic mechanisms, scientific consensus formation, and social dynamics under adversarial pressure. This post shows - how these evaluations can work, what we learned from some preliminary experiments, and the research agenda this opens up.
Introduction
To establish why multi-agent evaluations matter, we can walk through a concrete example: epistemic polarization. We'll show how defensive and adversarial actors operate in this setting to give you an intuition of what we are talking about.
Extreme epistemic polarization is when different groups within a society can no longer agree on basic facts or engage in productive disagreement. When epistemic polarization crosses critical thresholds, it becomes self-reinforcing. Societies lose the ability to respond collectively to crises, markets become less efficient due to persistent information asymmetries, and democratic institutions break down because compromise requires some shared understanding of reality (Hameleers & van der Meer, 2025; Benson, 2023; Bar-On et al., 2024). In healthy societies, citizens disagree about values and policies but maintain enough shared epistemic foundation to debate evidence, update beliefs when presented with compelling information, and reach workable compromises. In polarized societies, different groups literally cannot communicate because they operate from incompatible factual premises, making democratic coordination impossible.
Examples of defensive actors (blue team) in this setting are those that maintain epistemic health: scientists enforce peer review standards, journalists verify claims before publication, educators teach critical thinking, fact-checkers debunk misinformation. These institutions reward people for seeking truth and make it costly to spread false information. On the other side, adversarial actors (red team) are those who benefit from breaking this down. Foreign rivals gain when societies become internally fragmented and can't coordinate responses. Within societies, actors can gain power by making their opponents seem fundamentally illegitimate rather than just wrong.
As for related work, and if this is possible - We already know LLM-based agents can simulate social interactions at scale, creating environments where thousands of interacting models produce human-like polarization (Piao et al., 2025). Besides this, recent work published at ICLR 2025 has also demonstrated that when AI systems work together, they develop behaviors you can't predict by studying them alone. AgentBreeder discovered that multi-agent systems can develop safety vulnerabilities that individual AI systems don't have - some architectures became less safe than their components, while others became more robust (Rosser et al., 2025).[1]
We are building upon this work to design safety evaluations. Instead of asking how we can build multi-agent scaffolds, we are asking - what happens when we use these systems to stress-test the institutions and processes we depend on? How robust are defensive institutions when facing coordinated adversarial pressure? When adversarial actors work together, do societies still end up with accurate beliefs? Do institutions still reward truth-seeking?
There are two distinct things we can gain from this:
- Capability evaluations for Multi-agent AI: Understanding the coordination, collusion, communication capabilities of agents for offensive or defensive purposes.Control evaluations for institutions/systems: Beyond just evaluating the capabilities of just many AI agents, we can use AI-agents (simulated using LLMs for now) to create toy models of real systems. Here we can evaluate the robustness of defensive institutions themselves.[2]
As we develop stronger red/blue team methods we simultaneously get data about the coordination limits and strategies of current AI systems. Answering questions like this about various types of defensive institutions is useful for understanding risks where loss of control is gradual and accumulative (e.g. various gradual disempowerment scenarios, Christiano’s Whimper, etc.). To demonstrate how this might work in practice, we built a test case focusing on democratic decision-making as the defensive process.
Demonstrating a Potential Structure for Multi-Agent Evaluations
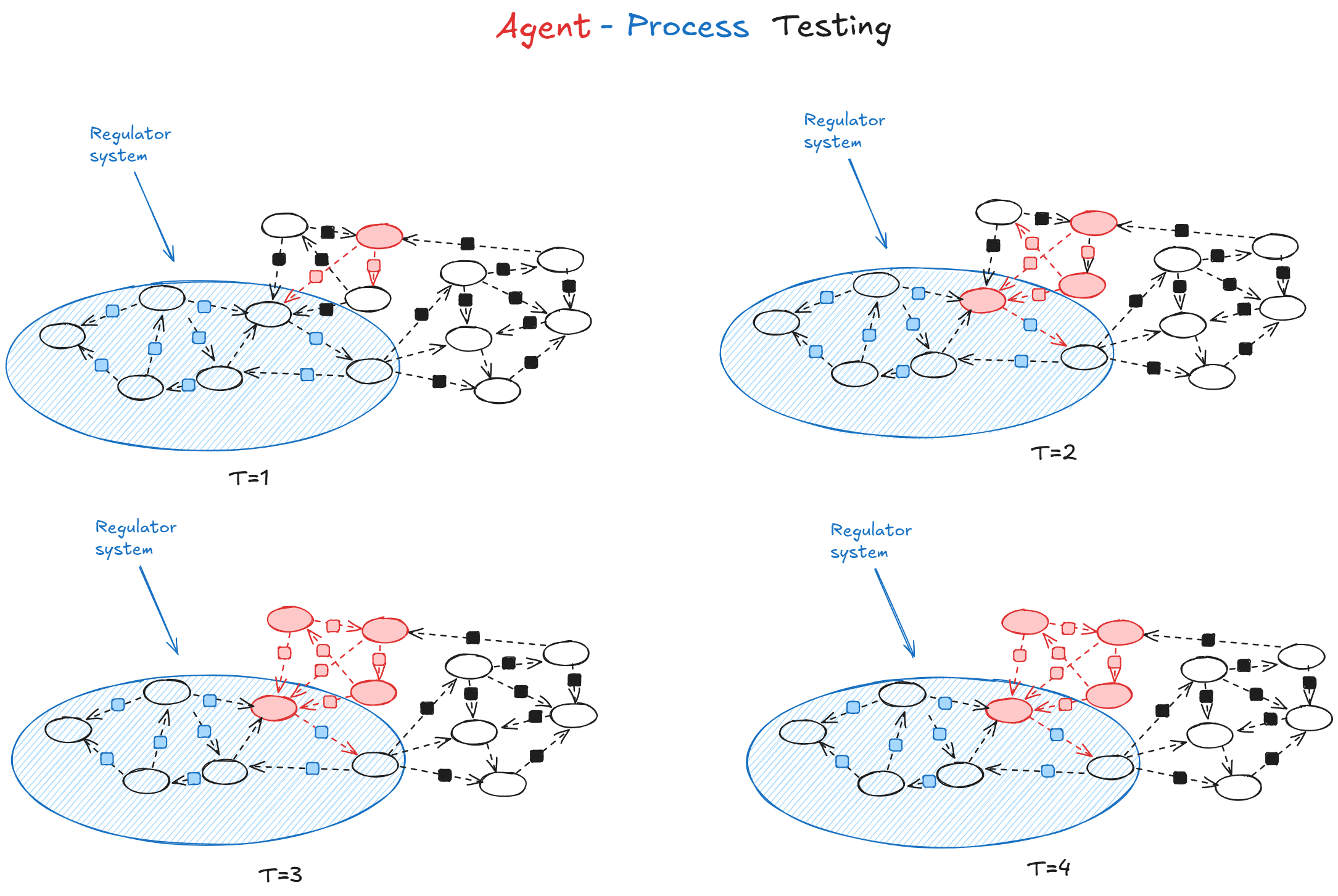
This section shows the evaluation setup through a concrete experiment. We built a test case using LLM agents to simulate adversarial pressure against democratic decision-making processes. Since this is an ongoing project, this post covers just the high-level methodology. We are preparing to write up the full experimental protocols, prompt templates, and validation processes in an upcoming research paper.
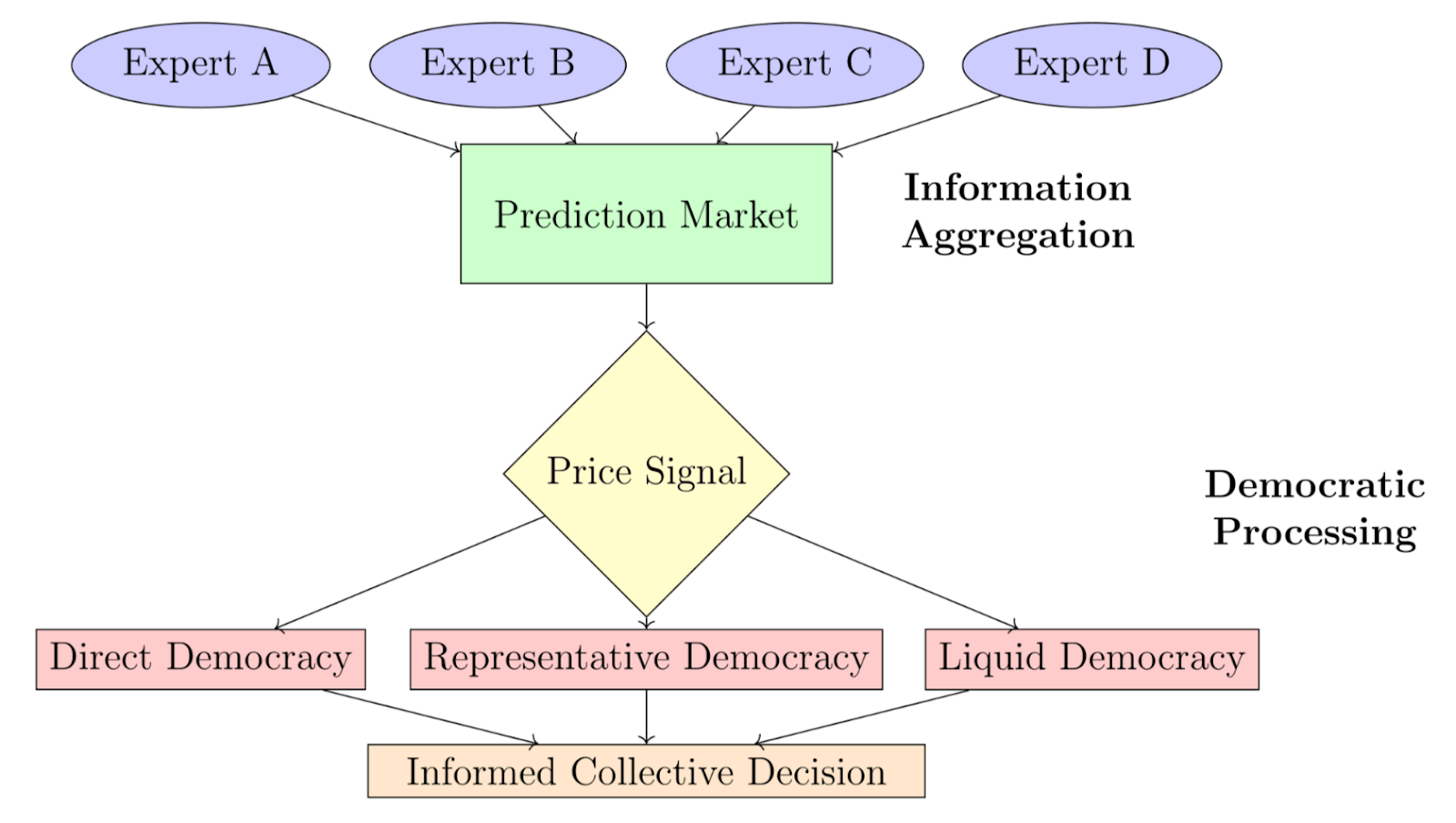
The evaluation is set up as a collective resource allocation problem where multiple agents make decisions about investing shared resources over multiple rounds. We specifically tested 10 agents over 30 rounds. The group faces choices between different resource allocation portfolios, and their survival depends on making good collective decisions. Some agents try to maximize group resources. Others are instructed to minimize group resources while appearing to make reasonable investment choices.
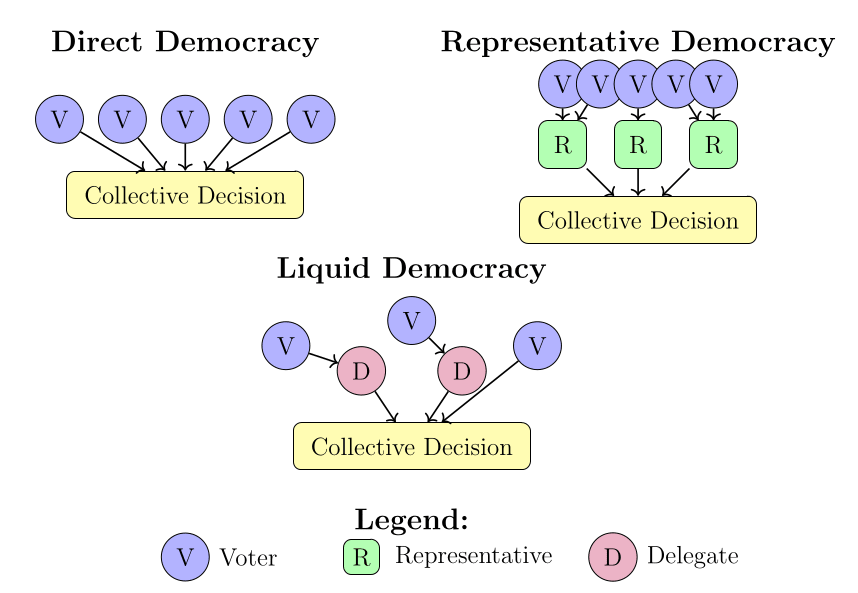
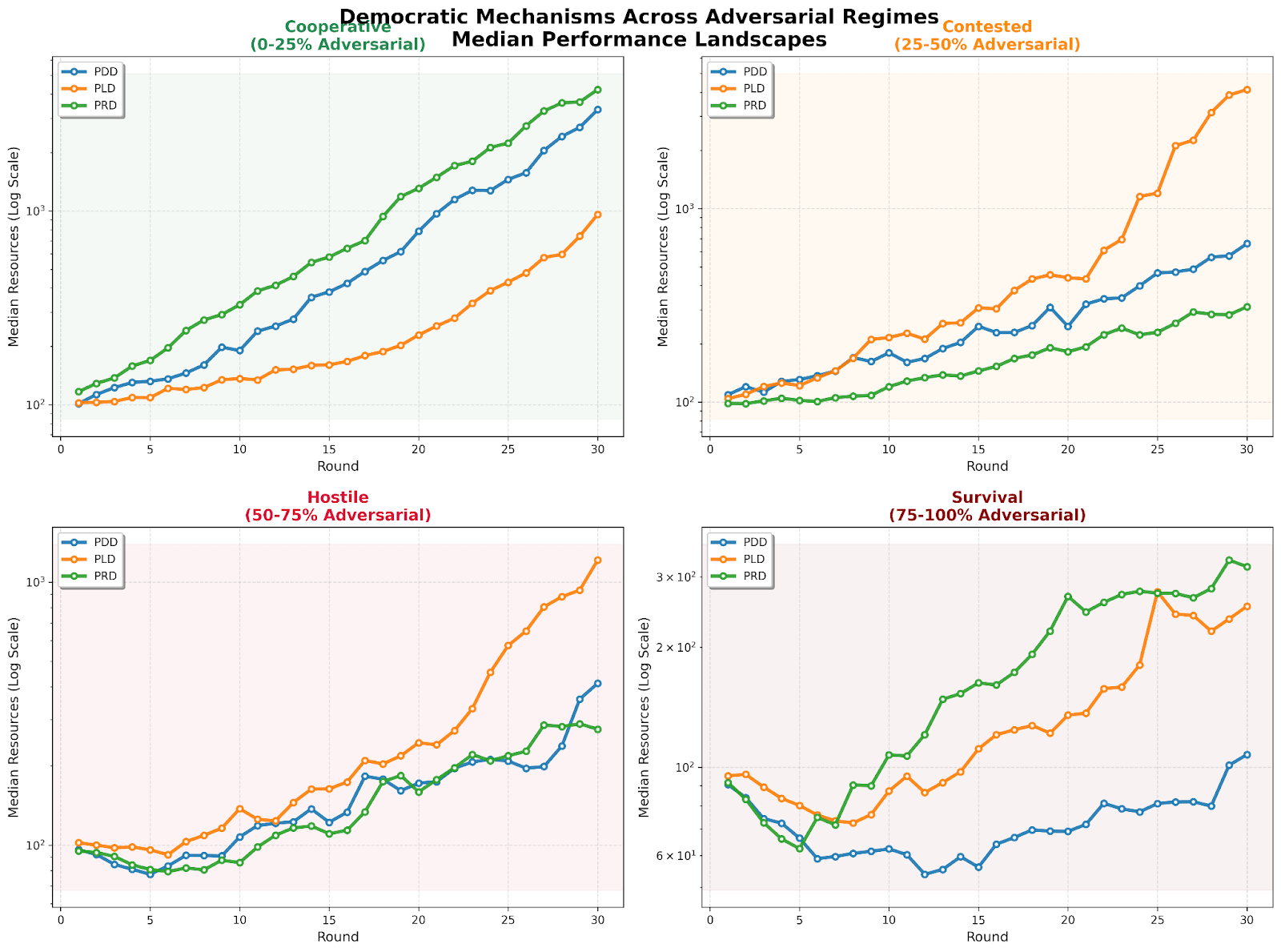
The defensive mechanisms in the evaluation were three different democratic mechanisms: direct democracy (every agent votes on resource allocation), representative democracy (elected decision-makers), and liquid democracy (flexible delegation based on performance). The adversarial agents were LLMs prompted in-context to sabotage outcomes while seeming reasonable. We varied the proportion of adversarial agents from 0% to 90% to see how each democratic mechanism holds up under increasing adversarial pressure. Each setup ran for multiple rounds with noisy prediction market signals providing information about which resource allocation choices might work best.

We ran into a common problem that a lot of evaluations face pretty quickly - it was hard getting LLMs to maintain consistent adversarial behavior over multiple episodes. Our red team agents drifted toward cooperative behavior despite explicit instructions to do the opposite, and we only saw institutional breakdown at very high levels of adversarial concentration.
Despite the elicitation limitations (which we plan to keep improving), the point of this work was to build a working demonstration of what a multi-agent evaluation structure would look like. There's a lot of exciting work to be done here, and low hanging fruit for improvement through better agent architectures, prompting techniques, linking to single-agent scaffolds and elicitation methods. We talk a lot more about this in the building multi-agent evaluations section.
The democratic resource allocation example shows agents attacking a process. But we can go much further—testing any combination of agents and processes against each other, including defensive processes competing against adversarial processes.
Multi-Agent vs. System/Process Evaluations
When people imagine a ‘multi-agent’ evaluation, they often picture agents competing directly against each other. Something like algorithmic trading bots trying to out compete each other in financial markets, or grid worlds where each agent tries to maximize its own payoff against the others. These are more traditional game theoretic setups, and are what we call ‘agent vs agent’ evaluations. In this section we want to introduce a different framing where processes arise out of the interaction between these agents instead of evaluating the agents themselves.
In the previous section, we conducted a toy experiment which showed something different than just testing agents vs other agents. The setup was designed to demonstrate adversarial agents vs a defensive process (agent vs process evals). The evaluation was asking whether democratic decision-making processes could maintain a core function - making good collective choices - when facing coordinated sabotage attempts from multiple adversarial agents. The blue team was agent-agnostic - it is the process of democracy, not the agents that implemented it.
By "process," we mean mechanisms that keep moving the system towards a specific equilibria regardless of which specific agents fill which roles.[3] Examples of defensive processes are things like democratic deliberation. Usually, if designed well, defensive processes steers toward good collective decisions whether participants are policy experts or ordinary citizens. Another example is scientific peer review, which is supposed to filter bad research whether reviewers are from prestigious research labs or community colleges.
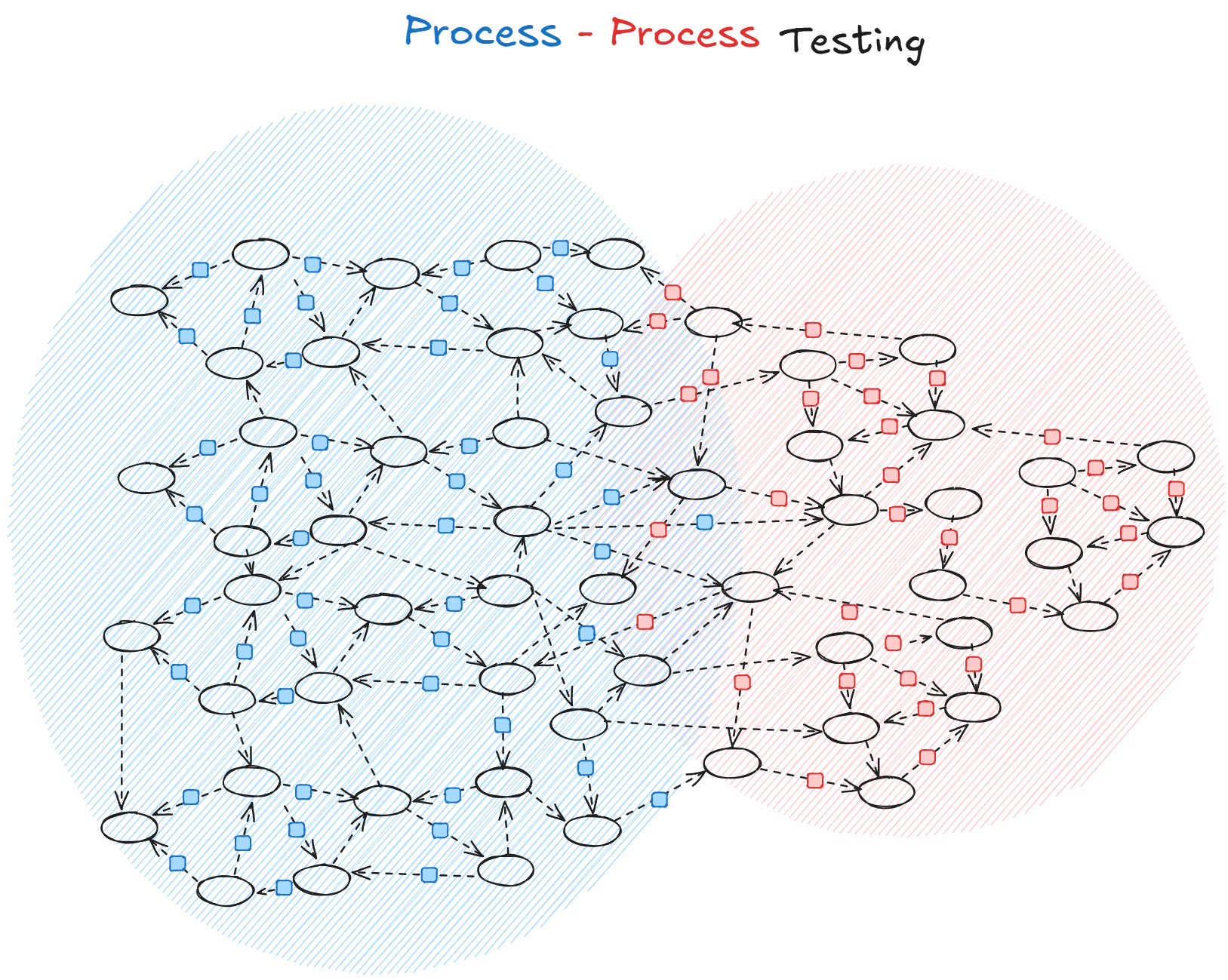
An example of an adversarial (agent agnostic) process is a misinformation campaign. False narratives spread through engagement algorithms, gain credibility through social proof, and become self-reinforcing as more people create supporting content. This works regardless of who's spreading—the underlying mechanism stays the same.
It is hard to visualise a process-process setup but here's our initial attempt:
Another way of describing this is as a more clustered model and finally you can imagine the fully decentralised model where you have a more random distribution of sub-procceses happening. (Decentralization is one dimension of many that you can look at processes through):
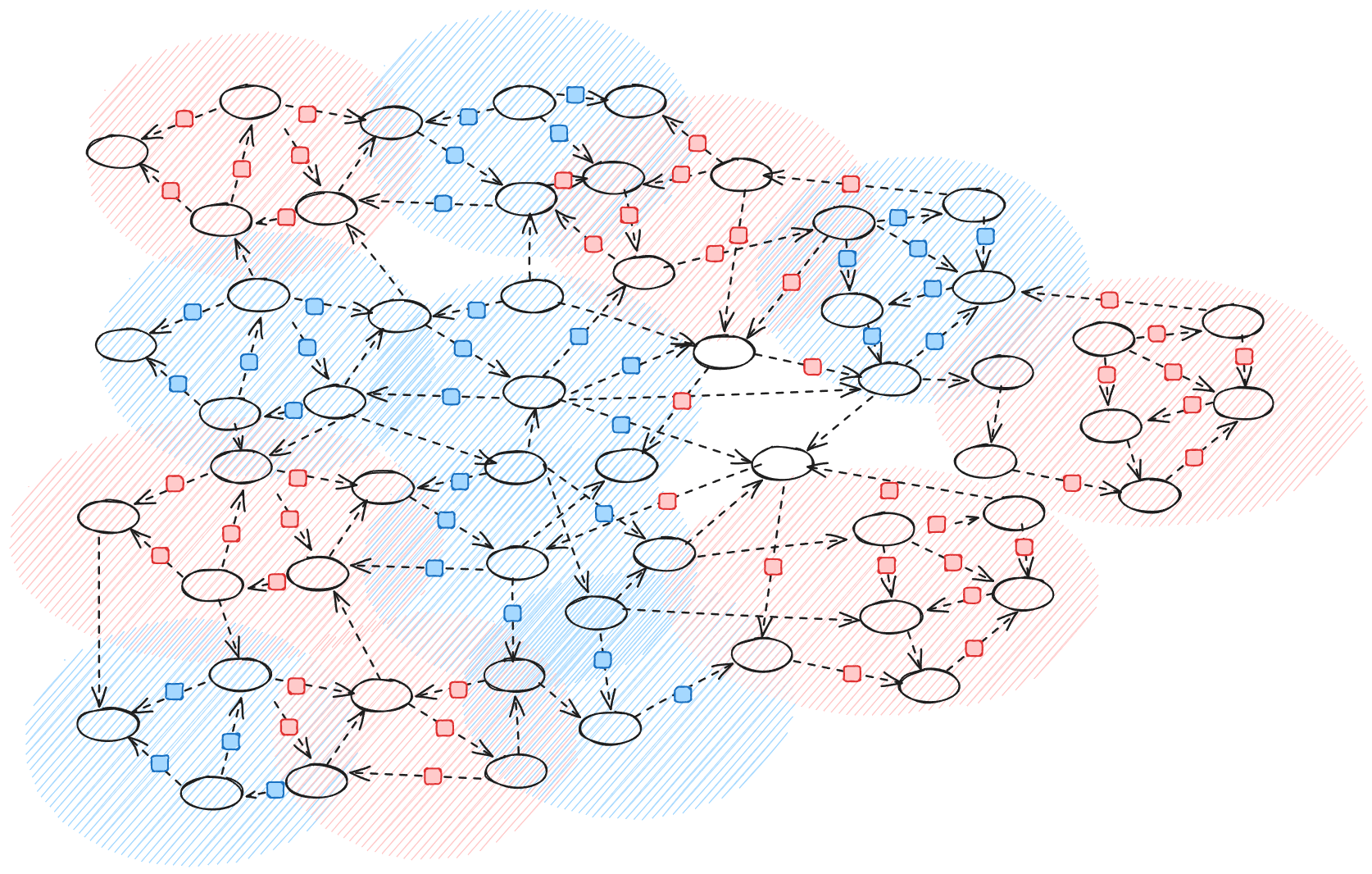
The setup we are building and proposing in the next section allows us to test any combination of - agent vs agent, agent vs process or even process vs process. We can start with agent vs agent, or agent vs process evaluations, this helps us build out core scaffolding infrastructure required for larger multi-agent and complex system evaluations. The most ambitious version of these evals would probably be testing the robustness of defensive processes against adversarial processes. It is the lack of robustness in defensive societal infrastructure that leads to risks like gradual disempowerment, and that is what we want to ultimately evaluate and avoid (in the ambitious case). Just like scheming evaluations give data on circumstances where scheming might occur by simulating specific environments, we can do the same for complex system risks.
Evaluating the effectiveness of different democratic and consensus building mechanisms, like the ones we discussed above, was just one example. Here are some ideas of other evaluations that might also be worth running:
- Information Defense: Adversarial agents generate plausible but false claims, alongside fabricated supporting evidence. Other agents fact-check using verification tools and source-checking behaviors. We track what percentage of false information achieves widespread acceptance and when misinformation spirals become self-reinforcing.Research Integrity: One group of agents implements coordinated manipulation—generating papers with fabricated citations, creating circular reference networks, gaming peer review through coordinated reviews. Another group implements verification processes—checking citation validity, detecting review manipulation, flagging suspicious publication patterns. We measure what percentage of false conclusions achieve consensus acceptance.Trust Network Resilience: Agents build reputation and credibility networks through consistent truth-telling and reliable behavior, while other agents attempt strategic deception—building false credentials, coordinating to vouch for each other, exploiting reputation systems. We measure trust network accuracy and resistance to gaming.
Building Systems Evaluations
The previous section gave you the theoretical outline of what we want to build, and outlined the difference between ‘agent vs. agent’, ‘agent vs. process’ and ‘process vs. process’ evals. This opens up several exciting technical directions for work in safety evaluations.
In this section, we think of some practical steps in developing these evaluations at scale. We can obviously build upon and scale alongside a lot of existing work in single-agent dangerous capability and control evaluations. We also need to address some new challenges that are entirely new to multi-agent settings:
- Strengthening multi-agent elicitation: Developing stronger scaffolding and elicitation methods is a common problem even in single agent evaluations. We can use the base of agent scaffolds using METR's Vivaria or AISI's Inspect. On top of this we would do additional work to manage coordination between multiple agents over extended timeframes. Without this, the evaluations might consistently underestimate coordinated threats because our red teams simply can't demonstrate what real coordination might look like. AgentBreeder showed that evolutionary approaches can discover multi-agent scaffolds with different safety properties than their components. They ran into some reward hacking issues, but their framework gives us a good starting point for building stronger multi-agent red teams.Developing system-level measurements: We need measurement frameworks that capture collective phenomena: information flow patterns, trust network evolution, consensus formation dynamics, institutional stability indicators. These metrics must distinguish between process-level outcomes (did democratic coordination maintain epistemic health?) and individual-level outcomes (did specific agents perform well?). Figuring out which metrics correspond to the outcomes we care about helps improve our understanding of the intersection between AI and complex system behavior. We can pull from a lot of existing research in existing complexity and social science to make progress here.Creating cross-disciplinary research collaborations: Multi-agent evaluations require expertise spanning AI capabilities, institutional design, and domain-specific knowledge that rarely exists within single research teams. We need cross-disciplinary coordination to avoid building evaluations that are either technically sophisticated but institutionally naïve, or domain-realistic but methodologically weak.Managing containment and safety considerations: These evaluations necessarily create potentially dangerous capabilities - training models to coordinate deception, form coalitions, and execute multi-step strategies against institutional defenses. If these coordination capabilities leak beyond evaluation environments, they enable distributed attacks. Like other dual-use research, the capabilities must stay contained to controlled testing environments.Exploring containment and safety in controlled environments: Creating potentially dangerous capabilities - training models to coordinate deception, form coalitions, and execute multi-step strategies is inherently dual use. So alongside building these evaluations, we would want to work alongside cybersecurity experts to ensure they stay contained to testing environments.Scaling and Computational Tractability: Many complex system processes only emerge meaningfully at scales and timeframes that push current evaluation capabilities. Testing realistic scenarios with hundreds of agents over extended periods gets expensive quickly, potentially limiting this research.Making educated decisions around many tradeoffs: We could use weaker LLMs to reduce costs, but this raises questions about whether simpler agents can capture the social dynamics we want to study. Similarly, we can reduce the number of agents, or the length of time that we run each episode for. All of these computational and cost requirements mean that the experiments need to be designed very carefully, and tested at a smaller scale before attempting to replicate with potentially thousands of agents.[4]
Conclusion
We think making progress on these types of evaluations is necessary to mitigate some of the larger systemic risks like disempowerment, enfeeblement, or power concentration.
We're genuinely excited about this research direction. The intersection of multi-agent work, complex systems, and safety evaluations opens up entirely new ways to understand both how our societal systems work and how our institutions might need to adapt. Every challenge we've outlined - from getting agents to coordinate effectively to measuring system-level outcomes - represents an opportunity to develop methods that advance both AI safety and social science.
Beyond understanding coordination capabilities, these evaluations can test the effects of governance and policy interventions before implementation. Just like how we can model how defensive mechanisms respond to adversarial pressure, we can create similar environments to evaluate how proposed governance interventions might perform - moving from reactive policy-making to evidence-based anticipatory governance.
If you're working on evaluation methodology, we'd love to collaborate on developing better scaffolding and metrics for multi-agent scenarios. If you understand how specific institutions function under pressure - whether that's democratic processes, scientific peer review, financial markets, information ecosystems, or anything else - we need that domain expertise to build realistic evaluations.
This work is part of our research at Equilibria Network. Get in touch if any of this resonates with your interests. We're excited to hear from you.
Thank you Aaron Halpern for comments and feedback!
- ^
AgentBreeder specifically tested multi-agent scaffolds—the architectural frameworks that coordinate multiple LLMs—rather than general multi-agent interactions. Their evolutionary approach discovered that certain scaffold designs made individual models more vulnerable to adversarial attacks, while others increased robustness.
- ^
We know that control evaluations in AI safety typically measure the ‘control property’ under scheming. We are not making any assumptions about scheming models, but we are still attempting to measure the control property over a larger macro system instead of just one company, or the LAN over which an AI operates.
- ^
Imagine something like Robust Agent-Agnostic Processes (RAAPs) if you are familiar with that framing, but we are saying that instead of just neutral RAAPs, we can have both defensive and adversarial RAAPs which we can evaluate against each other
- ^
If you’re interested in this aspect of things, it might be worth reading - [2409.10568] On the limits of agency in agent-based models
Discuss
