

《科创板日报》9月29日讯(记者 黄心怡)梁文锋最新动作来了,DeepSeek-V3.2-Exp 今天正式发布并开源。
根据DeepSeek官方介绍,这是一个实验性(Experimental)的版本,作为迈向下一代架构的过渡。V3.2-Exp 在 V3.1-Terminus 的基础上引入了DeepSeek稀疏注意力(Sparse Attention)机制,旨在对长文本的训练和推理效率进行探索性的优化和验证。
对于此次模型更新,中信建投TMT行业首席分析师武超则评价,DeepSeek-V3.2-Exp“易用性再次大幅提升”。
值得一提的是,除了英伟达CUDA版本外,DeepSeek还开源了TileLang版本GPU算子。
目前,官方App、网页端、小程序均已同步更新为DeepSeek-V3.2-Exp,同时API大幅度降价。
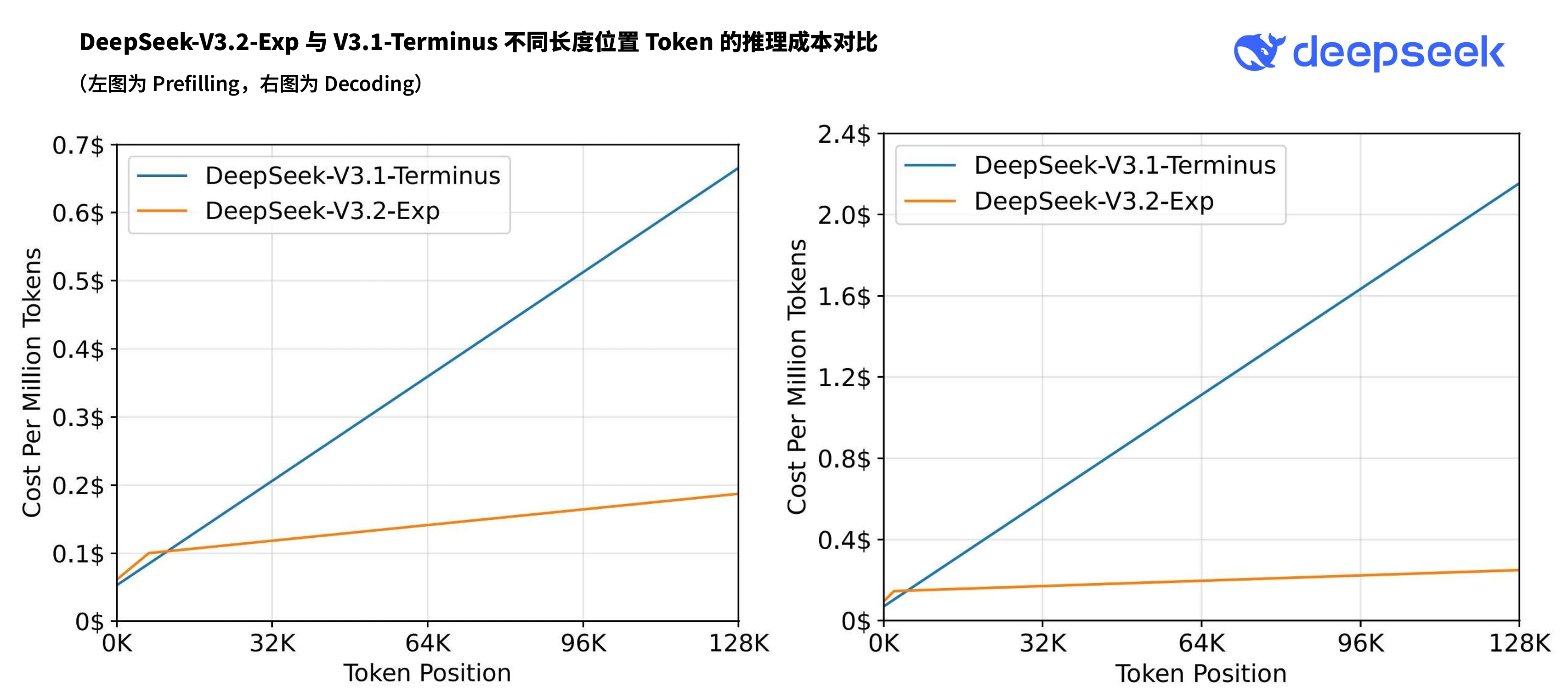
在缓存命中的情况下,输入价格由0.5元/百万token降低为0.2元。在缓存未命中的情况下,输入价格由4元/百万token减低为2元。输出价格则从12元/百万token大幅降低为3元。

在新的价格政策下,开发者调用DeepSeek API的成本将降低50%以上。
据介绍,该实验版本代表了DeepSeek对更高效的transformer架构的研究,特别注重提高处理扩展文本序列时的计算效率。
DeepSeek稀疏注意力架构(DSA)首次实现了细粒度(fine-grained)稀疏注意力,在保持几乎相同的模型输出质量的同时,显著提高了长文本训练和推理效率。
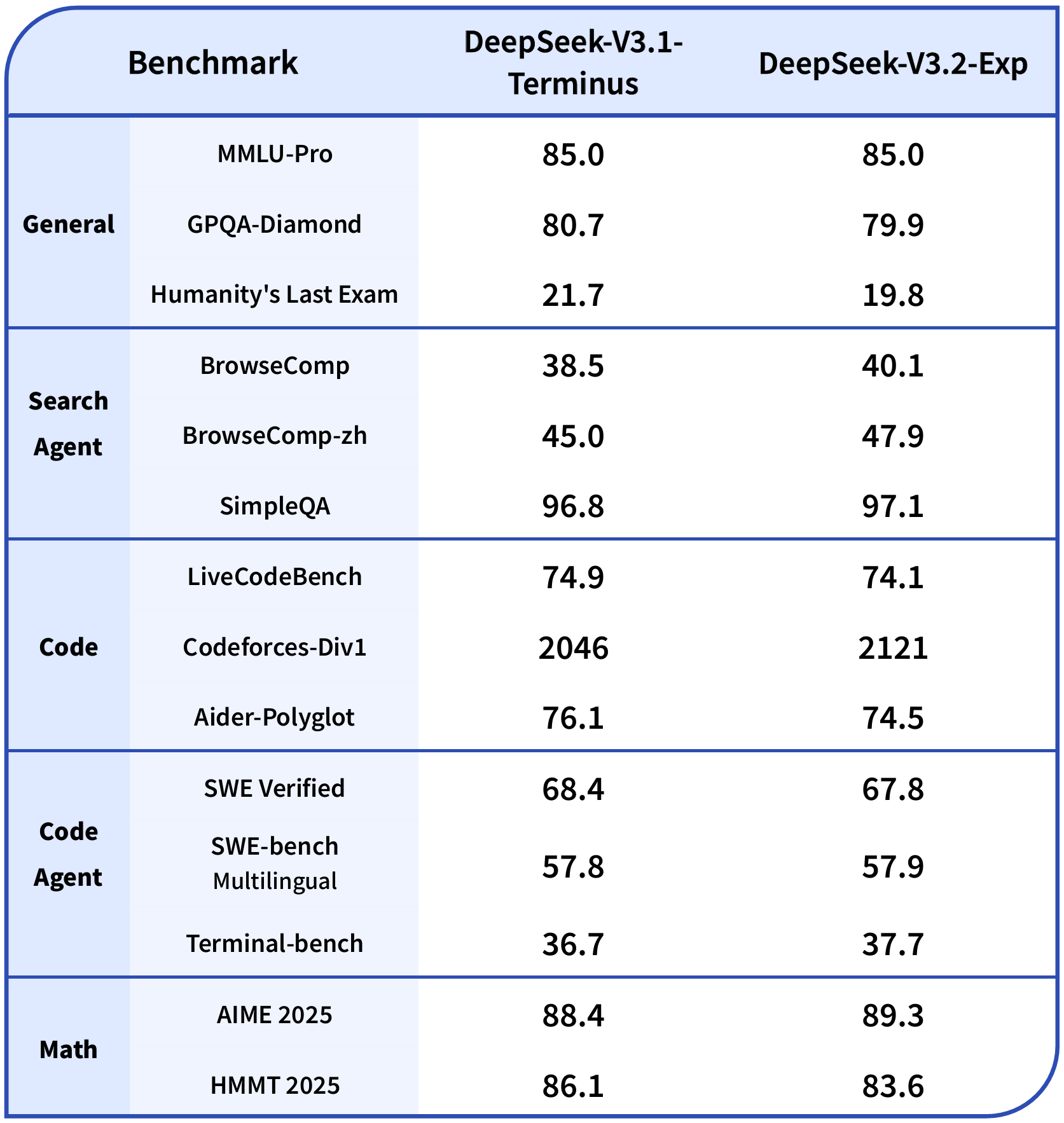
为了评估引入稀疏注意力机制的影响,DeepSeek方面特意将DeepSeek-V3.2-Exp的训练配置与V3.1-Terminus进行了对齐。在各个领域的公开基准测试中,DeepSeek-V3.2-Exp的表现与V3.1-Terminus相当。
DeepSeek方面称,在新模型的研究过程中,需要设计和实现很多新的GPU算子。
“我们使用高级语言TileLang进行快速原型开发,以支持更深入的探索。在最后阶段,以TileLang作为精度基线,逐步使用底层语言实现更高效的版本。因此,本次开源的主要算子包含TileLang与CUDA两种版本。我们建议社区在进行研究性实验时,使用基于TileLang的版本以方便调试和快速迭代。”
《科创板日报》了解到,TileLang编程语言是由北京大学计算机学院副研究员杨智团队主导开发的开源AI算子编程语言。在华为全联接大会上,该团队核心成员董宇骐曾介绍,TileLang实现了FlashAttention算子开发,代码量从500+行减少至80行,并保持了与官方版本持平的性能。
除了DeepSeek外,近期阿里通义千问、智谱也都在推进大模型的迭代升级。
在2025云栖大会现场,阿里云接连发布了七款大模型技术产品,覆盖语言、语音、视觉、多模态、代码等模型领域。其中包括了阿里旗舰模型Qwen3-Max正式发布,预训练数据量达36T,总参数超过万亿,在Coding编程能力和Agent工具调用能力上有较大提升。
智谱新模型GLM-4.6将于近日发布,目前已可通过API接口调用。
月之暗面Kimi则发布Agent模式“OK Computer”并开启灰度测试。据官方介绍,“OK Computer”延续“模型即Agent”理念,通过端到端训练Kimi K2模型,进一步提升智能体及工具调用能力。
