
一图看透全球大模型!新智元十周年钜献,2025 ASI前沿趋势报告37页首发
在大型语言模型的优化中,业界通常认为计算量与模型性能正相关。
然而,杜克大学陈怡然教授团队的一项最新研究DPad,却揭示了一个反直觉的现象:对于扩散大语言模型(dLLMs),通过一种「先验丢弃」策略,主动减少其计算量,不仅能带来高达61倍的推理加速,还能意外地增强模型语境学习的能力。
这一发现源于对dLLM内部一种「中奖彩票」(Lottery Ticket)现象的洞察。模型在生成文本时,其庞大的注意力网络中似乎隐藏着一个极度稀疏但高效的「中奖组合」。
DPad的核心贡献就在于,它无需训练,便能在推理时动态地、近乎零成本地找出这个组合,从而实现速度与精度的双重飞跃。

论文地址:https://arxiv.org/abs/2508.14148
代码地址:https://github.com/Crys-Chen/DPad
论文作者团队来自杜克大学CEI中心,由实习生陈欣骅、黄思韬及郭聪博士共同完成,指导教师为李海教授、陈怡然教授,其他作者还包括魏迟越、何银涛、张健一。

团队发现,dLLM的独特之处在于双向注意力,这使得它在生成文本时,会关注所有待生成的后文词元(Suffix Token),并将它们用作规划全文的「草稿纸」。
「草稿纸」机制使得模型能在Transformer的第n层往后文写入信息,然后在第n+1层读取后文信息,用于辅助前文的解码。
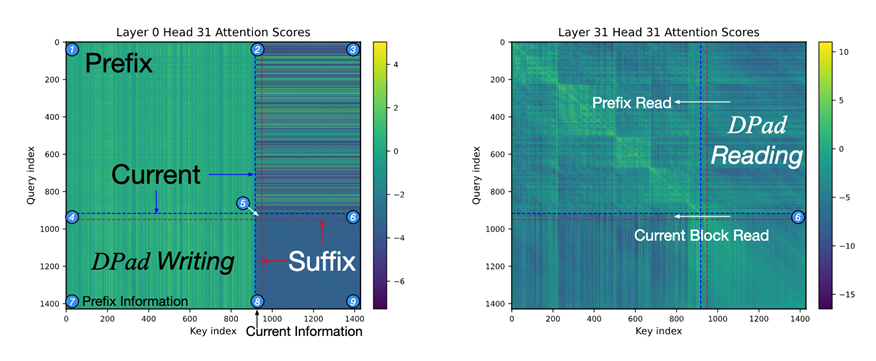
图1 「草稿纸机制」示意图,左下角为前文往后文写入信息,右上角为前文从后文读取信息
前文提到,dLLM在解码前文时,会将大段的后文词元作为草稿纸。
团队进一步分析了模型对后文词元的注意力分数,发现模型对后文词元的注意力随着距离快速衰减,但还是会有一些零星「尖峰」。
说明后文词元有强烈的稀疏性,仅存在少量比较重要的词元。
这个发现完美契合了深度学习中著名的「彩票假说」(Lottery Ticket Hypothesis)。
受此启发,团队提出了「扩散彩票假说」(Diffusion Lottery Tickets Hypothesis):在dLLM的后缀token中,存在一个稀疏的「中奖彩票」子集,只要能「抽中」它们,就能在大幅降低计算成本的同时,达到甚至超越完整模型的性能。
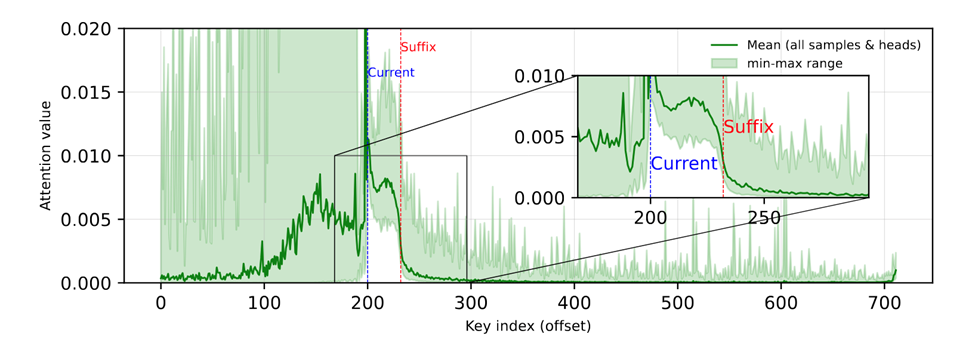
图2 当前块对后缀token的注意力分数图。可以看到,后文token存在部分尖峰
这也是正常词元剪枝(Token Pruning)的逻辑——统计注意力分数,确定不重要的词元,然后将其删除。
然而,DPad团队并不满足于此,他们进行了一项颠覆性的实验:强行删除那些距离很远、但注意力得分很高的「尖峰」词元。
结果出乎意料——模型的准确率几乎毫无损失!
不同于自回归模型,dLLM展现出了惊人的「自愈能力」,仿佛后文词元的信息可以自由流动,当一个关键路径被阻断时,注意力会立刻转移到邻近的词元上,形成新的信息通路。
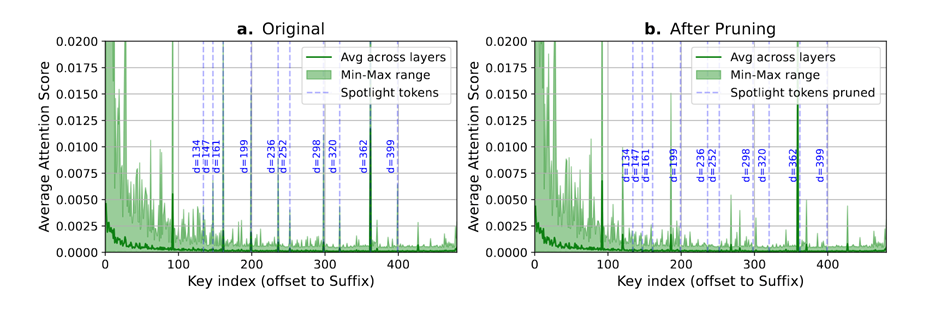
图3 「注意力迁移」现象,删除「关键词元」后,模型的注意力尖峰转移到附近词元
这个「注意力迁移」现象有力地证明:dLLM的全局规划能力并非依赖于某些特定位置的「明星词元」,而更像是一种分布式的、可替代的冗余系统。
研究人员并没有必要花费大量的计算去确定「关键词元」,直接先验地剪枝,最终保有一套系统就行。

基于上述发现,DPad提出了一套全新的「事前筛选」逻辑。
不再让模型「全力计算后才发现浪费」,而是在计算开始前就果断地丢弃掉绝大部分冗余部分。
实现该目标的核心是两大策略:
1. 滑动窗口 (Sliding Window):将模型的「目光」强制聚焦在当前解码位置附近的一个固定长度窗口内,从根本上杜绝了对遥远未来的无效关注。
这好比作家在写当前章节时,只详细规划紧邻的几章,而不是构思最后一章的具体措辞。
2. 距离衰减丢弃 (Distance-decay Dropout):在窗口内部,也并非一视同仁。DPad采用一种随距离递减的概率来保留词元,即「越近的草稿越详细,越远的草稿越潦草」。
这两招简单而有效,共同构成了一个动态的「中奖彩票」筛选器,让模型在每一解码步都只使用一个极度稀疏但高效的注意力子集。
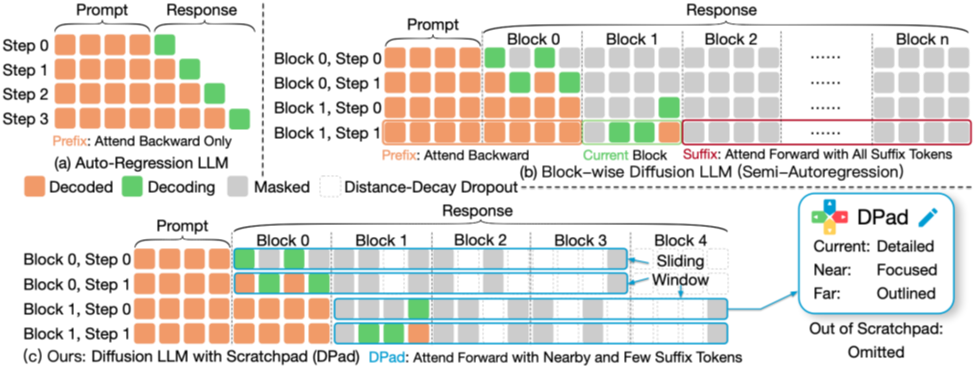
图4 (a)自回归模型;(b) 传统dLLM,需要关注所有后缀token;(c) DPad,仅关注附近少数经过筛选的后缀token
DPad带来的并非传统意义上「牺牲精度换速度」的权衡,而是一场双赢。

在常规评测中,「灵活匹配」(Flexible-Match)只要求答案数值正确,而「严格匹配」(Strict-Match)则要求模型严格遵循范例的格式与推理步骤,是衡量模型「语境学习能力」的关键指标。

图5 「灵活匹配」得分和「严格匹配」得分。原始模型(左)没能按照「####」的格式输出答案,没能通过「严格匹配」;使用DPad(右)后模型成功「记得」按「####」输出答案,通过「严格匹配」
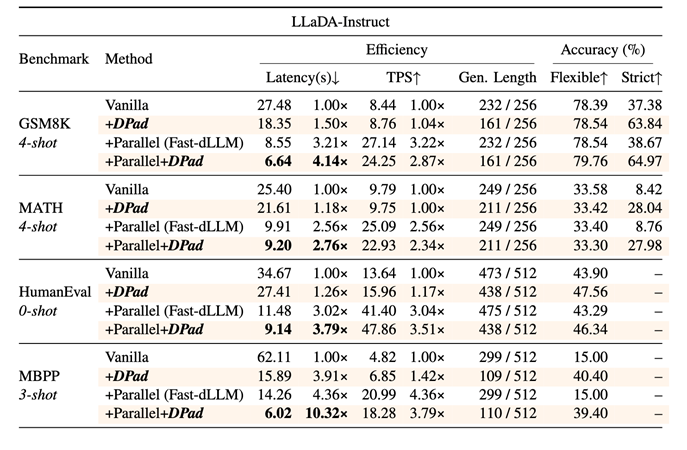
图6 DPad在LLaDA-Instruct上的效果
实验显示,原始的LLaDA-Instruct模型在GSM8K任务上严格匹配率仅为37.38%,因为它虽然能算对答案,却无法很好地复刻范例格式。
而应用DPad后,通过滤除大量无关后文词元的干扰,模型能更专注于学习prompt中的有效信息,严格匹配率跃升至63.84%。
这表明,DPad让模型变得更「专注」,更能领会并执行复杂指令。
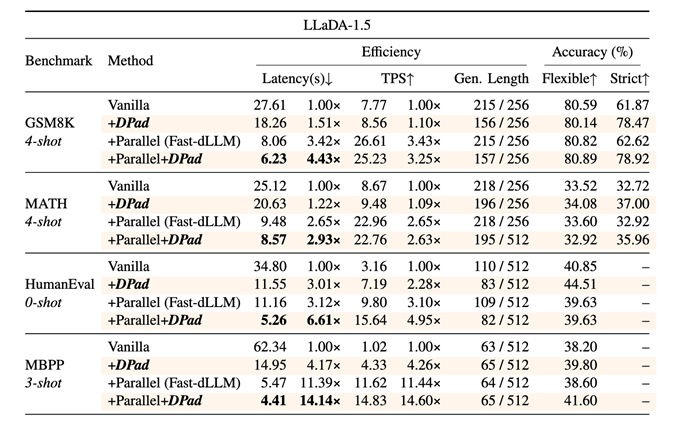
图7 DPad在LLaDA-1.5上的效果
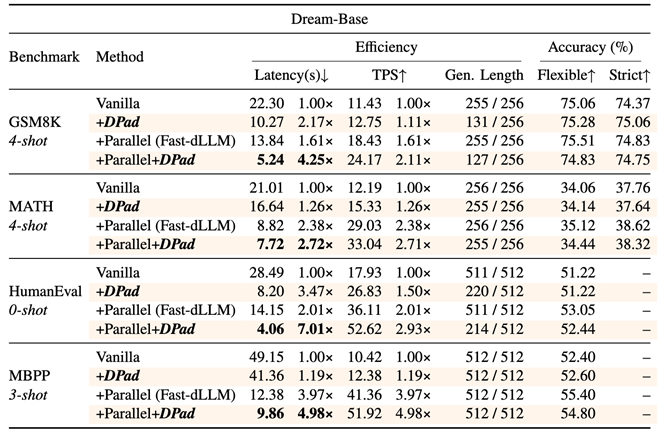
图8 DPad在Dream-Base上的效果

当模型不再需要为海量冗余信息耗费算力后,其推理速度得到了指数级解放。在短示例、长文本生成场景下,DPad的优势被发挥到极致:

图9 在GSM8K(1024 tokens, 1-shot)任务上,LLaDA-1.5+Fast-dLLM+DPad实现了61.39倍的加速
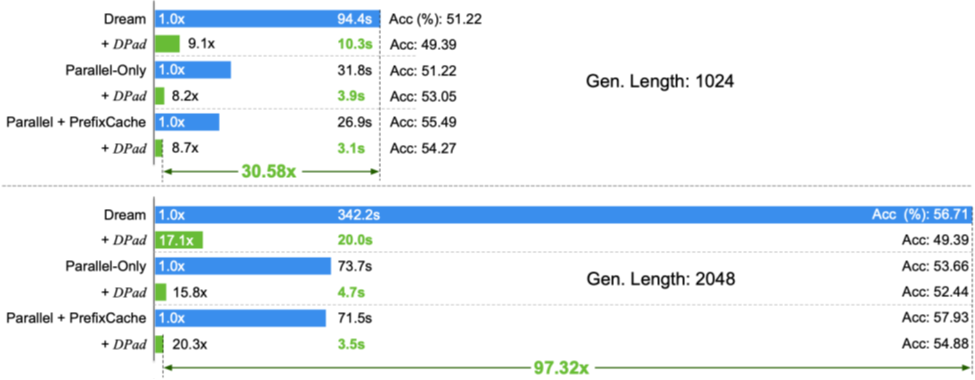
图10 在HumanEval(2048 tokens, 0-shot)任务上,Dream-Base+Fast-dLLM+DPad实现了97.32倍的加速
在LLaDA-1.5模型(1024 词元输出)上,DPad结合并行解码等优化后,实现了61.39倍的综合加速。
在Dream模型(2048 词元输出)上,这一数字更是达到了97.32倍。

DPad证明,对于dLLM而言,「少即是多」。
它通过一种巧妙的、免训练的「事前筛选」机制,揭示并利用了dLLM中潜在的稀疏结构。
其带来的不仅是接近两个数量级的推理加速,更有对模型深层能力的意外增强。
这项工作为我们开辟了一条全新的优化思路:未来的模型设计或许可以更大胆地探究稀疏性,让dLLM在「化繁为简」的道路上走得更远。


内容中包含的图片若涉及版权问题,请及时与我们联系删除
