
Published on September 26, 2025 4:30 PM GMT
Some colleagues and I just released our paper, “Policy Options for Preserving Chain of Thought Monitorability.” It is intended for a policy audience, so I will give a LW-specific gloss on it here.
As argued in Korbak, Balesni et al. recently, there are several reasons to expect CoT will become less monitorable over time, or disappear altogether. This would be bad, given CoT monitoring is one of the few tools we currently have for somewhat effective AI control.
In the paper, we focus on novel architectures that don’t use CoT at all (e.g. ‘neuralese’ from AI2027 where full latent space vectors are passed back to the first layer of the transformer, rather than just one token). We think this is the most concerning route, since model latents are very hard to interpret (so far).
But as we were finalizing our paper, OpenAI and Apollo’s work on scheming detection came out, which shows some CoTs from o3 that are pretty hard to decipher:[1]

So maybe we were too optimistic, and CoT monitoring will become unviable even without neuralese, just with scaling up RL on reasoning models. We are interested in takes on this, and whether there are (low-ish cost) ways to train reasoning models that still produce more legible CoTs. As I understand, DeepSeek went to significant efforts to make its r1 model have a more readable CoT, which suggests it is possible. Another idea I have heard is that you could paraphrase the model’s CoT to itself in training, such that it doesn’t learn to use inscrutable phrases like “glean disclaim disclaim synergy customizing illusions”.
But, despite the worrying signs on CoT readability and monitorability, we tentatively think this is still worth fighting for. In particular, we discuss three coordination mechanisms to solve the collective action problem where no company wants to be the only one to maintain monitorable CoT if it imposes an efficiency penalty:
- Coordinated voluntary commitments: If the costs of doing so are relatively low, companies could just coordinate to all keep CoT monitorable.Domestic AI policy: within any one jurisdiction, notably US state or federal levels, the government could just regulate that all sufficiently advanced models need to have a monitorable CoT. Governments could also incentivize AI developers in other ways, such as through procurement requirements (‘we’ll only buy your AI if its CoT is above some level of monitorability.’) International agreements: If governments are worried frontier AI R&D will move overseas because of CoT regulations, or that their domestic industry will be left behind, we might need an international agreement. This would be difficult, but not impossible if the US and China agree that CoT monitoring is key for safety, and in their mutual interest to preserve.
To decide which of these options is needed, we consider the relative size of the societal benefits and the ‘monitorability tax’ companies pay by using (putatively less efficient) monitorable models.

A key question determining the feasibility of policy solutions is, “How big is the monitorability tax?”. We don’t know, and nor can anyone else, until/unless neuralese or other non-monitorable models exceed SOTA performance from CoT models. But we did ask a miscellaneous sample of more technical AI safety people about this, and the median estimate of the median person was a 10x efficiency gain from neuralese at the time of AGI, with huge variance. The exact question wording is here.
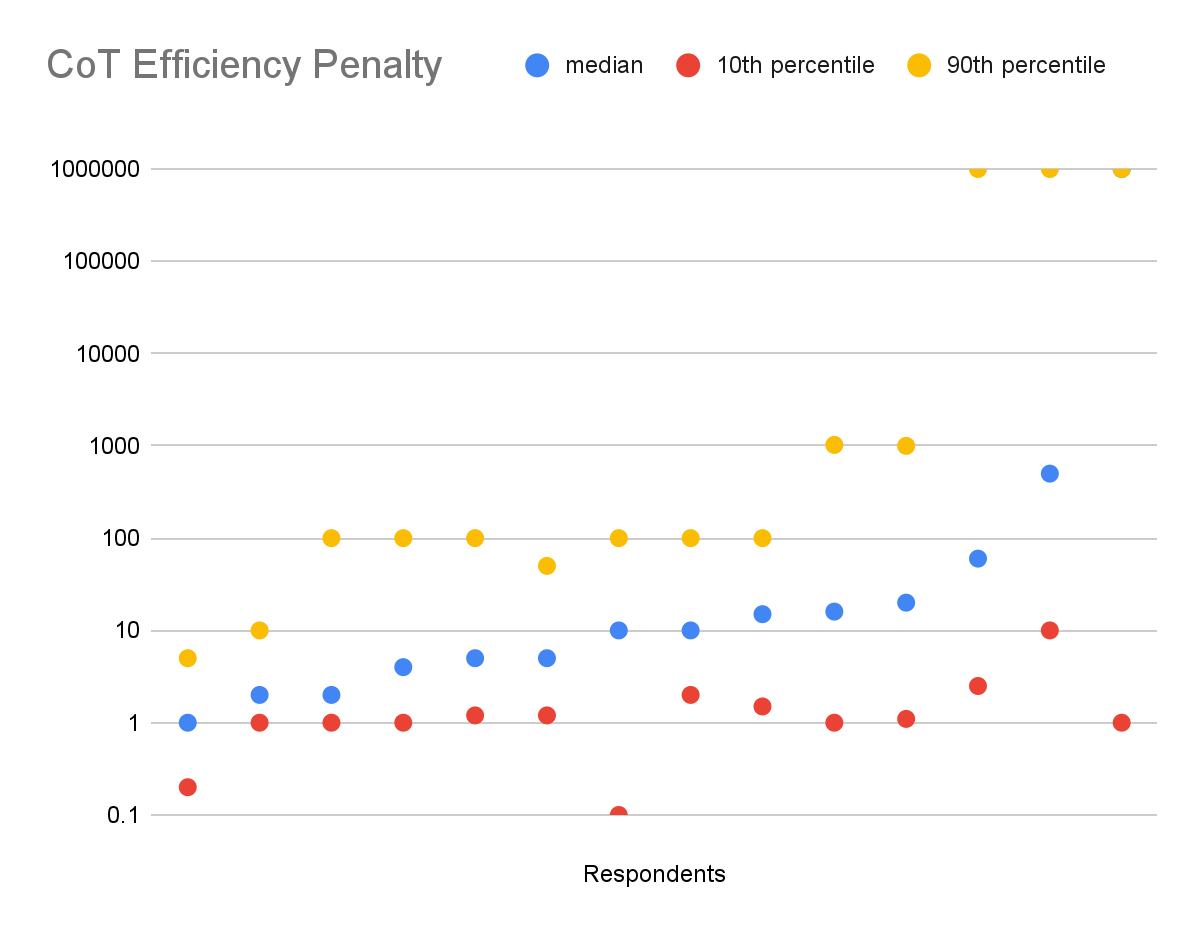
So I’m not sure if we will be able to coordinate to preserve CoT monitorability in the medium/long-term: if the efficiency penalty is too high (maybe more than 3x or so?) neuralese will probably just win out. But should we preserve CoT in the short term? This could go either way:
- Yes. This will buy us a few more years of insight into how AIs are thinking (bracketing the fact that CoT is only partly faithful). This could be useful in various ways, e.g. because the better-understood AIs could be studied, used for high-stakes safety research, or put into control setups.No. If we keep CoT monitorable briefly with coordination, but then the dam breaks and there is a gold rush of applying stacks of compute to newly-allowed architectures, this could cause a very dangerous sudden jump in capabilities.
I am pretty undecided - my guess is CoT is still worth striving to preserve, but the backfire risk does seem real. Overall, I am still keen for more people to work on policy options to preserve CoT monitorability, but it seems like less of a clear win and low-hanging fruit than it did when we started the project.
Here is what I would be particularly keen to see technical researchers do:
- Gain more clarity on how big the efficiency gains from neuralese are likely to be, and thus the size of the monitorability tax and the feasibility of coordination measures.Work on interpreting model latents, in case CoT does get superseded with neuralese.Try to lower the monitorability tax by making it cheaper and easier to train reasoning models that still have nice, readable CoTs, without a capability penalty.
- ^
And even before that there had been signs of CoTs of frontier models becoming less readable.
Discuss
