

We are proud to announce the updated QRWKV-72B1 and 32B.
Both models are available on huggingface and featherless.ai
32B | Hugging Face Link | Featherless AI Link
72B | Hugging Face Link | Featherless AI Link
The largest model to date - that is not based on the transformer attention architecture.
Surpassing existing transformer models in several benchmarks, while following right behind in others.
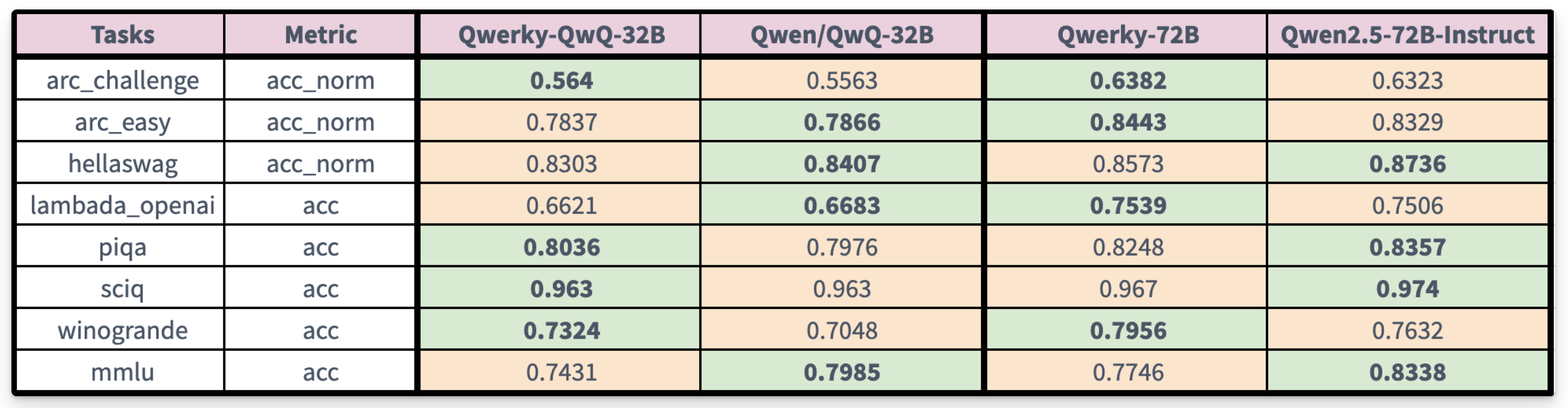
This builds on our previous experiments in converting the QRWKV6, where we converted the previous Qwen 2.5 32B model to RWKV. And the previous 72B preview.
Which we applied instead for the Qwen-QwQ-32B model and the Qwen-72B model respectively.
But lets take a step back at what this means …
We now have a model far surpassing
GPT-3.5 turbo, without QKV attention
While slowly closing in on GPT-4O-mini
With lower inference cost, param size, and better performance.
In 2024: When we proposed scaling up RWKV to replace attention.
Many believed transformer attention, is the only viable path
to GPT 3.5 or better intelligence. Today this is disproven false.
We need no super cluster - only a single server.

Because we were keeping most of the feed forward network layer the same.
We can perform the conversion, (barely) within a single server of 8 MI300 GPU’s
Requiring the full 192GB VRAM allocation per GPU
How the conversion is done: A summary
While more details will be revealed in an upcoming paper. The core idea is similar to the previous QRWKV6 conversion , but this time we apply it to the Qwen-72B and QwQ-32B models
At a high level, you take an existing transformer model
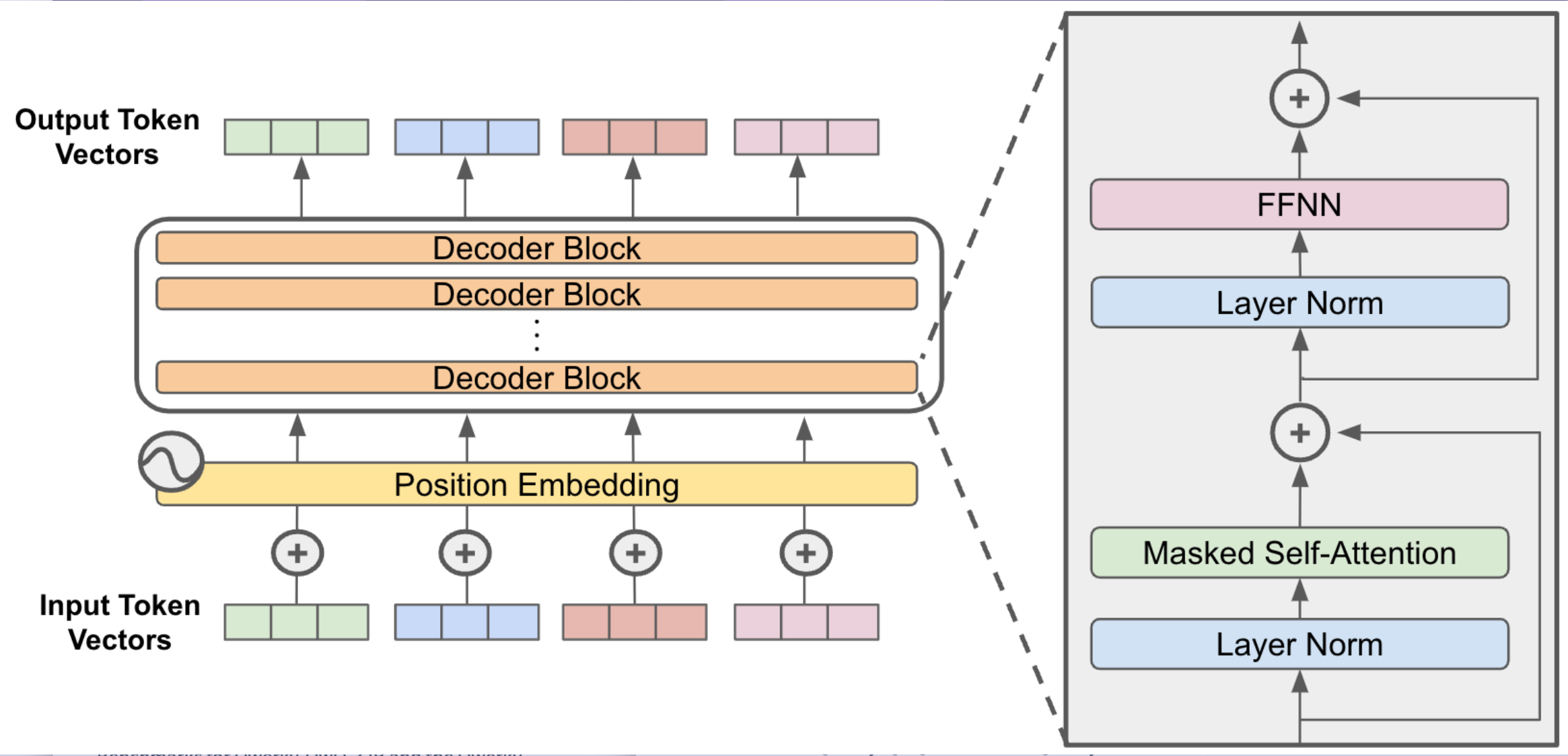
Freeze all the weights, delete the attention layer, replace it with RWKV, and train it through multiple stages
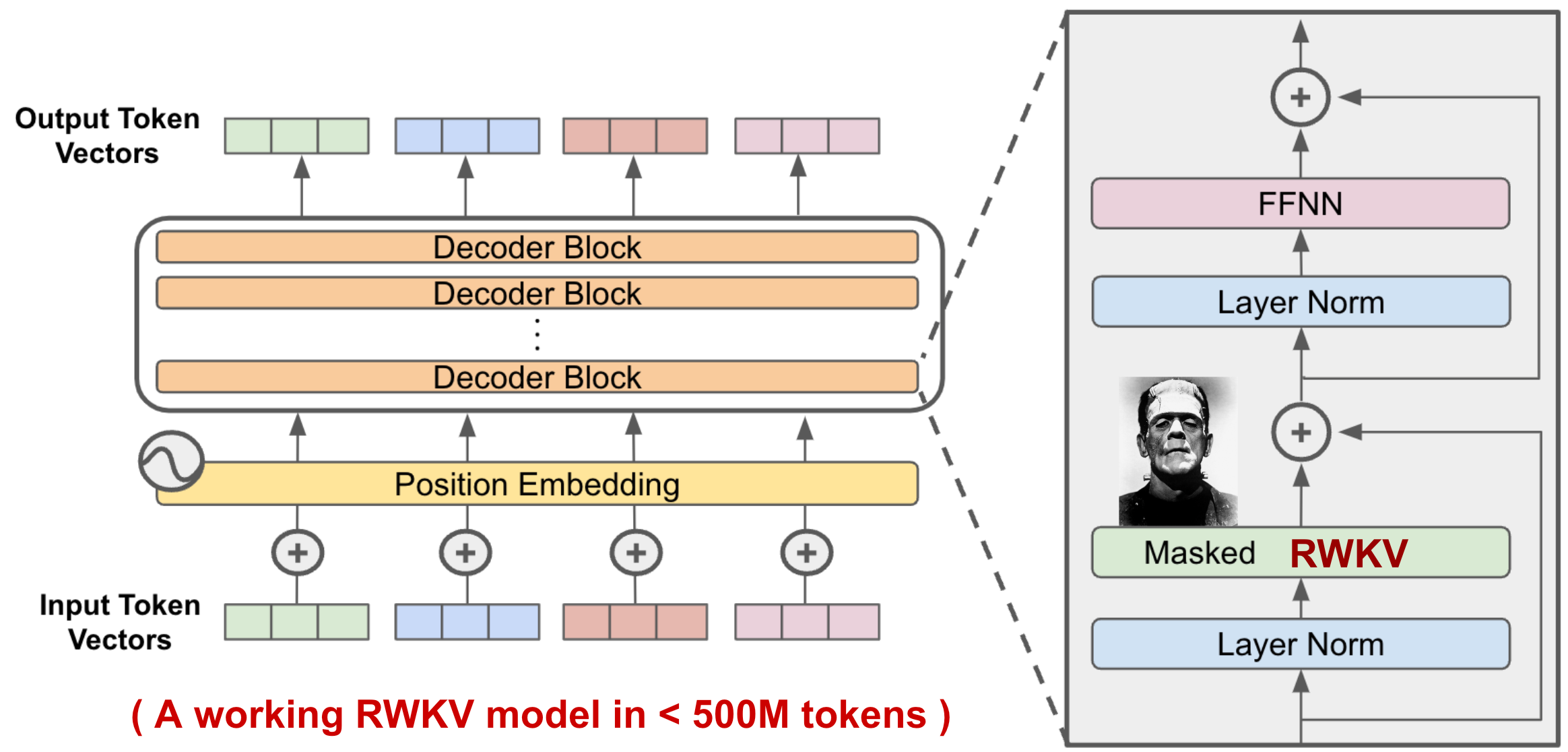
All while referencing the original model logits as a “teacher model”
More specifically it would be the following
Train the RWKV layer individually, referencing the individual teacher blocks
Train the RWKV layer, with the whole model, training on teacher logits
At this point the model is “usable” but has much more to improve on
Train all the layers (both FFNN and RWKV), on teacher logits
Train all the layers with longer context length
Unfortunately, due to the limitation of VRAM, our training was limited to 8k context length. However we view this as a resource constraint, and not a method constraint.
Implication:
AI knowledge, is not in attention, but FFN
Due to the limited token training of 200-500M, of the converted layers. We do not believe that the newly trained RWKV layers, is sufficiently trained for “knowledge/intelligence” at this level.
In other words, the vast majority of an AI model knowledge, is not in the attention but the matrix multiplication FFN (Feed-Forward-Network) layer.
It would be more accurate, to view the Attention mechanisms, be it transformer based, or RWKV. As a means of guiding the model to focus on “what the model thinks” about in the FFN layer.
Benefits: Ideal for large scale application
Additionally, with the shift towards inference-time-computing.
Linear architectures represents a dramatic reduction in both compute and vram requirement cost. Allowing us to scale hundreds to thousand requests per GPU.

We can now rapidly iterate new RWKV architectures on <100B scales
By dramatically reducing the compute requirement for scaling and testing a new RWKV attention architecture. To a small number of GPU’s
We will be able to test, iterate, and validate newer architecture changes faster, taking experiments what previously took weeks (or even months), to days.

Historically, the RWKV group has been averaging 4 major versions across 2 years. With improvement to both model architecture accuracy and memories at every step.
A trend which we plan to accelerate moving forward.
As we work on our roadmap to Personalized AI and eventually Personalized AGI, which you can see more in our following article …

This model was originally published as Qwerky-72B. However, due to confusion with another similar naming company/model, we have been requested to avoid using the Qwerky name, so we have renamed our models to QRWKV-72B
