
In real-world video and image analysis, businesses often face the challenge of detecting objects that weren’t part of a model’s original training set. This becomes especially difficult in dynamic environments where new, unknown, or user-defined objects frequently appear. For example, media publishers might want to track emerging brands or products in user-generated content; advertisers need to analyze product appearances in influencer videos despite visual variations; retail providers aim to support flexible, descriptive search; self-driving cars must identify unexpected road debris; and manufacturing systems need to catch novel or subtle defects without prior labeling.In all these cases, traditional closed-set object detection (CSOD) models—which only recognize a fixed list of predefined categories—fail to deliver. They either misclassify the unknown objects or ignore them entirely, limiting their usefulness for real-world applications.Open-set object detection (OSOD) is an approach that enables models to detect both known and previously unseen objects, including those not encountered during training. It supports flexible input prompts, ranging from specific object names to open-ended descriptions, and can adapt to user-defined targets in real time without requiring retraining. By combining visual recognition with semantic understanding—often through vision-language models—OSOD helps users query the system broadly, even if it’s unfamiliar, ambiguous, or entirely new.
In this post, we explore how Amazon Bedrock Data Automation uses OSOD to enhance video understanding.
Amazon Bedrock Data Automation and video blueprints with OSOD
Amazon Bedrock Data Automation is a cloud-based service that extracts insights from unstructured content like documents, images, video and audio. Specifically, for video content, Amazon Bedrock Data Automation supports functionalities such as chapter segmentation, frame-level text detection, chapter-level classification Interactive Advertising Bureau (IAB) taxonomies, and frame-level OSOD. For more information about Amazon Bedrock Data Automation, see Automate video insights for contextual advertising using Amazon Bedrock Data Automation.
Amazon Bedrock Data Automation video blueprints support OSOD on the frame level. You can input a video along with a text prompt specifying the desired objects to detect. For each frame, the model outputs a dictionary containing bounding boxes in XYWH format (the x and y coordinates of the top-left corner, followed by the width and height of the box), along with corresponding labels and confidence scores. You can further customize the output based on their needs—for instance, filtering by high-confidence detections when precision is prioritized.
The input text is highly flexible, so you can define dynamic fields in the Amazon Bedrock Data Automation video blueprints powered by OSOD.
Example use cases
In this section, we explore some examples of different use cases for Amazon Bedrock Data Automation video blueprints using OSOD. The following table summarizes the functionality of this feature.
Ads analysis
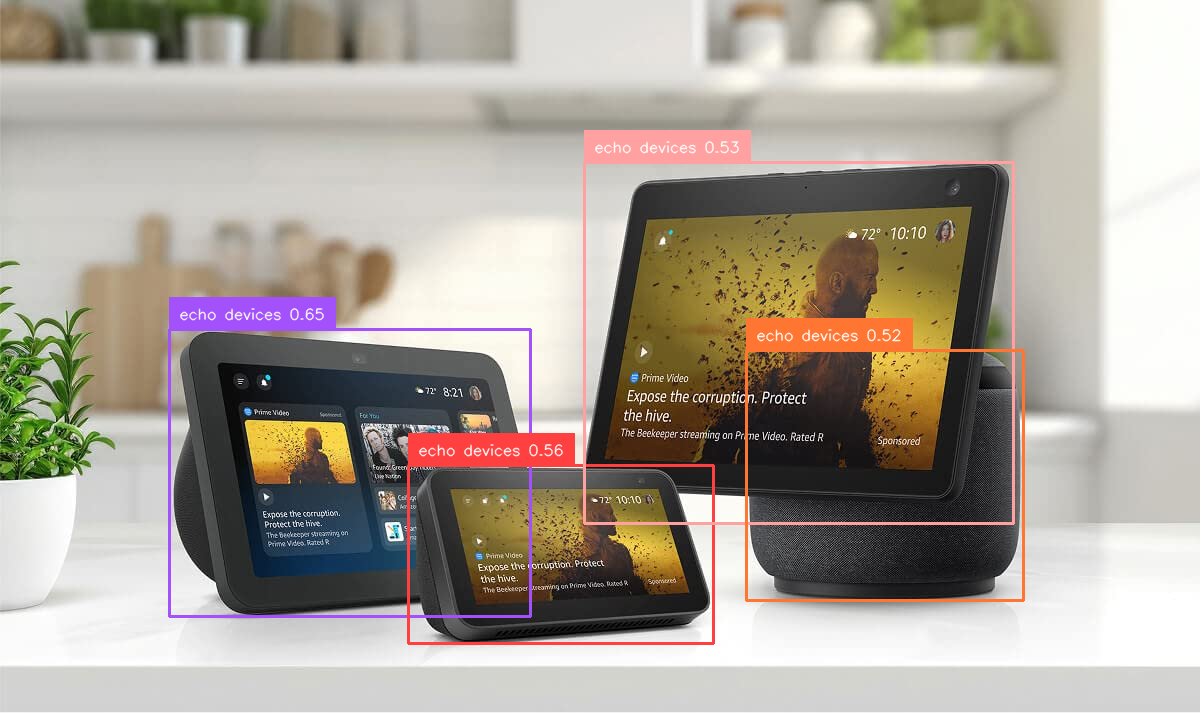
Advertisers can use this feature to compare the effectiveness of various ad placement strategies across different locations and conduct A/B testing to identify the most optimal advertising approach. For example, the following image is the output in response to the prompt “Detect the locations of echo devices.”
Smart resizing
By detecting key elements in the video, you can choose appropriate resizing strategies for devices with different resolutions and aspect ratios, making sure important visual information is preserved. For example, the following image is the output in response to the prompt “Detect the key elements in the video.”

Surveillance with intelligent monitoring
In home security systems, producers or users can take advantage of the model’s high-level understanding and localization capabilities to maintain safety, without the need to manually enumerate all possible scenarios. For example, the following image is the output in response to the prompt “Check dangerous elements in the video.”

Custom labels
You can define your own labels and search through videos to retrieve specific, desired results. For example, the following image is the output in response to the prompt “Detect the white car with red wheels in the video.”

Image and video editing
With flexible text-based object detection, you can accurately remove or replace objects in photo editing software, minimizing the need for imprecise, hand-drawn masks that often require multiple attempts to achieve the desired result. For example, the following image is the output in response to the prompt “Detect the people riding motorcycles in the video.”
Sample video blueprint input and output
The following example demonstrates how to define an Amazon Bedrock Data Automation video blueprint to detect visually prominent objects at the chapter level, with sample output including objects and their bounding boxes.
The following code is our example blueprint schema:
The following code is out example video custom output:
For the full example, refer to the following GitHub repo.
Conclusion
The OSOD capability within Amazon Bedrock Data Automation significantly enhances the ability to extract actionable insights from video content. By combining flexible text-driven queries with frame-level object localization, OSOD helps users across industries implement intelligent video analysis workflows—ranging from targeted ad evaluation and security monitoring to custom object tracking. Integrated seamlessly into the broader suite of video analysis tools available in Amazon Bedrock Data Automation, OSOD not only streamlines content understanding but also help reduce the need for manual intervention and rigid pre-defined schemas, making it a powerful asset for scalable, real-world applications.
To learn more about Amazon Bedrock Data Automation video and audio analysis, see New Amazon Bedrock Data Automation capabilities streamline video and audio analysis.
About the authors
 Dongsheng An is an Applied Scientist at AWS AI, specializing in face recognition, open-set object detection, and vision-language models. He received his Ph.D. in Computer Science from Stony Brook University, focusing on optimal transport and generative modeling.
Dongsheng An is an Applied Scientist at AWS AI, specializing in face recognition, open-set object detection, and vision-language models. He received his Ph.D. in Computer Science from Stony Brook University, focusing on optimal transport and generative modeling.  Lana Zhang is a Senior Solutions Architect in the AWS World Wide Specialist Organization AI Services team, specializing in AI and generative AI with a focus on use cases including content moderation and media analysis. She’s dedicated to promoting AWS AI and generative AI solutions, demonstrating how generative AI can transform classic use cases by adding business value. She assists customers in transforming their business solutions across diverse industries, including social media, gaming, ecommerce, media, advertising, and marketing.
Lana Zhang is a Senior Solutions Architect in the AWS World Wide Specialist Organization AI Services team, specializing in AI and generative AI with a focus on use cases including content moderation and media analysis. She’s dedicated to promoting AWS AI and generative AI solutions, demonstrating how generative AI can transform classic use cases by adding business value. She assists customers in transforming their business solutions across diverse industries, including social media, gaming, ecommerce, media, advertising, and marketing.  Raj Jayaraman is a Senior Generative AI Solutions Architect at AWS, bringing over a decade of experience in helping customers extract valuable insights from data. Specializing in AWS AI and generative AI solutions, Raj’s expertise lies in transforming business solutions through the strategic application of AWS’s AI capabilities, ensuring customers can harness the full potential of generative AI in their unique contexts. With a strong background in guiding customers across industries in adopting AWS Analytics and Business Intelligence services, Raj now focuses on assisting organizations in their generative AI journey—from initial demonstrations to proof of concepts and ultimately to production implementations.
Raj Jayaraman is a Senior Generative AI Solutions Architect at AWS, bringing over a decade of experience in helping customers extract valuable insights from data. Specializing in AWS AI and generative AI solutions, Raj’s expertise lies in transforming business solutions through the strategic application of AWS’s AI capabilities, ensuring customers can harness the full potential of generative AI in their unique contexts. With a strong background in guiding customers across industries in adopting AWS Analytics and Business Intelligence services, Raj now focuses on assisting organizations in their generative AI journey—from initial demonstrations to proof of concepts and ultimately to production implementations.
