
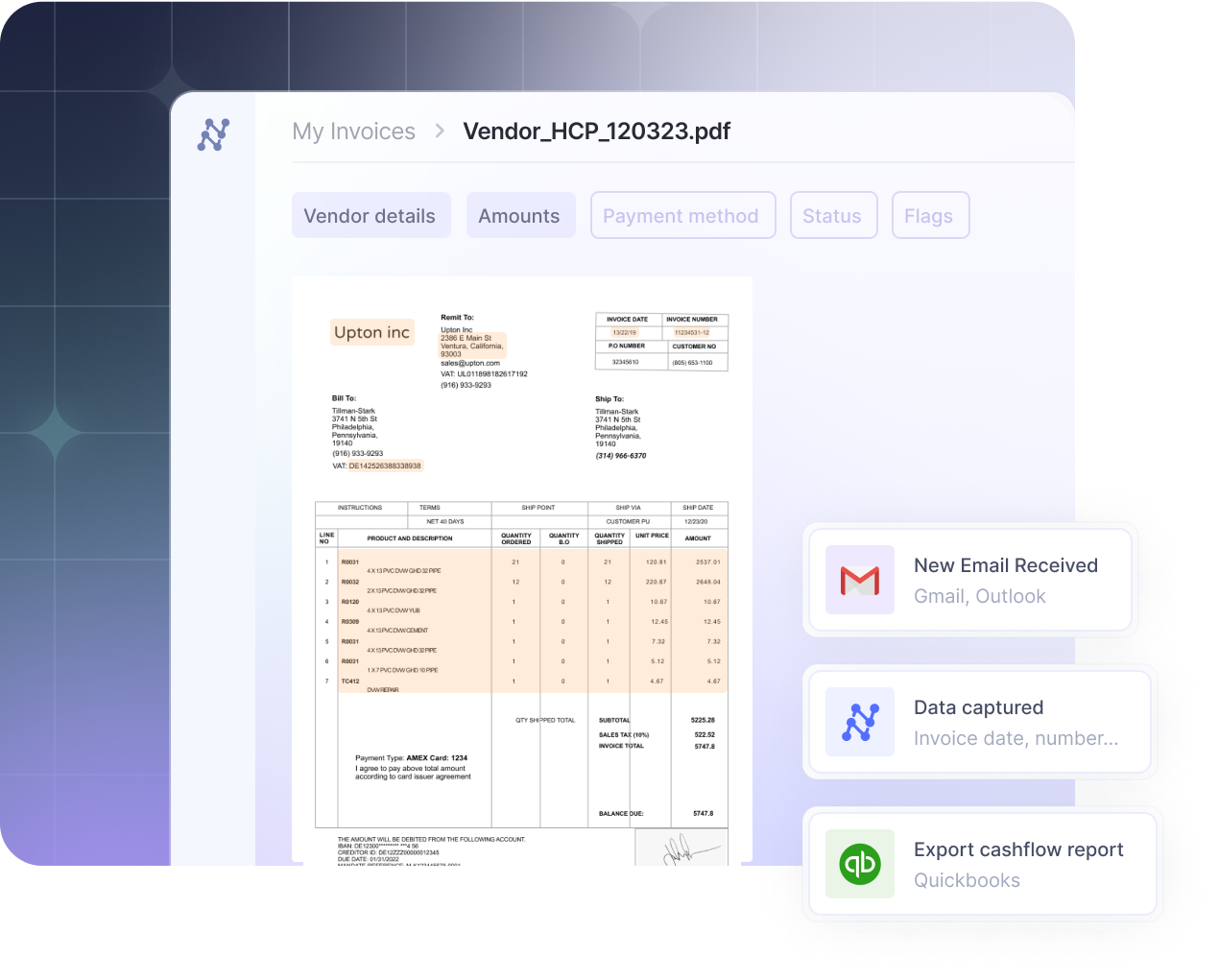
Your leadership team is talking about Generative AI. Your CIO has an AI-readiness initiative. The mandate from the top is clear: automate, innovate, and find a competitive edge with artificial intelligence.
But you know the truth.
The critical data needed to power these AI initiatives is trapped in a 15-page scanned PDF from a new supplier, a blurry photo of a bill of lading, and an email inbox overflowing with purchase orders. The C-suite's vision of an AI-powered future is colliding with the ground truth of document processing—and you're caught in the middle.
This isn't a unique problem. A stunning 77% of organizations admit their data is not ready for AI, primarily because it's locked in this exact kind of information chaos. The biggest hurdle to AI isn't the accuracy of the model; it's the input.
This article isn't about AI hype. It's about the foundational work of data capture that makes it all possible. We'll break down how to solve the input problem, moving from the brittle, template-based tools of the past to an intelligent system that delivers clean, structured, AI-ready data with 95%+ accuracy.
The foundation: Defining the what and why of data capture
To solve a problem, we must first define it correctly. The challenge of managing documents has evolved far beyond simple paperwork. It is a strategic data problem that directly impacts efficiency, cost, and a company's ability to innovate.
Core definitions and terminology
Data capture is the process of extracting information from unstructured or semi-structured sources and converting it into a structured, machine-readable format.
To be precise, data exists in three primary forms:
- Unstructured data: Information without a predefined data model, such as the text in an email, the body of a legal contract, or an image.Semi-structured data: Loosely organized data that contains tags or markers to separate semantic elements but does not fit a rigid database model. Invoices and purchase orders are classic examples.Structured data: Highly organized data that fits neatly into a tabular format, like a database or a spreadsheet.
The goal of data capture is to transform unstructured and semi-structured inputs into structured outputs (like Markdown, JSON, or CSV) that can be used by other business software. In technical and academic circles, this entire process is often referred to as Document Parsing, while in research circles, it is commonly known as Electronic Data Capture (EDC).
The strategic imperative: Why data capture is a business priority
Effective data capture is no longer a back-office optimization; it is the foundational layer for strategic initiatives, such as digital transformation and AI-powered workflows.
Two realities of the modern enterprise drive this urgency:
- The data explosion: Over 80% of all enterprise data is unstructured, locked away in documents, images, and other hard-to-process formats, according to multiple industry analyses.Fragmented technology: This information chaos is compounded by a sprawling and disconnected technology stack. The average organization uses more than 10 different information management systems (e.g., ERP, CRM, file sharing), and studies report that over half of these systems have low or no interoperability, resulting in isolated data silos.
This disjointed setup filled with information chaos—where critical data is trapped in unstructured documents and spread across disconnected systems—makes a unified view of business operations impossible. This same fragmentation is the primary reason that strategic AI initiatives fail.
Advanced applications like Retrieval-Augmented Generation (RAG) are particularly vulnerable. RAG systems are designed to enhance the accuracy and relevance of large language models by retrieving information from a diverse array of external data sources, including databases, APIs, and document repositories. The reliability of a RAG system's output is entirely dependent on the quality of the data it can access.
If the data sources are siloed, inconsistent, or incomplete, the RAG system inherits these flaws. It will retrieve fragmented information, leading to inaccurate answers, hallucinations, and ultimately, a failed AI project. This is why solving the foundational data capture and structuring problem is the non-negotiable first step before any successful enterprise AI deployment.
The central conflict: Manual vs. automated processing
The decision of how to perform data capture has a direct and significant impact on a company's bottom line and operational capacity.
- Manual data capture: This traditional approach involves human operators keying in data. It is fundamentally unscalable. It is notoriously slow and prone to human error, with observed error rates ranging from 1% to 4%. A 2024 report from Ardent Partners found the average all-inclusive cost to process a single invoice manually is $17.61.Automated data capture: This modern approach uses technology to perform the same tasks. Intelligent solutions deliver 95%+ accuracy, process documents in seconds, and scale to handle millions of pages without a proportional increase in cost. The same Ardent Partners report found that full automation reduces the per-invoice processing cost to under $2.70—an 85% decrease.
The choice is no longer about preference; it's about viability. In an ecosystem that demands speed, accuracy, and scalability, automation is the logical path forward.
The evolution of capture technology: From OCR to IDP
The technology behind automated data capture has evolved significantly. Understanding this evolution is key to avoiding the pitfalls of outdated tools and appreciating the capabilities of modern systems.
The old guard: Why traditional OCR fails
The first wave of automation was built on a few core technologies, with Optical Character Recognition (OCR) at its center. OCR converts images of typed text into machine-readable characters. It was often supplemented by:
- Intelligent Character Recognition (ICR): An extension designed to interpret handwritten text.Barcodes & QR Codes: Methods for encoding data into visual patterns for quick scanning.
The fundamental flaw of these early tools was their reliance on fixed templates and rigid rules. This template-based approach requires a developer to manually define the exact coordinates of each data field for a specific document layout.
This is the technology that created widespread skepticism about automation, because it consistently fails in dynamic business environments for several key reasons:
- It is inefficient: A vendor shifting their logo, adding a new column, or even slightly changing a font can break the template, causing the automation to fail and requiring costly IT intervention.It does not scale: Creating and maintaining a unique template for every vendor, customer, or document variation is operationally impossible for any business with a diverse set of suppliers or clients.It lacks intelligence: It struggles to accurately extract data from complex tables, differentiate between visually similar but contextually different fields (e.g., Invoice Date vs. Due Date), or reliably read varied handwriting.
Ultimately, this approach forced teams to spend more time managing and fixing broken templates than they saved on data entry, leading many to abandon the technology altogether.
The modern solution: Intelligent Document Processing (IDP)
Intelligent Document Processing (IDP) is the AI-native successor to traditional OCR. Instead of relying on templates, IDP platforms use a combination of AI, machine learning, and computer vision to understand a document's content and context, much like a human would.
The core engine driving modern IDP is often a type of AI known as a Vision-Language Model (VLM). A VLM can simultaneously understand and process both visual information (the layout, structure, and images on a page) and textual data (the words and characters). This dual capability is what makes modern IDP systems fundamentally different and vastly more powerful than legacy OCR.
A key technical differentiator in this process is Document Layout Analysis (DLA). Before attempting to extract any data, an IDP system's VLM first analyzes the document's overall visual structure to identify headers, footers, paragraphs, and tables. This ability to fuse visual and semantic information is why IDP platforms, such as Nanonets, can accurately process any document format from day one, without needing a pre-programmed template. This is often described as a "Zero-Shot" or "Instant Learning" capability, where the model learns and adapts to new formats on the fly.
The performance leap enabled by this AI-driven approach is immense. A 2024 study focused on transcribing complex handwritten historical documents—a task far more challenging than processing typical business invoices—found that modern multimodal LLMs (the engine behind IDP) were 50 times faster and 1/50th the cost of specialized legacy software. Crucially, they achieved state-of-the-art accuracy "out of the box" without the extensive, document-specific fine-tuning that older systems required to function reliably.
Adjacent technologies: The broader automation ecosystem
IDP is a specialized tool for turning unstructured document data into structured information. It often works in concert with other automation technologies to create an actual end-to-end workflow:
- Robotic Process Automation (RPA): RPA bots act as digital workers that can orchestrate a workflow. For example, an RPA bot can be programmed to monitor an email inbox, download an invoice attachment, send it to an IDP platform for data extraction, and then use the structured data returned by the IDP system to complete a task in an accounting application.Change Data Capture (CDC): While IDP handles unstructured documents, CDC is a more technical, database-level method for capturing real-time changes (inserts, updates, deletes) to structured data. It's a critical technology for modern, event-driven architectures where systems like microservices need to stay synchronized instantly.
Together, these technologies form a comprehensive automation toolkit, with IDP serving the vital role of converting the chaotic world of unstructured documents into the clean, reliable data that all other systems depend on.
The operational blueprint: How data capture works in practice
Modern intelligent data capture is not a single action but a systematic, multi-stage pipeline. Understanding this operational blueprint is essential for moving from chaotic, manual processes to streamlined, automated workflows. The entire process, from document arrival to final data delivery, is designed to ensure accuracy, enforce business rules, and enable true end-to-end automation.
The modern data capture pipeline
An effective IDP system operates as a continuous workflow. This pipeline is often known as a modular system for document parsing and aligns with the data management lifecycle required for advanced AI applications.
Step 1: Data ingestion
The process begins with getting documents into the system. A flexible platform must support multiple ingestion channels to handle information from any source, including:
- Email forwarding: Automatically processing invoices and other documents sent to a dedicated email address (e.g., invoices@company.com).Cloud storage integration: Watching and automatically importing files from cloud folders in Google Drive, OneDrive, Dropbox, or SharePoint.API uploads: Allowing direct integration with other business applications to push documents into the capture workflow programmatically.
Step 2: Pre-processing and classification
Once ingested, the system prepares the document for accurate extraction. This involves automated image enhancement, such as correcting skew and removing noise from scanned documents.
Critically, the AI then classifies the document. Using visual and textual analysis, it determines the document type—instantly distinguishing a US-based W-2 form from a UK-based P60, or an invoice from a bill of lading—and routes it to the appropriate specialized model for extraction.
Step 3: AI-powered extraction
This is the core capture step. As established, IDP uses VLMs to perform Document Layout Analysis, understanding the document's structure before extracting data fields. This allows it to capture information accurately:
- Headers and footersLine items from complex tablesHandwritten notes and signatures
This process works instantly on any document format, eliminating the need for creating or maintaining templates.
Step 4: Validation and quality control
Extracted data is useless if it’s not accurate. This is the most critical step for achieving trust and enabling high rates of straight-through processing (STP). Modern IDP systems validate data in real-time through a series of checks:
- Business rule enforcement: Applying custom rules, such as flagging an invoice if the total_amount does not equal the sum of its line_items plus tax.Database matching: Verifying extracted data against an external system of record. This could involve matching a vendor's VAT number against the EU's VIES database, ensuring an invoice complies with PEPPOL e-invoicing standards prevalent in Europe and ANZ, or validating data in accordance with privacy regulations like GDPR and CCPA.Exception handling: Only documents that fail these automated checks are flagged for human review. This exception-only workflow allows teams to focus their attention on the small percentage of documents that require it.
This validation stage aligns with the Verify step in the RAG pipeline, which confirms data quality, completeness, consistency, and uniqueness before downstream AI systems use it.
Step 5: Data integration and delivery
The final step is delivering the clean, verified, and structured data to the business systems where it is needed. The data is typically exported in a standardized format, such as JSON or CSV, and sent directly to its destination via pre-built connectors or webhooks, thereby closing the loop on automation.
Build vs. buy: The role of open source and foundational models
For organizations with deep technical expertise, a build approach using open-source tools and foundational models is an option. A team could construct a pipeline using foundational libraries like Tesseract or PaddleOCR for the initial text recognition.
A more advanced starting point would be to use a comprehensive open-source library like our own DocStrange. This library goes far beyond basic OCR, providing a powerful toolkit to extract and convert data from nearly any document type—including PDFs, Word documents, and images—into clean, LLM-ready formats like Markdown and structured JSON. With options for 100% local processing, it also offers a high degree of privacy and control.
For the intelligence layer, a team could then integrate the output from DocStrange with a general-purpose model, such as GPT-5 or Claude 4.1, via an API. This requires sophisticated prompt engineering to instruct the model to find and structure the specific data fields needed for the business process.
However, this build path carries significant overhead. It requires a dedicated engineering team to:
- Manage the entire pipeline: Stitching the components together and building all the necessary pre-processing, post-processing, and validation logic.Build a user interface: This is the most critical gap. Open-source libraries provide no front-end for business users (like AP clerks) to manage the inevitable exceptions, creating a permanent dependency on developers for daily operations.Handle infrastructure and maintenance: Managing dependencies, model updates, and the operational cost of running the pipeline at scale.
A buy solution from an IDP platform, such as Nanonets' commercial offering, productizes this entire complex workflow. It packages the advanced AI, a user-friendly interface for exception handling, and pre-built integrations into a managed, reliable, and scalable service.
After extraction: The integration ecosystem
Data capture does not exist in a vacuum. Its primary value is unlocked by its ability to feed other core business systems and break down information silos. Like we discussed earlier, the biggest challenge is the lack of interoperability between these systems.
An intelligent data capture platform acts as a universal translator, creating a central point of control for unstructured data and feeding clean information to:
- ERP and Accounting Systems: For fully automated accounts payable, platforms offer direct integrations with software such as SAP, NetSuite, QuickBooks, and Xero.Document Management Systems (DMS/ECM): For secure, long-term archival in platforms like SharePoint and OpenText.Robotic Process Automation (RPA) Bots: Providing structured data to bots from vendors like UiPath or Automation Anywhere to perform rule-based tasks.Generative AI/RAG Pipelines: Delivering clean, verified, and structured data is the non-negotiable first step to building a reliable internal knowledge base for AI applications.
The goal is to create a seamless flow of information that enables true end-to-end process automation, from document arrival to final action, with minimal to no human intervention.
The business value: ROI and applications
The primary value of any technology is its ability to solve concrete business problems. For intelligent data capture, this value is demonstrated through measurable improvements in cost, speed, and data reliability, which in turn support strategic business objectives.
1. Measurable cost reduction
The most significant outcome of intelligent data capture is the reduction of operational costs. By minimizing the manual labor required for document handling, organizations can achieve substantial savings. Real-world implementation results validate this financial gain.
For example, UK-based Ascend Properties reported an 80% saving in processing costs after automating its maintenance invoices with Nanonets. This allowed the company to scale the number of properties it managed from 2,000 to 10,000 without a proportional increase in administrative headcount.
2. Increased processing velocity
Automating data capture shrinks business cycle times from days to minutes. The Ardent Partners report also found that Best-in-Class AP departments—those with high levels of automation—process and approve invoices in just 3 days, compared to the 18-day average for their peers. This velocity improves cash flow management and strengthens vendor relationships.
As a case example, the global paper manufacturer Suzano International utilized Nanonets to reduce its purchase order processing time from 8 minutes to just 48 seconds, a 90% reduction in time that enabled faster sales order creation in their SAP system.
3. Verifiable data accuracy
While manual data entry is subject to error rates as high as 4%, modern IDP solutions consistently achieve 95%+ accuracy by eliminating human input and using AI for validation. This level of data integrity is a critical prerequisite for any strategic initiative that relies on data, from business intelligence to AI.
4. Strengthened security and auditability
Automated systems create an immutable, digital audit trail for every document that is processed. This provides a clear record of when a document was received, what data was extracted, and who approved it. This auditability is essential for meeting compliance with financial regulations like the Sarbanes-Oxley Act (SOX) and data privacy laws such as GDPR in Europe and the CCPA in the United States.
5. Scalable operations and workforce optimization
Intelligent data capture decouples document volume from headcount. Organizations can handle significant growth without needing to hire more data entry staff. More strategically, it allows for the optimization of the existing workforce. This aligns with a key trend identified in a 2023 McKinsey report, where automation frees employees from repetitive manual and cognitive tasks, allowing them to focus on higher-value work that requires advanced technological, social, and emotional skills.
Real-world applications across key industries
The value of intelligent data capture is realized in the tangible ways it streamlines core business processes. Below are practical data extraction workflows for different industries, illustrating how information is transformed from disorganized documents into actionable data in key business systems.
a. Finance and Accounts Payable
This is among the most common and highest-impact use case.
The process before IDP: Invoices arrive in an AP team’s shared inbox. A clerk manually downloads each PDF, keys data like vendor name, PO number, and line-item amounts into an Excel sheet, and then re-enters that same data into an ERP like NetSuite or SAP. This multi-step, manual process is slow, leading to late payment fees and missed early-payment discounts.
The workflow with Intelligent Data Capture:
- Invoices, including those compliant with PEPPOL standards in the EU and Australia or standard PDFs in the US, are automatically fetched from a dedicated inbox (e.g., invoices@company.com).The IDP platform extracts and validates key data—vendor name, invoice number, line items, and VAT/GST amounts.The system performs an automated 2-way or 3-way match against purchase orders and goods receipt notes residing in the ERP system.Once validated, the data is exported directly into the accounting system—QuickBooks, Xero, NetSuite, or SAP—to create a bill that is ready for payment, often with no human touch.
The outcome: The AP automation solution provider Augeo used this workflow to reduce the time its team spent on invoice processing from 4 hours per day to just 30 minutes—an 88% reduction in manual work.
b. Logistics and Supply Chain
In logistics, speed and accuracy of documentation directly impact delivery times and cash flow.
The process before IDP: A driver completes a delivery and gets a signed Proof of Delivery (POD), often a blurry photo or a multi-part carbon copy. A logistics coordinator at the back office manually deciphers the document and keys the shipment ID, delivery status, and any handwritten notes into a Transport Management System (TMS). Delays or errors in this process hold up billing and reduce customer visibility.
The workflow with Intelligent Data Capture:
- Drivers upload photos of Bills of Lading (BOLs) and signed PODs via a mobile app directly from the field.The IDP system's VLM engine instantly reads the often-distorted or handwritten text to extract the consignee, shipment IDs, and delivery timestamps.This data is validated against the TMS in real-time.The system automatically updates the shipment status to delivered, which simultaneously triggers an invoice to be sent to the client and updates the customer-facing tracking portal.
The outcome: This workflow accelerates billing cycles from days to minutes, reduces disputes over delivery times, and provides the real-time supply chain visibility that customers now expect.
c. Insurance and Healthcare
This sector is burdened by complex, standardized forms that are critical for patient care and revenue cycles.
The process before IDP: Staff at a clinic manually transcribe patient data from registration forms and medical claim forms (like the CMS-1500 in the US) into an Electronic Health Record (EHR) system. This slow process introduces a significant risk of data entry errors that can lead to claim denials or, worse, affect patient care.
The workflow with Intelligent Data Capture:
- Scanned patient forms or digital PDFs of claims are ingested by the IDP system.The platform accurately extracts patient demographics, insurance policy numbers, diagnosis codes (e.g., ICD-10), and procedure codes.The system automatically validates the data for completeness and can check policy information against an insurer's database via an API.Verified data is then seamlessly pushed into the EHR or a claims adjudication workflow.
The outcome: The outcome of this automated workflow is a significant reduction in manual intervention and operational cost. According to McKinsey's Best-in-class digital document processing: A payer perspective report, leading healthcare payers use this kind of an approach to automate 80 to 90 percent of their claims intake process. This resulted in a reduction of manual touchpoints by more than half and cuts the cost per claim by 30 to 40 percent. This is validated by providers like Defined Physical Therapy, which automated its CMS-1500 form processing with Nanonets and reduced its claim processing time by 85%.
The strategic playbook: Implementation and future outlook
Understanding the technology and its value is the first step. The next is putting that knowledge into action. A successful implementation requires a clear-eyed view of the challenges, a practical plan, and an understanding of where the technology is headed.
Overcoming the implementation hurdles
Before beginning an implementation, it's critical to acknowledge the primary obstacles that cause automation projects to fail.
- The data quality hurdle: This is the most significant challenge. As established in AIIM's 2024 report, the primary barrier to successful AI projects is the quality of the underlying data. The main issues are data silos, redundant information, and a lack of data standardization across the enterprise. An IDP project must be viewed as a data quality initiative first and foremost.The organizational hurdle: The same AIIM report highlights a significant skills gap within most organizations, particularly in areas like AI governance and workflow process design. This underscores the value of adopting a managed IDP platform that does not require an in-house team of AI experts to configure and maintain.The integration hurdle: With the average organization using more than 10 different information management systems, creating a seamless flow of data is a major challenge. A successful data capture strategy must prioritize solutions with robust, flexible APIs and pre-built connectors to bridge these system gaps.
A practical plan for implementation
A successful IDP implementation does not require a big bang approach. A phased, methodical rollout that proves value at each stage is the most effective way to ensure success and stakeholder buy-in.
Phase 1: Start small with a high-impact pilot
Instead of attempting to automate every document process at once, select a single, high-pain, high-volume workflow. For most organizations, this is AP invoice processing. The first step is to establish a clear baseline: calculate your current average cost and processing time for a single document in that workflow.
Phase 2: Validate with a no-risk test
De-risk the project by proving the technology's accuracy on your specific documents before making a significant investment. Gather 20-30 real-world examples of your chosen document type, making sure to include the messy, low-quality scans and unusual formats. Use an IDP platform that offers a free trial to test its out-of-the-box performance on these files.
Phase 3: Map the full workflow
Data extraction is only one piece of the puzzle. To achieve true automation, you must map the entire process from document arrival to its final destination. This involves configuring the two most critical components of an IDP platform:
- Validation rules: Define the business logic that ensures data quality (e.g., matching a PO number to your ERP data).Integrations: Set up the connectors that will automatically deliver the clean data to downstream systems.
Phase 4: Measure and scale
Once your pilot workflow is live, track its performance against your initial baseline. The key metrics to monitor are Accuracy Rate, Processing Time per Document, and STP Rate (the percentage of documents processed with no human intervention). The proven ROI from this first process can then be used to build the business case for scaling the solution to other document types and departments.
The future outlook: What's next for data capture
The field of intelligent data capture continues to evolve rapidly. As of August 2025, three key trends are shaping the future of the technology:
- Generative AI and RAG: The primary driver for the future of data capture is its role as the essential fuel for Generative AI. As more companies build internal RAG systems to allow employees and customers to "ask questions of their data," the demand for high-quality, structured information extracted from documents will only intensify.Multimodal AI: The technology is moving beyond just text. As detailed in the Document Parsing Unveiled research paper, the next generation of IDP is powered by advanced VLMs that can understand and extract information from images, charts, and tables within a document and explain their relationship to the surrounding text.Agentic AI: This represents the next frontier, where AI moves from being a tool that responds to a system that acts. According to a 2025 PwC report, these AI agents are designed to automate complex, multi-step workflows autonomously. For example, an AP agent could be tasked with resolving an invoice discrepancy. It would then independently retrieve the invoice and PO, compare them, identify the mismatch, draft a clarification email to the vendor, and create a follow-up task in the appropriate system.
Conclusion: From a mundane task to a strategic enabler
Intelligent data capture is no longer a simple digitization task; it is the foundational layer for the modern, AI-powered enterprise. The technology has evolved from brittle, template-based OCR to intelligent, context-aware systems that can handle the complexity and diversity of real-world business documents with verifiable accuracy and a clear return on investment.
By solving the input problem, intelligent data capture breaks down the information silos that have long plagued businesses, transforming unstructured data from a liability into a strategic asset. For the pragmatic and skeptical professionals on the front lines of document processing, the promises of automation are finally becoming a practical reality.
Your next steps
- Calculate your cost of inaction. Identify your single most painful document process. Use the industry average of $17.61 per manually processed invoice as a starting point and calculate your current monthly cost. This is the budget you are already spending on inefficiency.Run a 15-minute accuracy test. Gather 10 diverse examples of that problem document. Use a free trial of an IDP platform to see what level of accuracy you can achieve on your own files in minutes, without any custom training.Whiteboard one end-to-end workflow. Map the entire journey of a single document, from its arrival in an email inbox to its data being usable in your ERP or accounting system. Every manual touchpoint you identify is a target for automation. This map is your blueprint for achieving true straight-through processing.
FAQs
What is the difference between data capture and OCR?
Optical Character Recognition (OCR) is a specific technology that converts images of text into machine-readable characters. It is a single, foundational component of a larger process.
Data Capture (or more accurately, Intelligent Document Processing) is the complete, end-to-end business workflow. This workflow includes ingestion, pre-processing, classification, data extraction (which uses OCR as one of its tools), automated validation against business rules, and finally, integration into other business systems.
How does intelligent data capture ensure data accuracy?
Intelligent data capture uses a multi-layered approach to ensure accuracy far beyond what simple OCR can provide:
Contextual AI Extraction: The use of VLMs allows the system to understand the document's context, reducing the likelihood of misinterpreting fields (e.g., confusing a "due date" with an "invoice date").
Confidence Scoring: The AI assigns a confidence score to each extracted field, automatically flagging low-confidence data for human review.
Automated Validation Rules: The system automatically checks the extracted data against your specific business logic (e.g., confirming that subtotal + tax = total amount).
Database Matching: It can validate data against external databases, such as matching a purchase order number on an invoice against a list of open POs in your ERP system.
What is the best way to capture data from handwritten forms?
The best way to capture data from handwritten forms is to use a modern IDP solution powered by advanced AI and multimodal Large Language Models (LLMs). While older technology called Intelligent Character Recognition (ICR) was used for this, a 2024 research paper titled Unlocking the Archives found that modern LLMs achieve state-of-the-art accuracy on handwritten text out-of-the-box. They are 50 times faster and 1/50th the cost of specialized legacy software, and they do not require the impractical step of being trained on a specific person's handwriting to be effective.
How do you calculate the ROI of automating data capture?
The ROI is calculated by comparing the total cost of your manual process to the total cost of the automated process. A simple framework is:
Calculate Your Manual Cost: Determine your cost per document (Time per document x Employee hourly rate) + Costs of fixing errors. A widely used industry benchmark for a single invoice is $17.61.
Calculate Your Automated Cost: This includes the software subscription fee plus the cost of labor for handling the small percentage of exceptions flagged for manual review. The benchmark for a fully automated invoice is under $2.70.
Determine Monthly Savings: Total Monthly Manual Cost - Total Monthly Automated Cost.
Calculate Payback Period: Total Upfront Implementation Cost / Monthly Savings.
Can data capture software integrate with ERP systems like SAP or NetSuite?
Yes. Seamless integration with Enterprise Resource Planning (ERP) and accounting systems is a critical feature of any modern data capture platform. This is essential for achieving true end-to-end automation for processes like accounts payable. Leading IDP solutions offer a combination of pre-built connectors for popular systems like SAP, NetSuite, QuickBooks, and Xero, as well as flexible APIs for custom integrations. This allows the clean, validated data to flow directly into your system of record without any manual re-entry.
How does automated data capture help with GDPR and CCPA compliance?
Automated data capture helps with compliance for regulations like GDPR (in the EU) and CCPA (in the US) in several key ways:
Creates a Clear Audit Trail: The system provides an immutable digital log of every document that is processed, showing what data was accessed, by whom, and when. This is essential for accountability.
Enables Data Minimization: Platforms can be configured to only extract necessary data fields and can automatically redact or mask sensitive Personally Identifiable Information (PII).
Strengthens Access Control: Unlike paper documents, digital data can be protected with strict, role-based access controls, ensuring that only authorized personnel can view sensitive information.
Provides Secure Storage and Deletion: The data is handled in secure, encrypted environments, and platforms can enforce data retention policies to automatically delete data according to regulatory requirements.
