

TL;DR: This guide provides a clear framework for navigating the fragmented market for data extraction software. It clarifies the three main categories of tools based on your data source: ETL/ELT platforms for moving structured data between applications and databases, web scrapers for extracting public information from websites, and Intelligent Document Processing (IDP) for extracting data from unstructured business documents, such as invoices and contracts. For most operational challenges, the best solution is an end-to-end IDP workflow that integrates ingestion, AI-powered capture, automated validation, and seamless ERP integration. The ROI of this approach is strategic, helping to prevent financial value leakage and directly contributing to measurable gains, a $40,000 increase in Net Operating Income.
You’ve likely heard the old computer science saying: “Garbage In, Garbage Out.” It’s the quiet reason so many expensive AI projects are failing to deliver. The problem isn't always the AI; it's the quality of the data we’re feeding it. A 2024 industry report found that a startling 77% of companies admit their data is average, poor, or very poor in terms of AI readiness. The culprit is the chaotic, unstructured information that flows into business operations daily through documents like invoices, contracts, and purchase orders.
Your search for a data extraction solution may have been confusing. You would have come across developer-focused database tools, simple web scrapers, and advanced document processing platforms, all under the same umbrella. The question is, what should you invest in? Ultimately, you need to make sense of messy, unstructured documents. The key to that isn't finding a better tool; it's asking the right question about your data source.
This guide provides a clear framework to diagnose your specific data challenge and presents a practical playbook for solving it. We will show you how to overcome the limitations of traditional OCR and manual entry, building an AI-ready foundation. The result is a workflow that can reduce document processing costs by as much as 80% and achieve over 98% data accuracy, enabling the seamless flow of information trapped in your documents.
The data extraction spectrum: A framework for clarity
The search for data extraction software can be confusing because the term is often used to describe three completely different kinds of tools that solve three different problems. The right solution depends entirely on where your data lives. Understanding the spectrum is the first step to finding a tool that actually works for your business.
1. Public web data (Web Scraping)
- What it is: This category includes tools designed to pull publicly available information from websites automatically. Common use cases include gathering competitor pricing, collecting product reviews, or aggregating real estate listings.Who it's for: Marketing teams, e-commerce analysts, and data scientists.Bottom line: Choose this category if your data is structured on public websites.Leading solutions: This space is occupied by platforms like Bright Data and Apify, which offer robust proxy networks and pre-built scrapers for large-scale public data collection. No-code tools like Octoparse are also popular for non-technical users.
2. Structured application and database data (ETL/ELT)
- What it is: This software moves already structured data from one system to another. The process is commonly referred to as Extract, Transform, Load (ETL). A typical use case involves syncing sales data from a CRM, such as Salesforce, into a central data warehouse for business intelligence reporting.Who it's for: Data engineers and IT departments.Bottom line: Choose this category if your data is already organized inside a database or a SaaS application.Leading solutions: The market leaders here are platforms like Fivetran and Airbyte. They specialize in providing hundreds of pre-built connectors to SaaS applications and databases, automating a process that would otherwise require significant custom engineering.
3. Unstructured document data (Intelligent Document Processing - IDP)
- What it is: This is AI-powered software built to read and understand the unstructured or semi-structured documents that run your business: the PDFs, emails, scans, invoices, purchase orders, and contracts. It finds the specific information you need—like an invoice number or contract renewal date—and turns it into clean, structured data.Who it's for: Finance, Operations, Procurement, Legal, and Healthcare teams.Bottom line: Choose this category if your data is trapped inside documents. This is the most common and costly challenge for business operations.Leading solutions: This category contains specialized document data extraction software like Nanonets, Rossum, ABBYY, and Tungsten Automation (formerly Kofax). Developer-focused services like Amazon Textract also fit here. Unlike web scrapers, these platforms are engineered with advanced AI to handle document-specific challenges like layout variations, table extraction, and handwriting recognition.
The 2024 industry report we cited earlier also confirms it's the most significant bottleneck, with over 62% of procurement processes and 59% of legal contract management still being highly manual due to document complexity. The rest of this guide will focus on this topic.
The strategic operator's playbook for document data extraction
Document data extraction has evolved from a simple efficiency tool into a strategic imperative for enterprise AI adoption. As businesses look to 2026's most powerful AI applications, particularly those utilizing Retrieval-Augmented Generation (RAG), the quality of their internal data becomes increasingly crucial. But, even advanced AI models like Gemini, Claude, or ChatGPT struggle with imperfect document scans, and accuracy rates for these leading LLMs hover around 60-70% for document processing tasks.
This reality underscores that successful AI implementation requires more than just powerful models – it demands a comprehensive platform with human oversight to ensure reliable data extraction and validation.
A modern IDP solution is not a single tool but an end-to-end workflow engineered to turn document chaos into a structured, reliable, and secure asset. This playbook outlines the four critical stages of the workflow and provides a practical two-week implementation plan.
Before we proceed, the table below provides a quick overview of the most common and high-impact data extraction applications across various departments. It showcases the specific documents, the type of data extracted, and the strategic business outcomes achieved.
| Industry | Common Documents | Key Data Extracted | Strategic Business Outcome |
|---|---|---|---|
| Finance & Accounts Payable | Invoices, Receipts, Bank Statements, Expense Reports | Vendor Name, Invoice Number, Line Items, Total Amount, Transaction Details | Accelerate the financial close by automating invoice coding and 3-way matching; optimize working capital by ensuring on-time payments and preventing errors. |
| Procurement & Supply Chain | Purchase Orders, Contracts, Bills of Lading, Customs Forms | PO Number, Supplier Details, Contract Renewal Date, Shipment ID, HS Codes | Mitigate value leakage by automatically flagging off-contract spend and unfulfilled supplier obligations; shift procurement from transactional work to strategic supplier management. |
| Healthcare & Insurance | HCFA-1500/CMS-1500 Claim Forms, Electronic Health Records (EHRs), Patient Onboarding Forms | Patient ID, Procedure Codes (CPT), Diagnosis Codes (ICD), Provider NPI, Clinical Notes | Accelerate claims-to-payment cycles and reduce denials; create high-quality, structured datasets from unstructured EHRs to power predictive models and improve clinical decision support. |
| Legal | Service Agreements, Non-Disclosure Agreements (NDAs), Master Service Agreements (MSAs) | Effective Date, Termination Clause, Liability Limits, Governing Law | Reduce contract review cycles and operational risk by automatically extracting key clauses, dates, and obligations; uncover hidden value leakage by auditing contracts for non-compliance at scale. |
| Manufacturing | Bills of Materials (BOMs), Quality Inspection Reports, Work Orders, Certificates of Analysis (CoA) | Part Number, Quantity, Material Spec, Pass/Fail Status, Serial Number | Improve quality control by digitizing inspection reports; accelerate production cycles by automating work order processing; ensure compliance by verifying material specifications from CoAs. |
Part A: The 4-stage modern data extraction engine for AI-ready data
The evolution of information extraction from the rigid, rule-based methods of the past to today's adaptive, machine learning-driven systems has made true workflow automation possible. This modern workflow consists of four essential, interconnected stages.
Step 1: Omnichannel ingestion
The goal here is to stop the endless cycle of manual downloads and uploads by creating a single, automated entry point for all incoming documents. This is the first line of defense against the data fragmentation that plagues many organizations, where critical information is scattered across different systems and inboxes. A robust platform connects directly to your existing channels, allowing documents to flow into a centralized processing queue from sources like:
- A dedicated email inbox (e.g., invoices@company.com).Shared cloud storage folders (Google Drive, OneDrive, Dropbox).A direct API connection from your other business software.
Step 2: AI-first data capture
This is the core technology that distinguishes modern IDP from outdated Optical Character Recognition (OCR). Legacy OCR relies on rigid templates, which break the moment a vendor changes their invoice layout. AI-first platforms are "template-agnostic." They are pre-trained on millions of documents and learn to identify data fields based on context, much like a human would.
This AI-driven approach is crucial for handling the complexities of real-world documents. For instance, a recent study found that even minor document skew (in-plane rotation from a crooked scan) "adversely affects the data extraction accuracy of all the tested LLMs," with performance for models like GPT-4-Turbo dropping significantly beyond a 35-degree rotation. The best data extraction software includes pre-processing layers that automatically detect and correct for skew before the AI even begins extracting data.
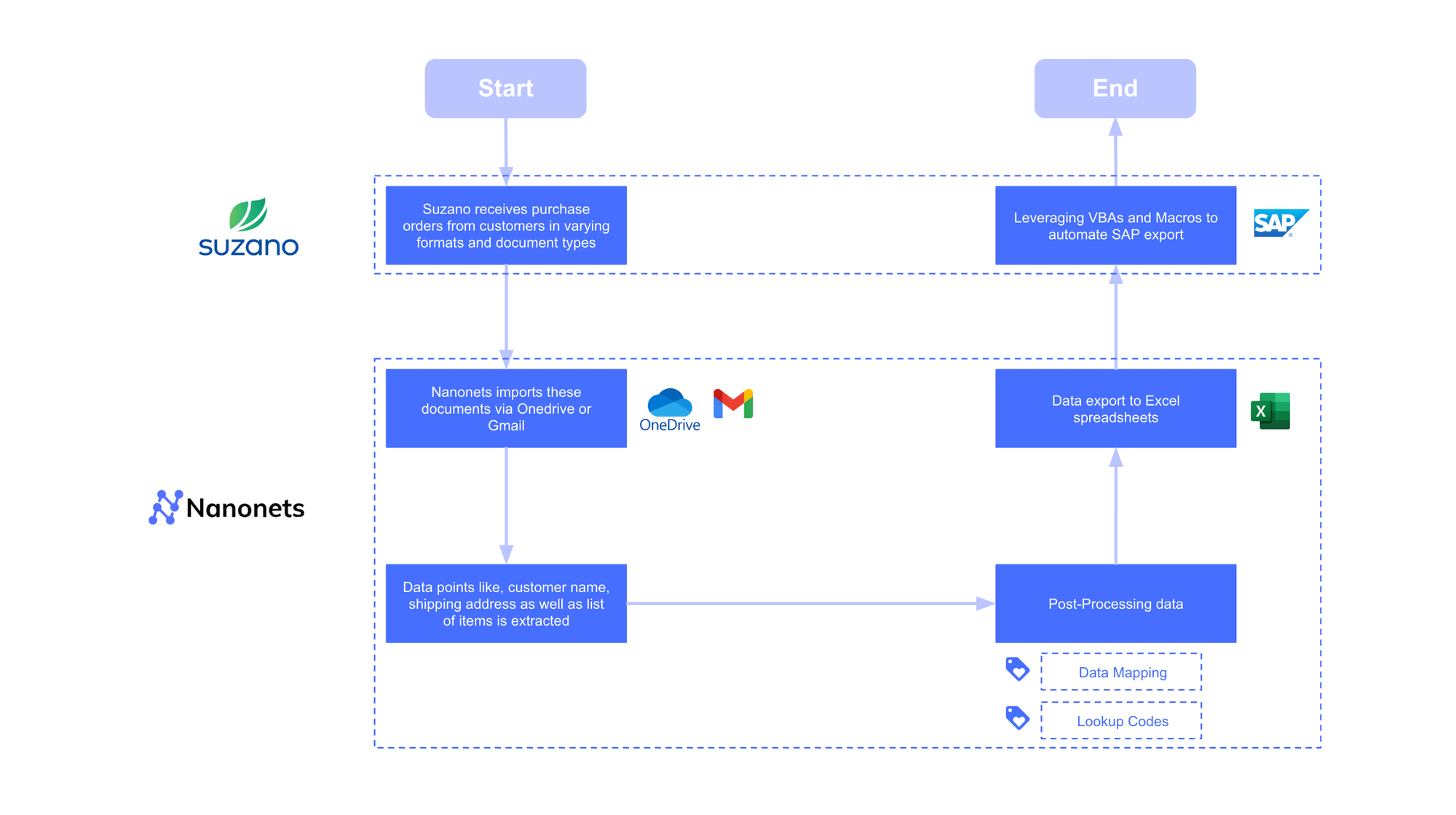
This adaptability is proven at scale. Suzano International processes purchase orders from over 70 customers, each with a unique format. A template-based system would have been unmanageable. By utilizing an AI-driven IDP platform, they efficiently handled all variations, reducing their processing time per order by 90%—from 8 minutes to just 48 seconds.
~ Cristinel Tudorel Chiriac, Project Manager at Suzano.
Step 3: Automated validation and enhancement
Raw extracted data is not business-ready. This stage is the practical application of the "Human-in-the-Loop" (HIL) principle that academic research has proven is non-negotiable for achieving reliable data from AI systems. One 2024 study on LLM-based data extraction concluded there is a "dire need for a human-in-the-loop (HIL) process" to overcome accuracy limitations.
This is what separates a simple "extractor" from an enterprise-grade "processing system." Instead of manual spot-checks, a no-code rule engine can automatically enforce your business logic:
- Internal consistency: Rules that check data within a single document. For example, flagging an invoice if subtotal + tax_amount does not equal total_amount.Historical consistency: Rules that check data against past documents. For example, automatically flagging any invoice where the invoice_number and vendor_name match a document processed in the last 90 days to prevent duplicate payments.External consistency: Rules that check data against your systems of record. For example, verifying that a PO_number on an invoice exists in your master Purchase Order database before routing for payment.
Step 4: Seamless integration and export
The final step is to "close the loop" and eliminate the last mile of manual data entry. Once the data is captured and validated, the platform must automatically export it into your system of record. Without this step, automation is incomplete and creates a new manual task: uploading a CSV file.
Leading IDP platforms provide pre-built, two-way integrations with major ERP and accounting systems, such as QuickBooks, NetSuite, and SAP, enabling the system to automatically sync bills and update payment statuses without requiring human intervention.
Part B: Your 2-week implementation plan
Deploying one of these data extraction solutions does not require a multi-month IT project that drains resources and delays value. With a modern, no-code IDP platform, a business team can achieve significant automation in a matter of weeks. This section provides a practical two-week sprint plan to guide you from pilot to production, followed by an honest assessment of the real-world challenges you must anticipate for a successful deployment.
Week 1: Setup, pilot, and fine-tuning
- Setup and pilot: Connect your primary document source (e.g., your AP email inbox). Upload a diverse batch of at least 30 historical documents from 5-10 different vendors. Perform a one-time verification of the AI's initial extractions. This involves a human reviewing the AI's output and making corrections, providing crucial feedback to the model for your specific document types.Train and configure: Initiate a model re-train based on your verified documents. This fine-tuning process typically takes 1-2 hours. While the model trains, configure your 2-3 most critical validation rules and approval workflows (e.g., flagging duplicates and routing high-value invoices to a manager).
Week 2: Go live and measure
- Go live: Begin processing your live, incoming documents through the now-automated workflow.Monitor your key metric: The most important success metric is your Straight-Through Processing (STP) Rate. This is the percentage of documents that are ingested, captured, validated, and exported with zero human touches. Your goal should be to achieve an STP rate of 80% or higher. For reference, the property management firm Hometown Holdings achieved an 88% STP rate after implementing its automated workflow.
Part C: Navigating the real-world implementation challenges
The path to successful automation involves anticipating and solving key operational challenges. While the technology is robust, treating it as a simple "plug-and-play" solution without addressing the following issues is a common cause of failure. This is what separates a stalled project from a successful one.
- The problem: The dirty data reality
- What it is: Real-world business documents are messy. Scans are often skewed, formats are inconsistent, and data is fragmented across systems. It can cause even advanced AI models to hallucinate and produce incorrect outputs.Actionable solution:
- Prioritize a platform with robust pre-processing capabilities that automatically detect and correct image quality issues like skew.Create workflows that consolidate related documents before extraction to provide the AI with a complete picture.
- What it is: Many automation projects succeed at extraction but fail at the final, crucial step of getting validated data into a legacy ERP or system of record. This leaves teams stuck manually uploading CSV files, a bottleneck that negates most of the efficiency gains. This issue is a leading cause of project failure. This issue is a leading cause of project failure. A BCG report found that 65% of digital transformations fail to achieve their objectives, often because organizations "underestimate integration complexities".Actionable solution:
- Define your integration requirements as a non-negotiable part of your selection process.Prioritize platforms with pre-built, two-way integrations for your specific software stack (e.g., QuickBooks, SAP, NetSuite).The ability to automatically sync data is what enables true, end-to-end straight-through processing.
- What it is: Your document processing platform is the gateway to your company's most sensitive financial, legal, and customer data. Connecting internal documents to AI platforms introduces new and significant security risks if not properly managed. As a 2025 PwC report on AI predicts, rigorous governance and validation of AI systems will become "non-negotiable".Actionable solution:
- Choose a vendor with enterprise-grade security credentials (e.g., SOC 2, GDPR, HIPAA compliance)Ensure vendors have a clear data governance policy that guarantees your data will not be used to train third-party models.
The ROI: From preventing value leakage to driving profit
A modern document automation platform is not a cost center; it's a value-creation engine. The return on investment (ROI) goes far beyond simple time savings, directly impacting your bottom line by plugging financial drains that are often invisible in manual workflows.
A 2025 McKinsey report identifies that one of the most significant sources of value leakage is companies losing roughly 2% of their total spend to issues such as off-contract purchases and unfulfilled supplier obligations. Automating and validating document data is one of the most direct ways to prevent this.
Here’s how this looks in practice across different businesses.
Example 1: 80% cost reduction in property management
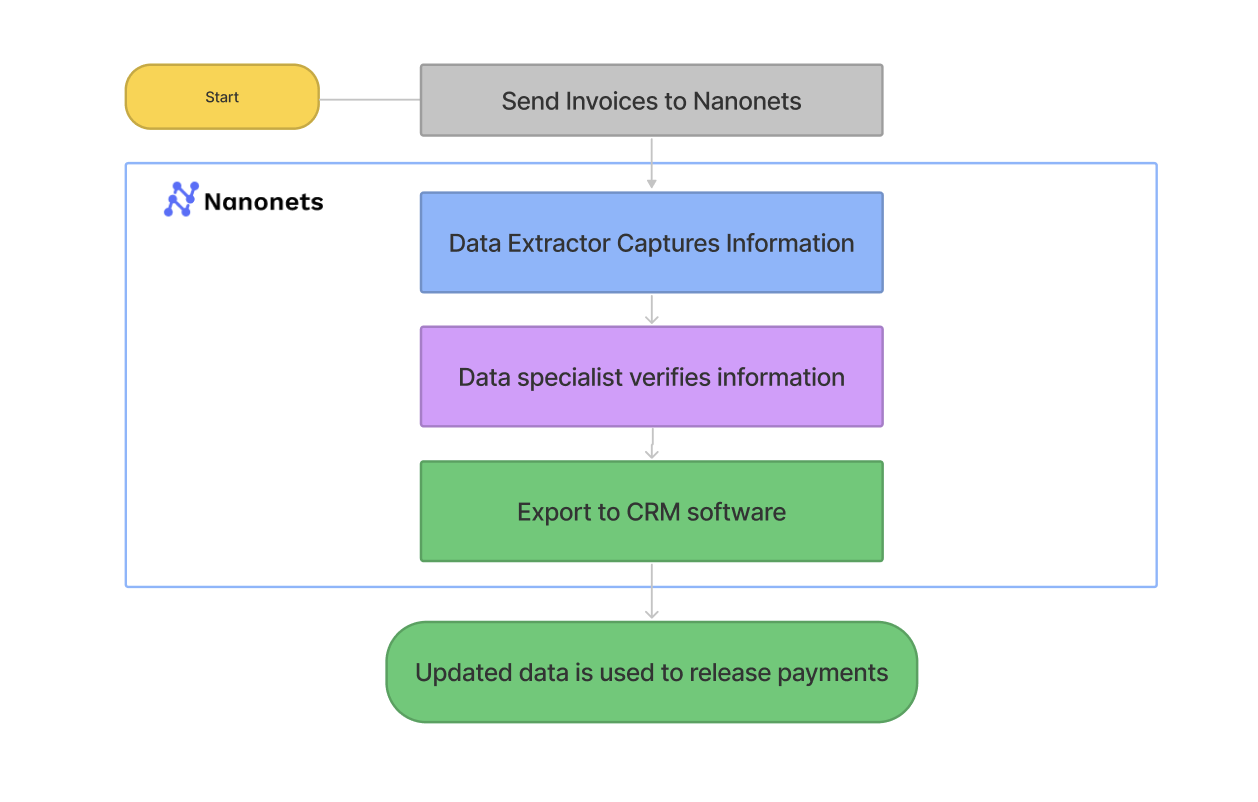
Ascend Properties, a rapidly growing property management firm, saw its invoice volume grow 5x in four years.
- Before: To handle the volume manually, their process would have required five full-time employees dedicated to just invoice verification and entry.After: By implementing an IDP platform, they now process 400 invoices a day in just 10 minutes with only one part-time employee for oversight.The result: This led to a direct 80% reduction in processing costs and saved the work of four full-time employees, allowing them to scale their business without scaling their back-office headcount.
Example 2: $40,000 increase in Net Operating Income
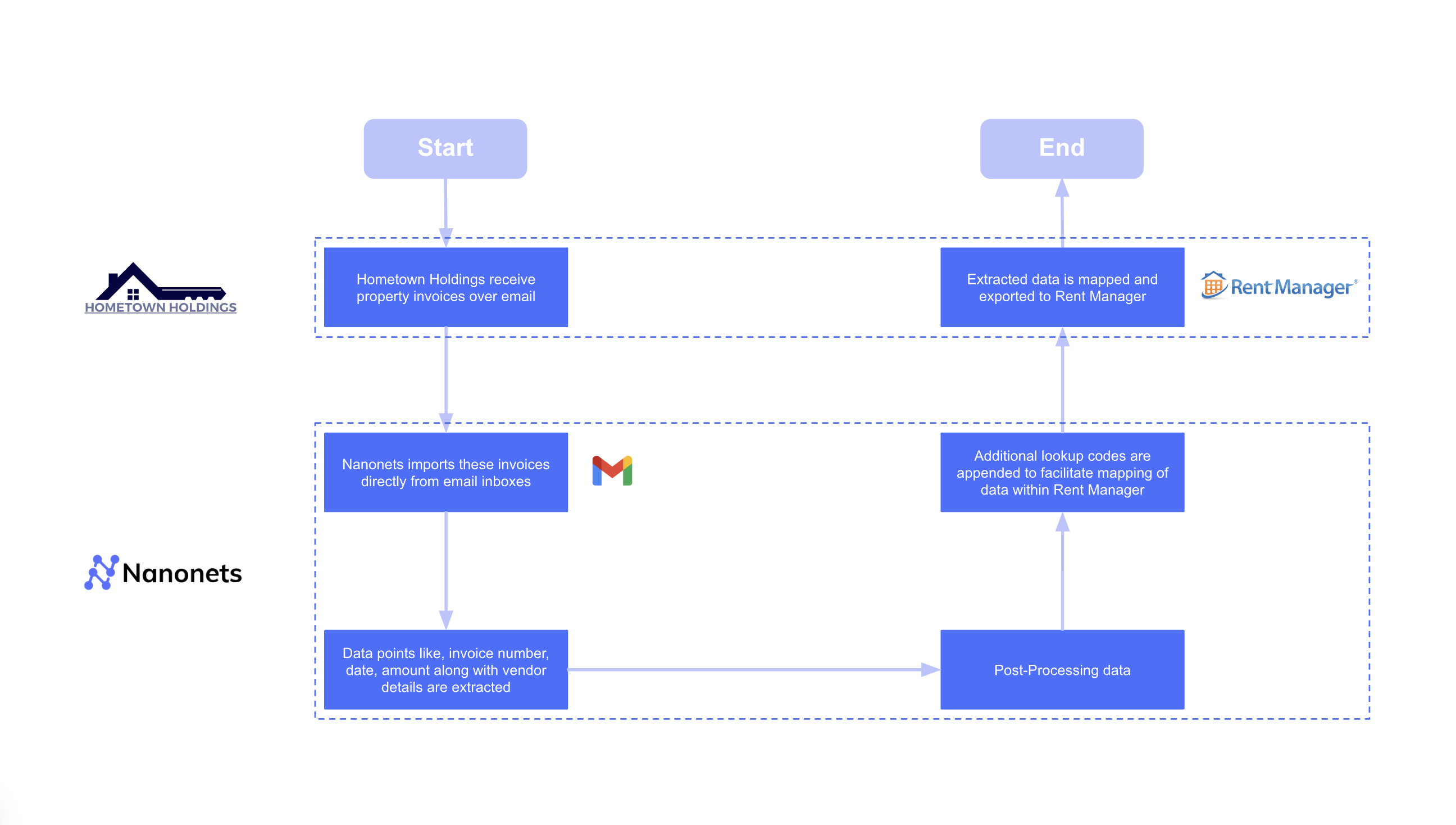
For Hometown Holdings, another property management company, the goal was not just cost savings but value creation.
- Before: Their team spent 4,160 hours annually manually entering utility bills into their Rent Manager software.After: The automated workflow achieved an 88% Straight-Through Processing (STP) rate, nearly eliminating manual entry.The result: Beyond the massive time savings, the increased operational efficiency and improved financial accuracy contributed to a $40,000 increase in the company's NOI.
Example 3: 192 Hours Saved Per Month at enterprise scale
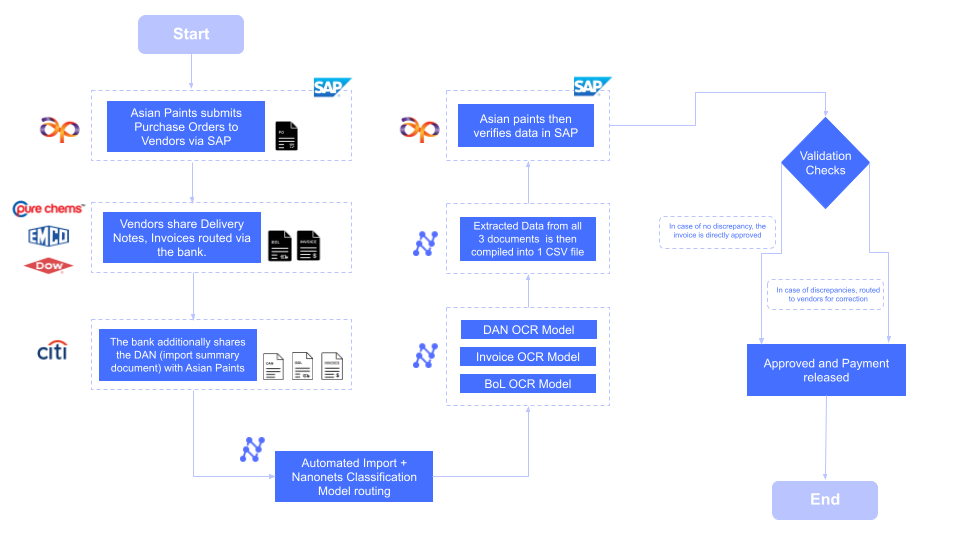
The impact of automation scales with volume. Asian Paints, one of Asia's largest paint companies, manages a network of over 22,000 vendors.
- Before: Processing the complex set of documents for each vendor—purchase orders, invoices, and delivery notes—took an average of 5 minutes per document.After: The AI-driven workflow reduced the processing time to ~30 seconds per document.The result: This 90% reduction in processing time saved the company 192 person-hours every month, freeing up the equivalent of a full-time employee to focus on more strategic financial tasks instead of data entry.
The 2025 toolkit: Best data extraction software by category
The market for data extraction software is notoriously fragmented. You cannot group platforms built for database replication (ETL/ELT), web scraping, and unstructured document processing (IDP) together. It creates a significant challenge when trying to find a solution that matches your actual business problem. In this section, we will help you evaluate different data extraction tools and select the ones most suitable for your use case.
We will briefly cover the leading platforms for web and database extraction before examining IDP solutions designed for complex business documents. We will also address the role of open-source components for teams considering a custom "build" approach.
a. For application and database Extraction (ETL/ELT)
These platforms are the workhorses for data engineering teams. Their primary function is to move pre-structured data from various applications (such as Salesforce) and databases (like PostgreSQL) into a central data warehouse for analytics.
1. Fivetran
Fivetran is a fully managed, automated ELT (Extract, Load, Transform) platform known for its simplicity and reliability. It is designed to minimize the engineering effort required to build and maintain data pipelines.
- Pros:
- Intuitive, no-code interface that accelerates deployment for non-technical teams.Its automated schema management, which adapts to changes in source systems, is a key strength that significantly reduces maintenance overhead.
- Consumption-based pricing model, while flexible, can lead to unpredictable and high costs at scale, a common concern for enterprise users.As a pure ELT tool, all transformations happen post-load in the data warehouse, which can increase warehouse compute costs.
- Offers a free plan for low volumes (up to 500,000 monthly active rows).Paid plans follow a consumption-based pricing model.
- Supports over 500 connectors for databases, SaaS applications, and events.
- Fully managed and automated connectors.Automated handling of schema drift and normalization.Real-time or near-real-time data synchronization.
Best use-cases: Fivetran's primary use case is creating a single source of truth for business intelligence. It excels at consolidating data from multiple cloud applications (e.g., Salesforce, Marketo, Google Ads) and production databases into a data warehouse, such as Snowflake or BigQuery.
Ideal customers: Data teams at mid-market to enterprise companies who prioritize speed and reliability over the cost and complexity of building and maintaining custom pipelines.
2. Airbyte
Airbyte is a leading open-source data integration platform that offers a highly extensible and customizable alternative to fully managed solutions, favored by technical teams who require more control.
- Pros:
- Being open-source eliminates vendor lock-in, and the Connector Development Kit (CDK) allows developers to build custom connectors quickly.It has a large and rapidly growing library of over 600 connectors, with a significant portion contributed by its community.
- The setup and management can be complex for non-technical users, and some connectors may require manual maintenance or custom coding.Self-hosted deployments can be resource-heavy, especially during large data syncs. The quality and reliability can also vary across the many community-built connectors.
- A free and unlimited open-source version is available.A managed cloud plan is also available, priced per credit.
- Supports over 600 connectors, with the ability to build custom ones.
- Both ETL and ELT capabilities with optional in-flight transformations.Change Data Capture (CDC) support for database replication.Flexible deployment options (self-hosted or cloud).
Best use-cases: Airbyte is best suited for integrating a wide variety of data sources, including long-tail applications or internal databases for which pre-built connectors may not exist. Its flexibility makes it ideal for building custom, scalable data stacks.
Ideal customers: Organizations with a dedicated data engineering team that values the control, flexibility, and cost-effectiveness of an open-source solution and is equipped to manage the operational overhead.
3. Qilk Talend
Qilk Talend is a comprehensive, enterprise-focused data integration and management platform that provides a suite of products for ETL, data quality, and data governance.
- Pros:
- Offers extensive and powerful data transformation and data quality features that go far beyond simple data movement.Supports a wide range of connectors and has flexible deployment options (on-prem, cloud, hybrid).
- Steep learning curve compared to newer, no-code tools.The enterprise edition comes with high licensing costs, making it less suitable for smaller businesses.
- Offers a basic, open-source version. Paid enterprise plans require a custom quote.
- Supports over 1,000 connectors for databases, cloud services, and enterprise applications.
- Advanced ETL/ELT customization.Strong data governance tools (lineage, compliance).Open-source availability for core functions.
Best use-cases: Talend is ideal for large-scale, enterprise data warehousing projects that require complex data transformations, rigorous data quality checks, and comprehensive data governance.
Ideal customers: Large enterprises, particularly in regulated industries like finance and healthcare, with mature data teams that require a full-featured data management suite.
b. For web data extraction (Web Scraping)
These tools are for pulling public data from websites. They are ideal for market research, lead generation, and competitive analysis.
1. Bright Data
Bright Data is positioned as an enterprise-grade web data platform, with its core strength being its massive and reliable proxy network, which is essential for large-scale, anonymous data collection.
- Pros:
- Its extensive network of data centers and residential IPs allows it to bypass geo-restrictions and complex anti-bot measures.The company emphasizes a "compliance-first" approach, providing a level of assurance for businesses concerned with the ethical and legal aspects of web data collection.
- Steep learning curve, with a large number of features that can be overwhelming for new users.Occasional proxy instability or blockages can disrupt time-sensitive data collection workflows.
- Plans are typically subscription-based, with some starting around $500/month.
- Primarily integrates via a robust API, allowing developers to connect it to custom applications.
- Large datacenter and residential proxy networks.Pre-built web scrapers and other data collection tools.
Best use-cases: Bright Data is best for large-scale web scraping projects that require high levels of anonymity and geographic diversity. It is well-suited for tasks like e-commerce price monitoring, ad verification, and collecting public social media data.
Ideal customers: The ideal customers are data-driven companies, from mid-market to enterprise, that have a continuous need for large volumes of public web data and require a robust and reliable proxy infrastructure to support their operations.
2. Apify
Apify is a comprehensive cloud platform offering pre-built scrapers (called "Actors") and the tools to build, deploy, and manage custom web scraping and automation solutions.
- Pros:
- The Apify Store contains over 2,000 pre-built scrapers, which can significantly accelerate projects for common targets like social media or e-commerce sites.The platform is highly flexible, catering to both developers who want to build custom solutions and business users who can leverage the pre-built Actors.
- The cost can escalate for large-scale or high-frequency data operations, a common concern in user feedback.While pre-built tools are user-friendly, fully utilizing the platform's custom capabilities requires technical knowledge.
- Offers a free plan with platform credits.Paid plans start at $49/month and scale with usage.
- Integrates with Google Sheets, Amazon S3, and Zapier, and supports webhooks for custom integrations.
- A large marketplace of pre-built scrapers ("Actors").A cloud environment for developing, running, and scheduling scraping tasks.Tools for building custom automation solutions.
Best use-cases: Automating data collection from e-commerce sites, social media platforms, real estate listings, and marketing tools. Its flexibility makes it suitable for both quick, small-scale jobs and complex, ongoing scraping projects.
Ideal customers: A wide range of users, from individual developers and small businesses using pre-built tools to large companies building and managing custom, large-scale scraping infrastructure.
3. Octoparse
Octoparse is a no-code web scraping tool designed for non-technical users. It uses a point-and-click interface to turn websites into structured spreadsheets without writing any code.
- Pros:
- The visual, no-code interface.It can handle dynamic websites with features like infinite scroll, logins, and dropdown menus.Offers cloud-based scraping and automatic IP rotation to prevent blocking.
- While powerful for a no-code tool, it may struggle with highly complex or aggressively protected websites compared to developer-focused solutions.
- Offers a limited free plan.Paid plans start at $89/month.
- Exports data to CSV, Excel, and various databases.Also offers an API for integration into other applications.
- No-code point-and-click interface.Hundreds of pre-built templates for common websites.Cloud-based platform for scheduled and continuous data extraction.
Best use-cases: Market research, price monitoring, and lead generation for business users, marketers, and researchers who need to collect structured web data but do not have coding skills.
Ideal customers: Small to mid-sized businesses, marketing agencies, and individual entrepreneurs who need a user-friendly tool to automate web data collection.
c. For document data extraction (IDP)
This is the solution to the most common and painful business challenge: extracting structured data from unstructured documents. These platforms require specialized AI that understands not only text but also the visual layout of a document, making them the ideal choice for business operators in finance, procurement, and other document-intensive departments.
1. Nanonets
Nanonets is a leading IDP platform for businesses that need a no-code, end-to-end workflow automation solution. Its key differentiator is its focus on managing the entire document lifecycle with a high degree of accuracy and flexibility.
- Pros:
- Manages the entire process from omnichannel ingestion and AI-powered data capture to automated validation, multi-stage approvals, and deep ERP integration, which is a significant advantage over tools that only perform extraction.The platform's template-agnostic AI can be fine-tuned to achieve very high accuracy (over 98% in some cases) and continuously learns from user feedback, making it highly adaptable to new document formats without manual template creation.The system is highly flexible and can be programmed for complex, bespoke use cases.
- While it offers a free tier, the Pro plan's starting price may be a consideration for tiny businesses or startups with extremely low document volumes.
- Offers a free plan with credits upon sign-up.Paid plans are subscription-based per model, with overages charged per field or page.
- Offers pre-built, two-way integrations with major ERP and accounting systems like QuickBooks, NetSuite, SAP, and Salesforce.
- AI-powered, template-agnostic OCR that continuously learns.A no-code, visual workflow builder for validation, approvals, and data enhancement.Pre-trained models for common documents like invoices, receipts, and purchase orders.Zero-shot models that use natural language to describe the data you want to extract from any document.
Best use-cases: Automating document-heavy business processes where accuracy, validation, and integration are critical. This includes accounts payable automation, sales order processing, and compliance document management. For example, Nanonets helped Ascend Properties save the equivalent work of 4 FTEs by automating their invoice processing workflow.
Ideal customers: Business teams (Finance, Operations, Procurement) in mid-market to enterprise companies who need a powerful, flexible, and easy-to-use platform to automate their document workflows without requiring a dedicated team of developers.
2. Rossum
Rossum is a strong IDP platform with a particular focus on streamlining accounts payable and other document-based processes.
- Pros:
- Intuitive interface, which is designed to make the process of validating extracted invoice data very efficient for AP teams.Adapts to different invoice layouts without requiring templates, which is its core strength.High accuracy on standard documents.
- Its primary focus on AP means it may be less flexible for a wide range of custom, non-financial document types compared to more general-purpose IDP platforms.While excellent at extraction and validation, it may offer less extensive no-code workflow customization for complex, multi-stage approval processes compared to some competitors.
- Offers a free trial; paid plans are customized based on document volume.
- Integrates with numerous ERP systems such as SAP, QuickBooks, and Microsoft Dynamics.
- AI-powered OCR for invoice data extraction.An intuitive, user-friendly interface for data validation.Automated data validation checks.
Best use-cases: Automating the extraction and validation of data from vendor invoices for accounts payable teams who prioritize a fast and efficient validation experience.
Ideal customers: Mid-market and enterprise companies with a high volume of invoices who want to improve the efficiency and accuracy of their AP department.
3. Klippa DocHorizon
Klippa DocHorizon is an AI-powered data extraction platform designed to automate document processing workflows with a strong emphasis on security and compliance.
- Pros:
- A key differentiator is its focus on security, with features like document verification to detect fraudulent documents and the ability to cross-check data with external registries.Offers data anonymization and masking capabilities, which are critical for organizations in regulated industries needing to comply with privacy laws like GDPR.
- Documentation could be more detailed, which may present a challenge for development teams during integration.
- Pricing is available upon request and is typically customized for the use case.
- Integrates with a wide range of ERP and accounting systems including Oracle NetSuite, Xero, and QuickBooks.
- AI-powered OCR with a focus on fraud detection.Automated document classification.Data anonymization and masking for compliance.
Best use cases: Processing sensitive documents where compliance and fraud detection are paramount, such as invoices in finance, identity documents for KYC processes, and expense management.
Ideal customers: Organizations in finance, legal, and other regulated industries that require a high degree of security and data privacy in their document processing workflows.
4. Tungsten Automation (formerly Kofax)
Tungsten Automation provides an intelligent automation software platform that includes powerful document capture and processing capabilities, often as part of a broader digital transformation initiative.
- Pros:
- Offers a broad suite of tools that go beyond IDP to include Robotic Process Automation (RPA) and process orchestration, allowing for true end-to-end business process transformation.The platform is highly scalable and well-suited for large enterprises with a high volume and variety of complex, often global, business processes.
- Initial setup can be complex and may require specialized knowledge or professional services. The total cost of ownership is a significant investment.While powerful, it is often seen as a heavy-duty IT solution that is less agile for business teams who want to quickly build and modify their own workflows without developer involvement.
- Enterprise pricing requires a custom quote.
- Integrates with a wide range of enterprise systems and is often used as part of a larger automation strategy.
- AP Document Intelligence and workflow automation.Integrated analytics and Robotic Process Automation (RPA).Cloud and on-premise deployment options.
Best use cases: Large enterprises looking to implement a broad intelligent automation strategy where document processing is a key component of a larger workflow that includes RPA.
Ideal customers: Large enterprises with complex business processes that are undergoing a significant digital transformation and have the resources to invest in a comprehensive automation platform.
5. ABBYY
ABBYY is a long-standing leader and pioneer in the OCR and document capture space, offering a suite of powerful, enterprise-grade IDP tools like Vantage and FlexiCapture.
- Pros:
- Highly accurate recognition engine, can handle a vast number of languages and complex documents, including those with cursive handwriting.The software is robust and can handle a wide range of document types with impressive accuracy, particularly structured and semi-structured forms.It is engineered for high-volume, mission-critical environments, offering the robustness required by large, multinational corporations for tasks like global shared service centers and digital mailrooms.
- The initial setup and configuration can be a significant undertaking, often requiring professional services or a dedicated internal team with specialized skills.The total cost of ownership is at the enterprise level, making it less accessible and often prohibitive for small to mid-sized businesses that do not require its full suite of capabilities.
- Enterprise pricing requires a custom quote.
- Offers a wide range of connectors and a robust API for integration with major enterprise systems like SAP, Oracle, and Microsoft.
- Advanced OCR and ICR for high-accuracy handwriting extraction.Automated document classification and separation for handling complex, multi-document files.A low-code/no-code "skill" designer that allows business users to train models for custom document types.
Best use cases: ABBYY is ideal for large, multinational corporations with complex, high-volume document processing needs. This includes digital mailrooms, global shared service centers for finance (AP/AR), and large-scale digitization projects for compliance and archiving.
Ideal customers: The ideal customers are Fortune 500 companies and large government agencies, particularly in document-intensive sectors like banking, insurance, transportation, and logistics, that require a highly scalable and customizable platform with extensive language and format support.
6. Amazon Textract
Amazon Textract is a machine learning service that automatically extracts text, handwriting, and data from scanned documents, leveraging the power of the AWS cloud.
- Pros:
- Benefits from AWS's powerful infrastructure and integrates seamlessly with the entire AWS ecosystem (S3, Lambda, SageMaker), a major advantage for companies already on AWS.It is highly scalable and goes beyond simple OCR to identify the contents of fields in forms and information stored in tables.
- It is a developer-focused API/service, not a ready-to-use business application. Building a complete workflow with validation and approvals requires significant custom development effort.The pay-as-you-go pricing model, while flexible, can be challenging to predict and control for businesses with fluctuating document volumes.
- Pay-as-you-go pricing based on the number of pages processed.
- Deep integration with AWS services like S3, Lambda, and SageMaker.
- Pre-trained models for invoices and receipts.Advanced extraction for tables and forms.Signature detection and handwriting recognition.
Best use cases: Organizations already invested in the AWS ecosystem that have developer resources to build custom document processing workflows powered by a scalable, managed AI service.
Ideal customers: Tech-savvy companies and enterprises with strong development teams that want to build custom, AI-powered document processing solutions on a scalable cloud platform.
d. Open-Source components
For organizations with in-house technical teams considering a "build" approach for a custom pipeline or RAG application, a rich ecosystem of open-source components is available. These are not end-to-end platforms but provide the foundational technology for developers. The landscape can be broken down into three main categories:
1. Foundational OCR engines
These are the fundamental libraries for the essential first step: converting pixels from a scanned document or image into raw, machine-readable text. They do not understand the document's structure (e.g., the difference between a header and a line item), but it is a prerequisite for processing any non-digital document.
Examples:
- Tesseract: The long-standing, widely-used baseline OCR engine maintained by Google, supporting over 100 languages.PaddleOCR: A popular, high-performance alternative that is also noted for its strong multilingual capabilities.
2. Layout-aware and LLM-ready conversion libraries
This modern category of tools goes beyond raw OCR. They use AI models to understand a document's visual layout (headings, paragraphs, tables) and convert the entire document into a clean, structured format like Markdown or JSON. This output preserves the semantic context and is considered "LLM-ready," making it ideal for feeding into RAG pipelines.
Examples:
- DocStrange: A versatile library that converts a universal set of document types (PDFs, Word, etc.) into LLM-optimized formats and can extract specific fields using AI without pre-training.Docling: An open-source package from IBM that uses state-of-the-art models for layout analysis and table recognition to produce high-quality, structured output.Unstructured: A popular open-source library specifically designed to pre-process a wide variety of document types to create clean, structured text and JSON, ready for use in data pipelines.
3. Specialized extraction libraries
Some open-source tools are built to solve one specific, difficult problem very well, making them invaluable additions to a custom-built workflow.
Examples:
- Tabula: A go-to utility, frequently recommended in user forums, for the specific task of extracting data tables from text-based (not scanned) PDFs into a clean CSV format.Stanford OpenIE: A well-regarded academic tool for a different kind of extraction: identifying and structuring relationships (subject-verb-object triplets) from sentences of plain text.GROBID: A powerful, specialized tool for extracting bibliographic data from scientific and academic papers.
Buying an off-the-shelf product is often considered the fastest route to value, while building a custom solution avoids vendor lock-in but requires a significant upfront investment in talent and capital. The root cause of many failed digital transformations is this "overly simplistic binary choice." Instead, the right choice often depends entirely on the problem being solved and the organization's specific circumstances.
You may wonder why you can't simply use ChatGPT, Gemini, or any other models for document data extraction. While these LLMs are impressive and do power modern IDP systems, they're best understood as reasoning engines rather than complete business solutions.
Research has identified three critical gaps that make raw LLMs insufficient for enterprise document processing:
1. General-purpose models struggle with the messy reality of business documents; even slightly crooked scans can cause hallucinations and errors.
2. LLMs lack the structured workflows needed for business processes, with studies showing that they need human validation to achieve reliable accuracy.
3. Using public AI models for sensitive documents poses significant security risks.
Wrapping up: Your path forward
Automated data extraction is no longer just about reducing manual entry or digitizing paper. The technology is rapidly evolving from a simple operational tool into a core strategic function. The next wave of innovation is set to redefine how all business departments—from finance to procurement to legal—access and leverage their most valuable asset: the proprietary data trapped in their documents.
Emerging trends to watch
- The rise of the "data extraction layer": As seen in the most forward-thinking enterprises, companies are moving away from ad-hoc scripts and point solutions. Instead, they are building a centralized, observable data extraction layer. This unified platform handles all types of data ingestion, from APIs to documents, creating a single source of truth for downstream systems.From extraction to augmentation (RAG): The most significant trend of 2025 is the shift from just extracting data to using it to augment Large Language Models in real-time. The success of Retrieval-Augmented Generation is entirely dependent on the quality and reliability of this extracted data, making high-fidelity document processing a prerequisite for trustworthy enterprise AI.Self-healing and adaptive pipelines: The next frontier is the development of AI agents that not only extract data but also monitor for errors, adapt to new document formats without human intervention, and learn from the corrections made during the human-in-the-loop validation process. This will further reduce the manual overhead of maintaining extraction workflows.
Strategic impact on business operations
As reliable data extraction becomes a solved problem, its ownership will shift. It will no longer be seen as a purely technical or back-office task. Instead, it will become a business intelligence engine—a source of real-time insights into cash flow, contract risk, and supply chain efficiency.
The biggest shift is cultural: teams in Finance, Procurement, and Operations will move from being data gatherers to data consumers and strategic analysts. As noted in a recent McKinsey report on the future of the finance function, automation is what allows teams to evolve from "number crunching to being a better business partner".
Key takeaways:
- Clarity is the first step: The market is fragmented. Choosing the right tool begins with correctly identifying your primary data source: a website, a database, or a document.AI readiness starts here: High-quality, automated data extraction is the non-negotiable foundation for any successful enterprise AI initiative, especially for building reliable RAG systems.Focus on the workflow, not just the tool: The best solutions provide an end-to-end, no-code workflow—from ingestion and validation to final integration—not just a simple data extractor.
Closing thought: Your path forward is not to schedule a dozen demos. It's designed to conduct a simple yet powerful test.
- First, gather 10 of your most challenging documents from at least five different vendors.Then, your first question to any IDP vendor should be: "Can your platform extract the key data from these documents right now, without me building a template?"
Their answer, and the accuracy of the live result, will tell you everything you need to know. It will instantly separate the brilliant, template-agnostic platforms from the rigid, legacy systems that are not built for the complexity of modern business.
FAQs
How is data extracted from handwritten documents?
Data is extracted from handwriting using a specialized technology called Intelligent Character Recognition (ICR). Unlike standard OCR, which is trained on printed fonts, ICR uses advanced AI models that have been trained on millions of diverse handwriting samples. This allows the system to recognize and convert various cursive and print styles into structured digital text, a key capability for processing documents like handwritten forms or signed contracts.
How should a business measure the accuracy of an IDP platform?
Accuracy for an IDP platform is measured at three distinct levels. First is Field-Level Accuracy, which checks if a single piece of data (e.g., an invoice number) is correct. Second is Document-Level Accuracy, which measures if all fields on a single document are extracted correctly. The most important business metric, however, is the Straight-Through Processing (STP) Rate—the percentage of documents that flow from ingestion to export with zero human intervention.
What are the common pricing models for IDP software?
The pricing models for IDP software typically fall into three categories: 1) Per-Page/Per-Document, a simple model where you pay for each document processed; 2) Subscription-Based, a flat fee for a set volume of documents per month or year, which is common for SaaS platforms; and 3) API Call-Based, common for developer-focused services like Amazon Textract where you pay per request. Most enterprise-level plans are custom-quoted based on volume and complexity.
Can these tools handle complex tables that span multiple pages?
This is a known, difficult challenge that basic extraction tools often fail to handle. However, advanced IDP platforms use sophisticated, vision-based AI models to understand table structures. These platforms can be trained to recognize when a table continues onto a subsequent page and can intelligently "stitch" the partial tables together into a single, coherent dataset.
What is zero-shot data extraction?
Zero-shot data extraction refers to an AI model's ability to extract a field of data that it has not been explicitly trained to find. Instead of relying on pre-labeled examples, the model uses a natural language description (a prompt) of the desired information to identify and extract it. For example, you could instruct the model to find the policyholder's co-payment amount. This capability dramatically reduces the time needed to set up new or rare document types.
How does data residency (e.g., GDPR, CCPA) affect my choice of a data extraction tool?
Data residency and privacy are critical considerations. When choosing a tool, especially a cloud-based platform, you must ensure the vendor can process and store your data in a specific geographic region (e.g., the EU, USA, or APAC) to comply with data sovereignty laws like GDPR. Look for vendors with enterprise-grade security certifications (like SOC 2 and HIPAA) and a clear data governance policy. For maximum control over sensitive data, some enterprise platforms also offer on-premise or private cloud deployment options.
