
Hey all, Alex here 👋
This week, while not the busiest week in releases (we can't get a SOTA LLM every week now can we), was full of interesting open source releases, and feature updates such as the chatGPT meetings recorder (which we live tested on the show, the limit is 2 hours!)
It was also a day after our annual W&B conference called FullyConnected, and so I had a few goodies to share with you, like answering the main question, when will W&B have some use of those GPUs from CoreWeave, the answer is... now! (We launched a brand new preview of an inference service with open source models)
And finally, we had a great chat with Pankaj Gupta, co-founder and CEO of Yupp, a new service that lets users chat with the top AIs for free, while turning their votes into leaderboards for everyone else to understand which Gen AI model is best for which task/topic. It was a great conversation, and he even shared an invite code with all of us (I'll attach to the TL;DR and show notes, let's dive in!)
Open Source AI: China at the Helm, Benchmarks Reborn
Just a year ago, a 16K context window was astonishing. Now? The big action is one million tokens and “stochastic people-spirits” that claim to rival world-class coders. Here are the highlights:
Moonshot AI Kimi-Dev-72B: Coding’s New Open-Source Champion? (HF | Github)

Meet Kimi-Dev-72B : an open weights LLM, optimized specifically for software engineering, and it isn’t shy: 60.4% on SWE-bench Verified, making it the new open-source SOTA for coding benchmarks.
The trick? Kimi doesn’t just spit answers—it's trained to patch actual GitHub repos inside Docker, gets a reward only when full test suites pass. That’s serious RL polish. But—and here’s the rub—outside its comfort zone (i.e., writing or general Q&A), it’s not as strong. The moment you step outside SWE-bench, expect a drop-off. Several in the AllHands community have already prodded at the “fixed workflow” design and found inconsistency versus real-world tooling, especially for broader agentic tasks.
So, huge respect for pushing the coding benchmark ceiling, but as ever: vibe ≠ pure leaderboard—so test for your use case, not just the tweetable score.
MiniMax-M1: The New 1M-Context, 456B-Param Reasoning Titan (paper | HF | Demo)
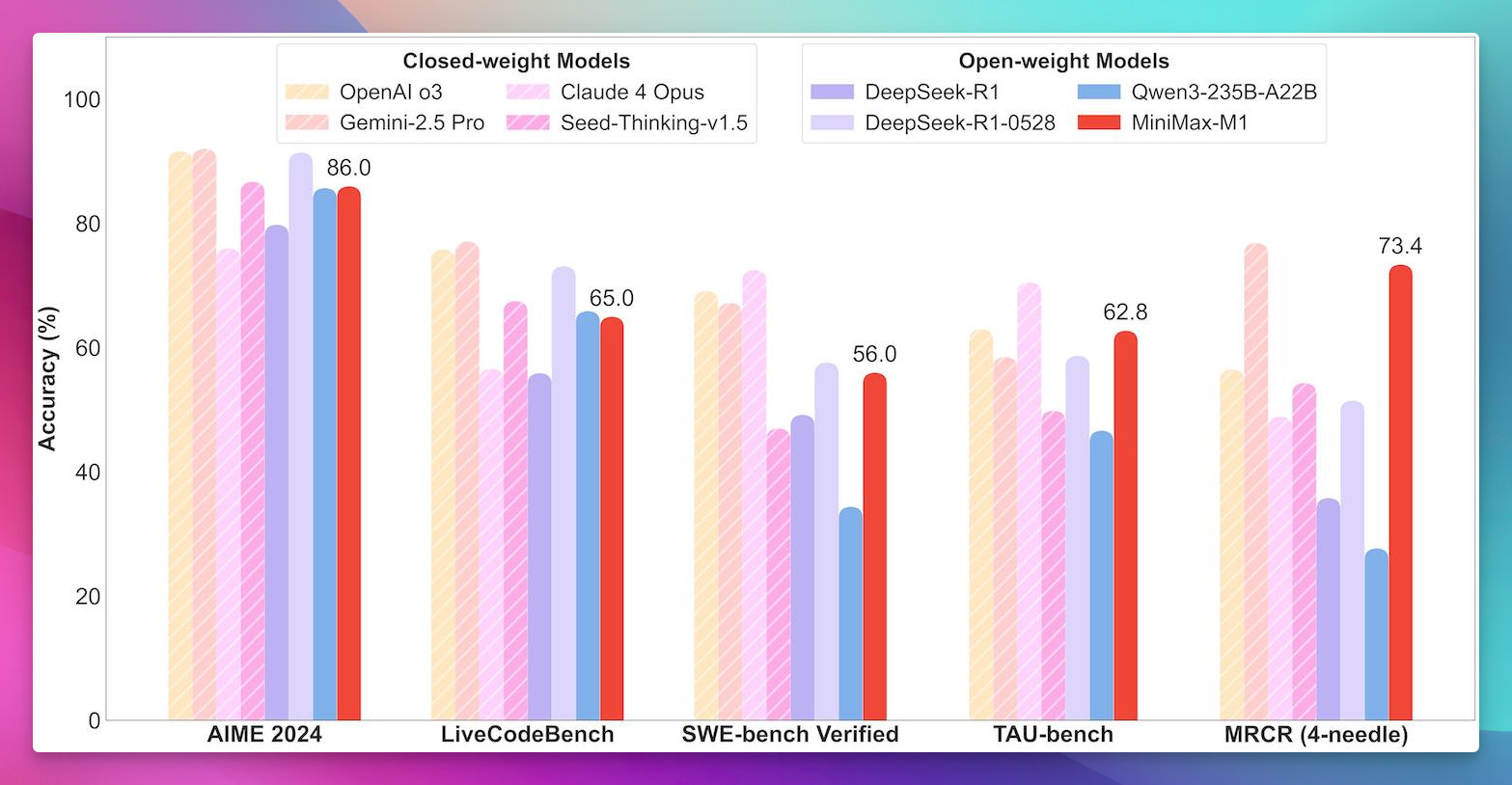
If there’s one model everyone buzzed about, it’s MiniMax-M1. In a field packed with megamodels, M1 stands out not just for its 456 billion total parameters (45B active per forward pass), but for:
1 Million native context window—yes, native. Not some “theoretical” post-training RoPE hack.
Hybrid mixture of experts paired with lightning attention; delivers 8x the context of DeepSeek R1 at a fraction of the compute.
Trained “fast and cheap” (by AI standards): 3 weeks, 512 H800s, about $534k. That’s under 10% of what you’d expect for models this size.
Open-source, Apache 2 license, “try-me-now” APIs, and 2 versions: 40K and 80K reasoning token budgets
Benchmarks:
SWEBench Verified: 56.0
AIME 2024 (math): 86.0
FullStackBench (coding): 68.3
Long Context Reasoning: 73.4 on OpenAI’s MRCR (128k) and 58 on the 1 million version—putting it on par with closed Gemini models and miles ahead of almost everything else open-weight.
Though, numbers aside, I've tried it (leaning on the impressive long context) and I got some... interesting results. The thinking part of it was great, but it wasn't at all good at keeping with my instructions, or my writing style. It in fact didn't adhere to my style at all. But hey, different models serve different purposes right?
Open Source: The China Shift
If you’re following the pattern, you’ll notice that the open-source frontier is almost entirely being led by Chinese labs: Qwen, DeepSeek, MiniMax, Moonshot. Restrictions are real, but progress is relentless. If you’re building on top of OSS AI, it’s time to get comfortable reading Hugging Face and Github docs in translation.
Big Companies, APIs & LLMs
Gemini 2.5: From Preview to Production
Google made moves this week, graduating Gemini 2.5 Flash and Pro from preview to general availability. But the real star is the new Flash-Lite model in preview.
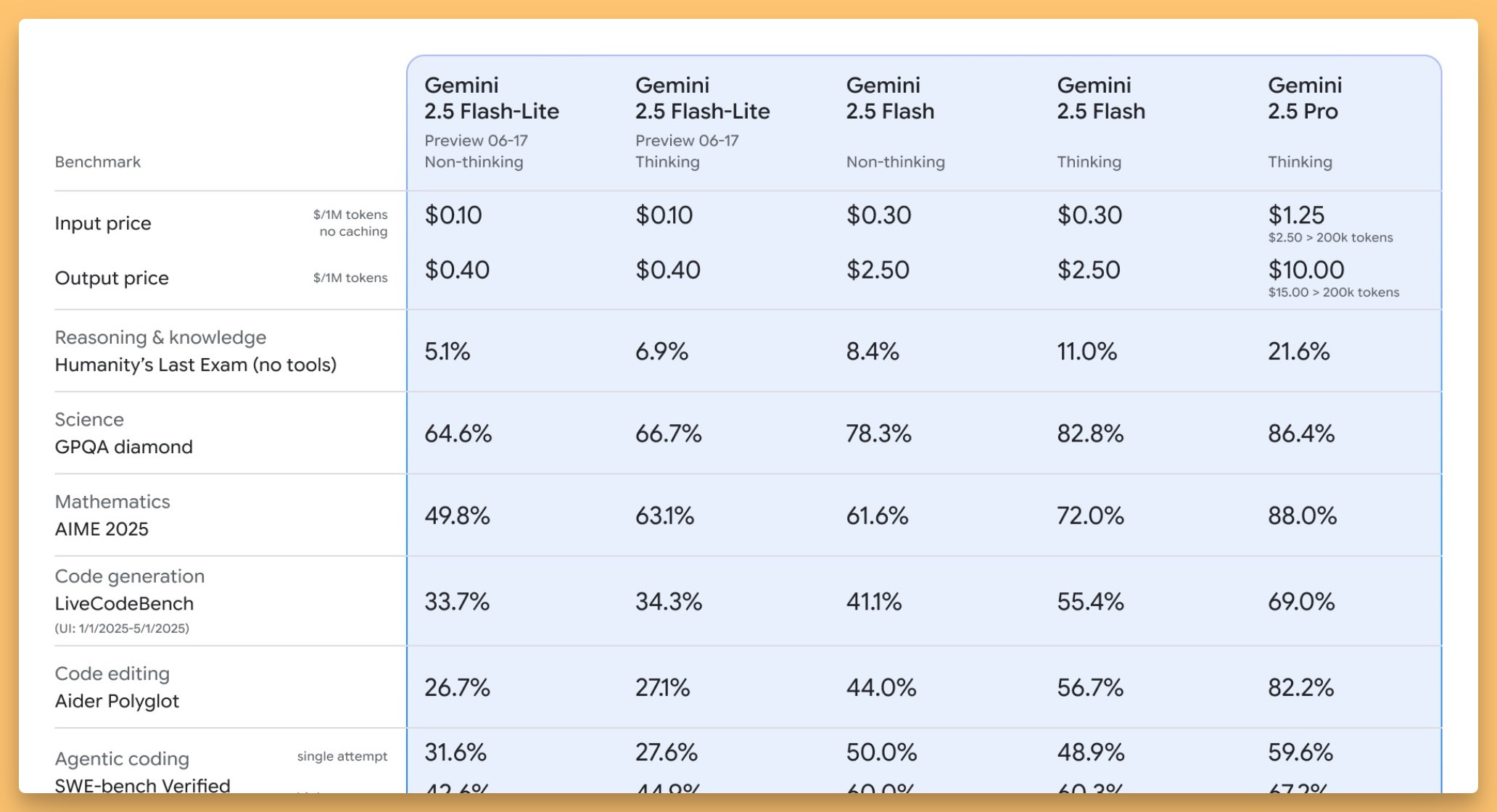
Wolfram immediately put Flash-Lite into production for his home automation system and couldn't stop raving about it: "The latency has been reduced when I give a command and the house reacts... even its German is very good!"
At just 10 cents per million input tokens and running at 400+ tokens per second, this tiny reasoning model is finding its niche. Sure, it's not going to win any benchmarks (66% on GPQA Diamond), but for high-volume, low-latency tasks? This is exactly what we needed.
OpenAI: MCP Support and That Meeting Recorder Though...
OpenAI quietly added MCP (Model Context Protocol) support to Deep Research inside ChatGPT, though it's limited to read-only operations with search and fetch tools. What this means, that anyone (and companies) can create a new tool for DeepResearch to connect to, whether it's your company data or a third party service that you want DeepResearch to use.
Though limited to Deep Research only, this shows incredible MCP adoption, and will likely make its way to standard ChatGPT soon.

But the real surprise came when we tested their new meeting recorder feature live during the show. I mean... wow. Not only did it transcribe our entire 2-hour episode perfectly, but it also:
Identified speakers by name (even though some of us never explicitly said our names!)
Created chapter summaries with timestamps
Generated action items for listeners
Formatted everything beautifully in Canvas
Yam's reaction said it all: "That's crazy useful! Seriously, that's crazy!"
The model diarized (speaker identification) and took the names from the context, which was really awesome. So when I introduced myself as Alex Volkov during the show, or my Guest Pankaj, it identified those names and then applied them to "speaker 01" and "speaker 02" as labels. It did mess up thought, attributing Nistens name to Pankaj voice, leading to some funny hallucinations in summary, making Nisten the CEO of Yupp. 😅 But hey, it's a research preview!
Zuck is on a spending spree:
Lastly, a quick Meta update—Zuck’s on a spending spree, and word is he’s eyeing Nat Friedman and Daniel Gross, powerhouse investors with a killer AI portfolio, to join Meta’s superintelligence push. After last week’s Scale AI move, this signals big ambitions. I’m watching this space closely!
🐝 This Week’s Buzz: Weights & Biases Drops Game-Changing Tools at Fully Connected

Alright, time for some home team news from Weights & Biases Weave, and I’m pumped to share what went down at our Fully Connected conference. We hosted a great event with way more people than we had room for—and unveiled some seriously cool stuff since joining forces with CoreWeave. Two big launches stand out, and I’m itching to see how you’ll use them.
First, W&B Inference is here in preview, giving you a unified interface to run top open-source models like DeepSeek R1-0528 and Phi 4 Mini 3.8B directly from our platform, backed by CoreWeave GPUs. Pricing is competitive, and even free-tier users get credits to play around. Whether through our playground for side-by-side comparisons or an OpenAI-compatible API, it’s seamless. I’m all about making powerful AI accessible, and this is a step in that direction.
Second, for my evaluation nerds out there (you know I’m one of them!), W&B Weave now supports Online Evaluations. This means real-time monitoring of production calls with an LLM as a judge—set it up in minutes to track performance drops on a subset of your traces. You can use our inference service or plug in your own keys from OpenAI, Anthropic, or others. It’s a game-changer for deploying AI reliably, and I walked through the setup live on the show. Both tools tie into our “metal-to-token” observability vision, tracking everything from hardware to application metrics. Try them out and hit me up with feedback—I’m all ears!
Evaluation Revolution: Enter Yupp.ai

Speaking of evaluations, we had Pankaj Gupta, co-founder and CEO of Yup.ai, join us to discuss their fresh take on model evaluation.
What makes Yup different:
Users get access to 500+ models for free (including GPT-4.5, Claude Opus 4, even o3-Pro!)
Gamified feedback system - earn credits by rating model outputs
Detailed leaderboards you can slice by task type, model family, even user demographics
"Vibe scores" that capture those intangible qualities we discuss every week on ThursdAI
Because this is a real product (that's VERY polished), and users are incentivized to build their profiles, not to mention, getting paid, they can do analysis on age, profession, location of users. So for example, this is the first place I know of, that can tell me what's the best model that young users prefer (currently Gemini Flash Lite!)
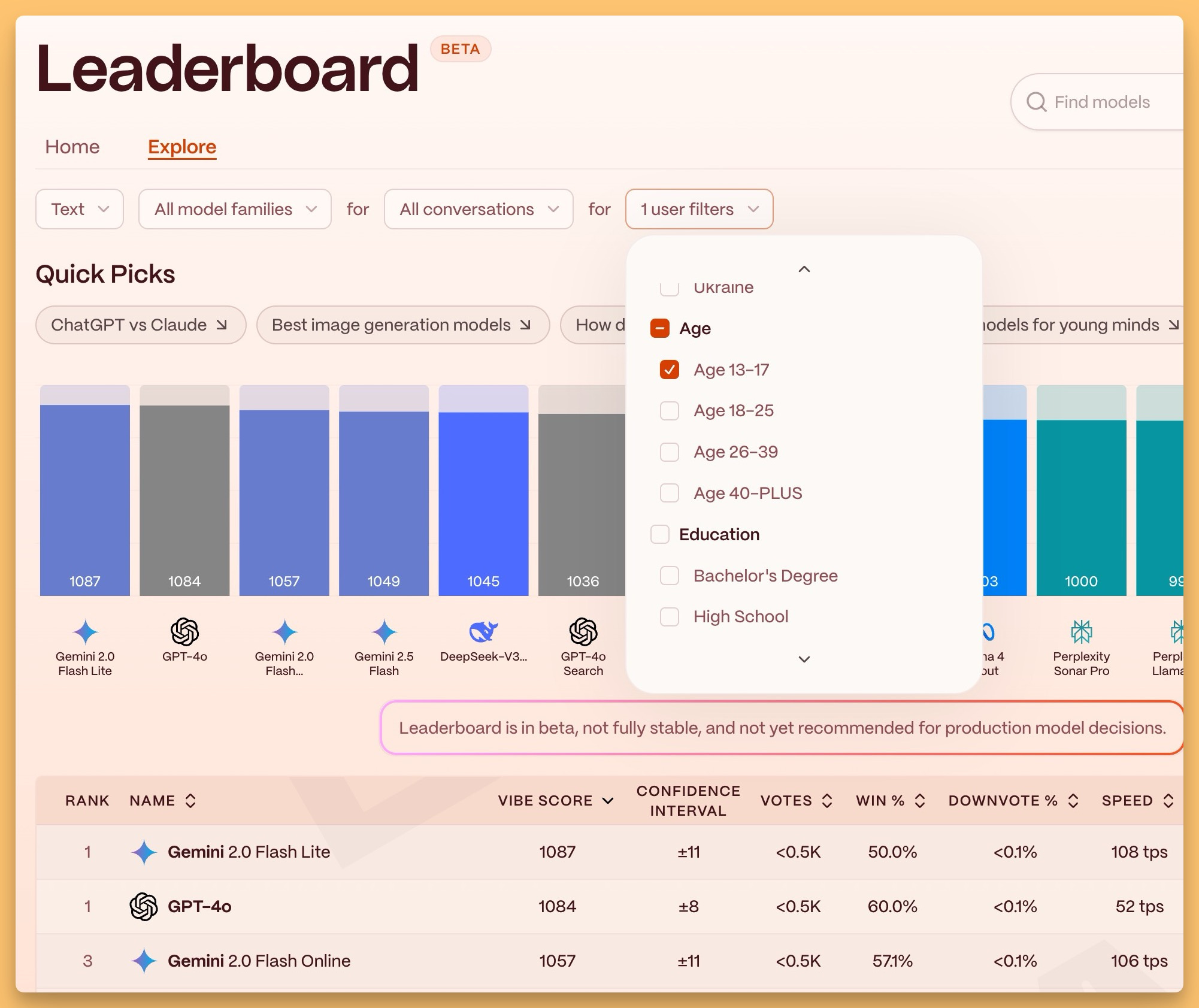
The platform launched less than a week ago and already has 400,000+ conversations for evaluation, and we'll be definitely taking a look, as its angels include folks like Jeff Dean from DeepMind and Josh Woodward and many other AI minds!
Arenas and Vibes?

Just as I'm writing this, the information disclosed that while LMArena claims to be impartial, more and more companies are asking Surge (a data labeling provider, which is a competitor to Scale) for data for LMArena optimization. This, in addition to the Cohere paper about LMArena from before, and our general vibes differences + their recent $100M funding round, makes me think that we need a few new places for Vibes from LLMs. I'm hoping Yupp can be that place personally.
If you'd like an invite and a few extra credits there, Pankaj gave all listeners of ThursdAI an invite ahead of the rest of the pack. Click here and enjoy rating models!*
Vision & Video: The Week 1080p Went Mainstream

Video models have been heating up, and oh boy, this week was a massive shakeup! VEO3 went from 1st to ... third, and A16Z showed their first AI Video market map.
ByteDance Seedance 1.0 (and Mini)
TikTok’s parent finally flexed its video data moat. Seedance 1 shot straight to #1 on the Artificial Analysis arena — beating Google Veo 3 in text-to-video and image-to-video. It still outputs 768p, but frame-by-frame sharpness and prompt coherence are ridiculous. While you can't use it directly today, you can test drive it's smaller brother (Seedance 1.0-mini) on Dreamina or Fal (they are calling it lite)
MiniMax Hailuo 02: Native 1080p, Physics-Aware Clips
Not to be out-performed, the same MiniMax team behind the M1 LLM pushed Hailuo 02. Native 1080p, 6-second clips, and an instruction parser that finally obeys camera moves (“slow pan left across a floating sushi conveyor” worked first try). Training tricks: Noise-aware Compute Redistribution (NCR) plus 4× the dataset of Hailuo 01. Early testers report 2.5× inference throughput over Veo at a fraction of the cost.
Midjourney Video V1
Midjourney fans, you’re now animated. The first web-only video beta turns any image into four five-second videos. It’s 480 p and costs 8× an image job, but the “MJ aesthetic” survives intact, which no one else matches yet. Just look at this crazy video someone just posted on X, it keeps the collage effect very well!
Voice Tech Breakthroughs: Kyutai’s Real-Time Speech-to-Text (X, website)
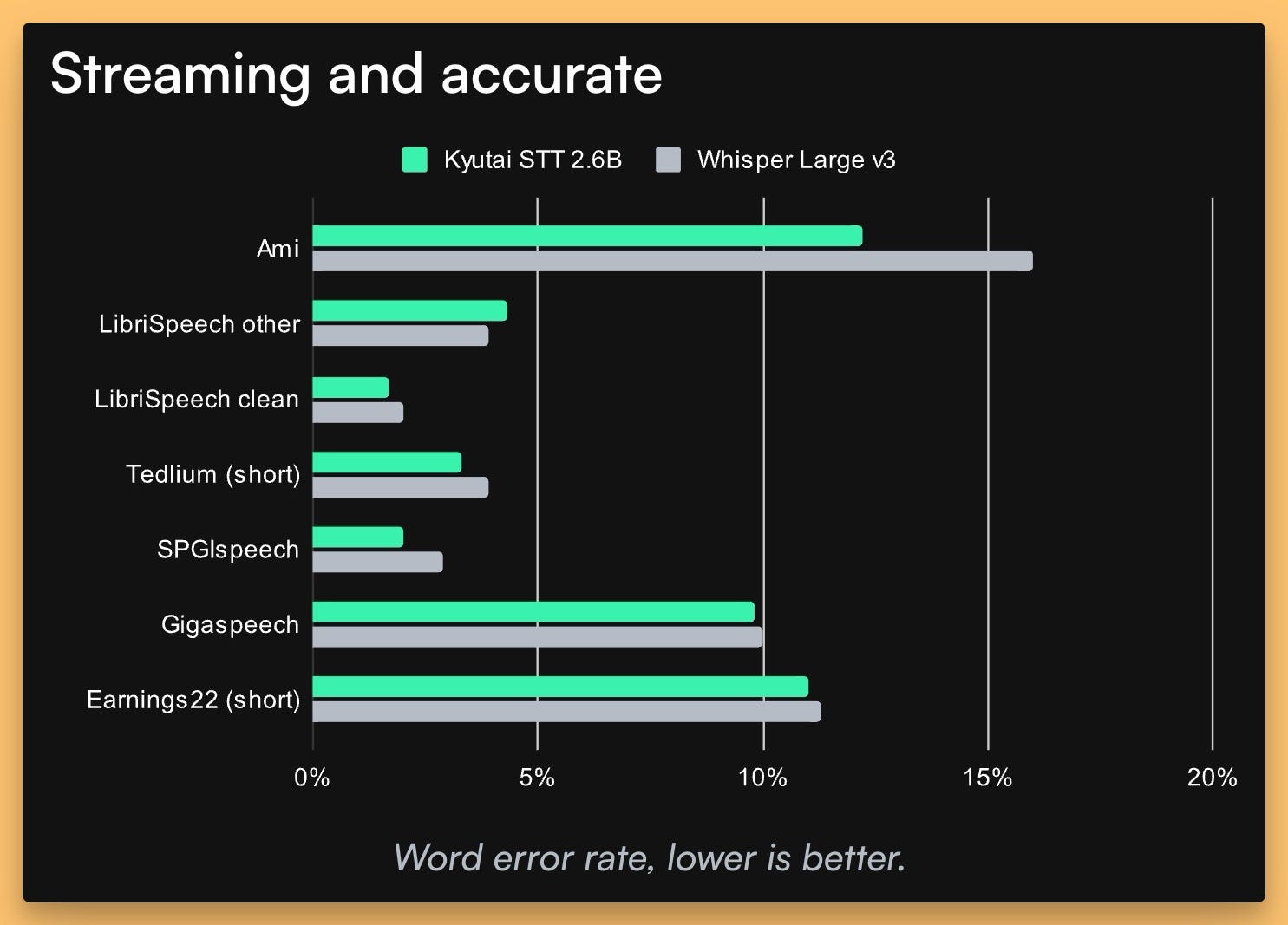
On the audio front, Kyutai, a French company we’ve hyped before for Moshi, just launched two open-source Speech-to-Text models that are turning heads. They’ve got a 2.6B parameter English-only model that outperforms Whisper Large v3 on benchmarks, and a 1B parameter English/French version optimized for low-latency at just 500ms delay.
What’s cool is the real-time streaming—transcribing as you speak, not after a buffer, with a semantic voice activity detector to know when you’ve stopped. It can handle up to 400 concurrent streams on a single H100 GPU! I see this as a hidden gem for voice chat apps or live transcription. Give it a try yourself here
Research and Tools Shaking Things Up: From Cognitive Concerns to Crowd-Powered Evals
Wrapping up, let’s touch on some research and tools that caught my eye. A new benchmark, LiveCodeBench Pro, dropped a bombshell—top LLMs like o4-mini-high score 0% on hard real-world coding contest problems from Codeforces and IOI, lagging at 2,100 Elo compared to human grandmasters at 2,700. It’s a stark reminder that while AI shines on routine tasks, deep logic and creativity are still human territory. Dive into the paper for the gritty details.

On a more sobering note, an MIT study with just 54 participants suggests frequent ChatGPT use might cause cognitive decline, showing a 47% drop in neural connections and memory retention issues after four months. It’s a small sample, but it raises questions about over-reliance on AI—something to chew on as we integrate these tools deeper into our lives.

Andrej Karpathy’s latest talk on “Software 3.0” is pure inspiration, framing English as the new programming language with LLMs as operating systems. It’s a vision of “vibe coding” democratizing software for billions—definitely worth a watch for any AI dreamer out there.
That's it, even for a realtively chill week, we've had an amazing show! Next week, I'm on vacation, and Wolfram and the gang will lead the show! Don't have too much fun without me yea? 😎 I'll be tuning in as a listener maybe.
Here's the TL;DR and show notes links
ThursdAI - June 19th, 2025 - TL;DR
Hosts and Guests
Alex Volkov - AI Evangelist & Weights & Biases (@altryne)
Co Hosts - @WolframRvnwlf @yampeleg @nisten @ldjconfirmed
Open Source LLMs
Moonshot AI open-sourced Kimi-Dev-72B (Github, HF)
MiniMax-M1 456B (45B Active) - reasoning model (Paper, HF, Try It, Github)
Big CO LLMs + APIs
Google drops Gemini 2.5 Pro/Flash GA, 2.5 Flash-Lite in Preview ( Blog, Tech report, Tweet)
Google launches Search Live: Talk, listen and explore in real time with AI Mode (Blog)
OpenAI adds MCP support to Deep Research in chatGPT (X, Docs)
OpenAI launches their meetings recorder in mac App (docs)
Zuck update: Considering bringing Nat Friedman and Daniel Gross to Meta (information)
This weeks Buzz
NEW! W&B Inference provides a unified interface to access and run top open-source AI models (inference, docs)
NEW! W&B Weave Online Evaluations delivers real-time production insights and continuous evaluation for AI agents across any cloud. (X)
The new platform offers "metal-to-token" observability, linking hardware performance directly to application-level metrics.
Vision & Video
ByteDance new video model beats VEO3 - Seedance.1.0 mini (Site, FAL)
MiniMax Hailuo 02 - 1080p native, SOTA instruction following (X, FAL)
Midjourney video is also here - great visuals (X)
Voice & Audio
Kyutai launches open-source, high-throughput streaming Speech-To-Text models for real-time applications (X, website)
Studies and Others
LLMs Flunk Real-World Coding Contests, Exposing a Major Skill Gap (Arxiv)
MIT Study: ChatGPT Use Causes Sharp Cognitive Decline (Arxiv)
Andrej Karpathy's "Software 3.0": The Dawn of English as a Programming Language (youtube, deck)
Tools
Yupp launches with 500+ AI models, a new leaderboard, and a user-powered feedback economy - use thursdai link* to get 50% extra credits
BrowserBase announces director.ai - an agent to run things on the web
Universal system prompt for reduction of hallucination (from Reddit)
*Disclosure: while this isn't a paid promotion, I do think that yupp has a great value, I do get a bit more credits on their platform if you click my link and so do you. You can go to yupp.ai and register with no affiliation if you wish.
