
Hey everyone, Alex here 👋
This week looked quiet… until about 15 hours before we went live. Then the floodgates opened: DeepSeek dropped a hybrid V3.1 that beats their own R1 with fewer thinking tokens, ByteDance quietly shipped a 36B Apache-2.0 long-context family with a “thinking budget” knob, NVIDIA pushed a faster mixed-architecture 9B with open training data, and a stealth image editor dubbed “Nano Banana” started doing mind-bending scene edits that feel like a new tier of 3D-aware control.
On the big-co side, a mystery “Sonic” model appeared in Cursor and Cline (spoiler: the function call paths say a lot), and OpenAI introduced Agents.md to stop the config-file explosion in agentic dev tools. We also got a new open desktop-agent RL framework that 4x’d OSWorld SOTA, an IBM + NASA model for solar weather, and Qwen’s fully open 20B image editor that’s shockingly capable and runnable on your own GPU.
Our show today was one of the shortest yet, as I had to drop early to prepare for Burning Man 🔥🕺 Speaking of which, Wolfram and the team will host the next episode!
Ok, let's dive in!
DeepSeek V3.1: a faster hybrid that thinks less, scores more (X, HF)
DeepSeek does this thing where they let a base artifact “leak” onto Hugging Face, and the rumor mill goes into overdrive. Then, hours before we went live, the full V3.1 model card and an instruct variant dropped. The headline: it’s a hybrid reasoner that combines the strengths of their V3 (fast, non-thinking) and R1 (deep, RL-trained thinking), and on many tasks it hits R1-level scores with fewer thinking tokens. In human terms: you get similar or better quality, faster.
A few things I want to call out from the release and early testing:
Hybrid reasoning mode done right. The model can plan with thinking tokens and then switch to non-thinking execution, so you don’t have to orchestrate two separate models. This alone simplifies agent frameworks: plan with thinking on, execute with thinking off.
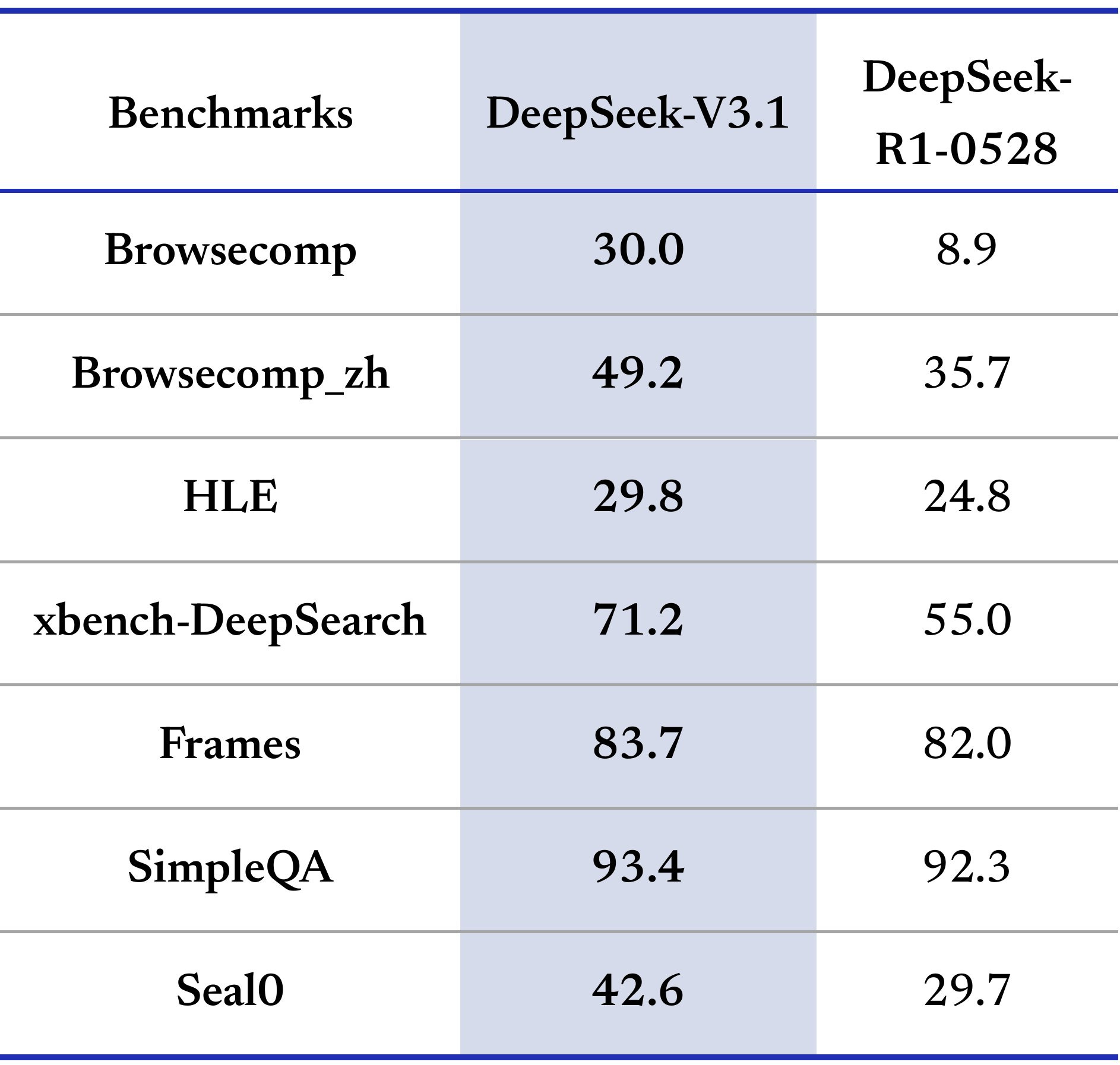
Thinking efficiency is real. DeepSeek shows curves where V3.1 reaches or surpasses R1 with significantly fewer thinking tokens. On AIME’25, for example, R1 clocks 87.5% with ~22k thinking tokens; V3.1 hits ~88.4 with ~15k. On GPQA Diamond, V3.1 basically matches R1 with roughly half the thinking budget.
Tool-use and search-agent improvements. V3.1 puts tool calls inside the thinking process, instead of doing a monologue and only then calling tools. That’s the pattern you want for multi-turn research agents that iteratively query the web or your internal search.
Long-context training was scaled up hard. DeepSeek says they increased the 32K extension phase to ~630B tokens, and the 128K phase to ~209B tokens. That’s a big bet on long-context quality at train time, not just inference-time RoPE tricks. The config shows a max position in the 160K range, with folks consistently running it in the 128K class.
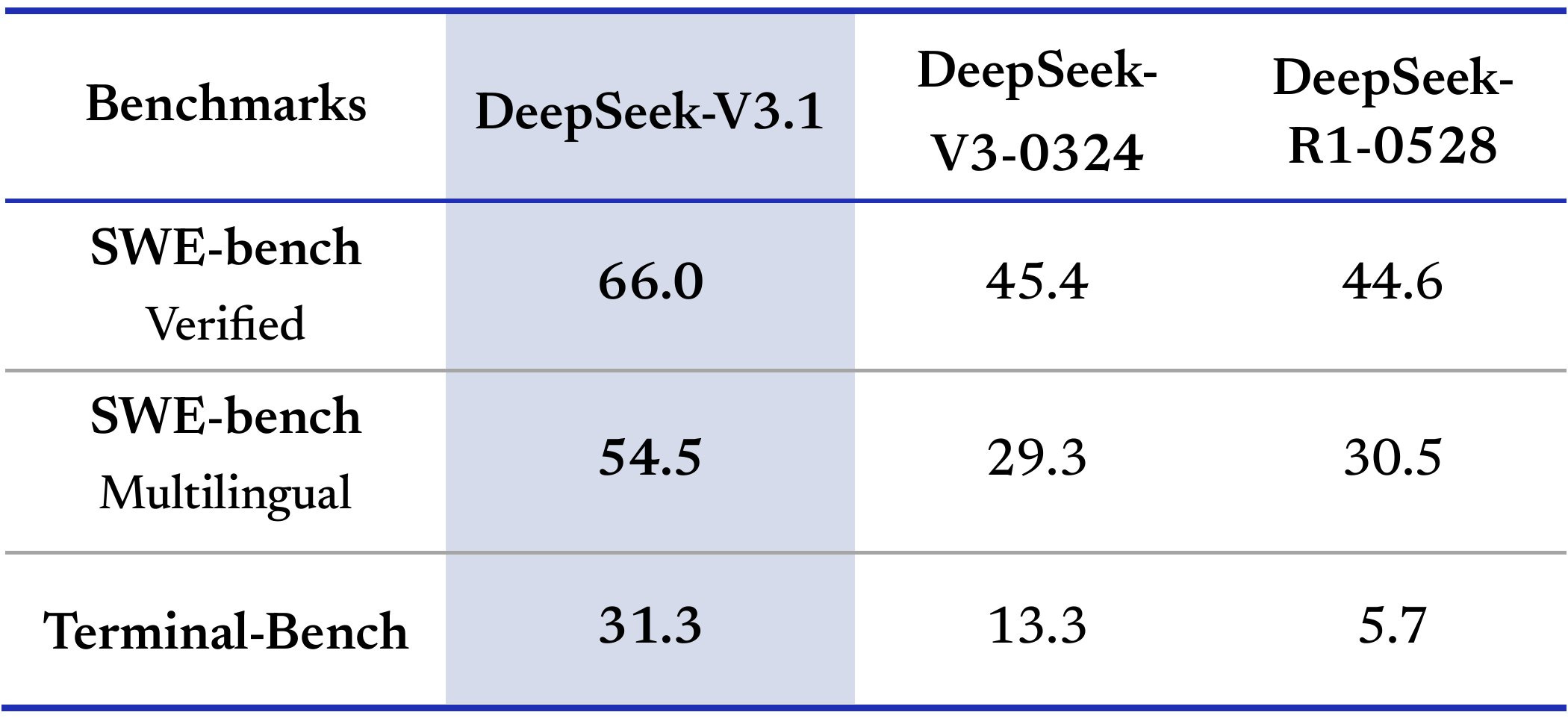
Benchmarks show the coding and terminal agent work got a big push. TerminalBench jumps from a painful 5.7 (R1) to 31 with V3.1. Codeforces ratings are up. On SweBench Verified (non-thinking), V3.1 posts 66 vs R1’s ~44. And you feel it: it’s faster to “get to it” without noodling forever.
API parity you’ll actually use. Their API now supports the Anthropic-style interface as well, which means a bunch of editor integrations “just work” with minimal glue. If you’re in a Claude-first workflow, you won’t have to rewire the world to try V3.1.
License and availability. This release is MIT-licensed, and you can grab the base model on Hugging Face. If you prefer hosted, keep an eye on our inference—we’re working to get V3.1 live so you can benchmark without burning your weekend assembling a serving stack.
Hugging Face: https://huggingface.co/deepseek-ai/DeepSeek-V3.1-Base
Quick personal note: I’m seeing a lot of small, pragmatic improvements add up here. If you’re building agents, the hybrid mode plus tighter tool integration is a gift. DeepSeek V3.1 is going to be deployed to W&B Inference service soon! Take a look here to see when it's ready wandb.me/inference
ByteDance Seed-OSS 36B: Apache-2.0, 512K context, and a “thinking budget” knob (X, HF, Github)

I didn’t see much chatter about this one, which is a shame because this seems like a serious release. ByteDance’s Seed team open-sourced a trio of 36B dense models—two Base variants (with and without synthetic data) and an Instruct model—under Apache-2.0, trained on 12T tokens and built for long-context and agentic use. The context window is a native half-million tokens, and they include a “thinking budget” control you can set in 512-token increments so you can trade depth for speed.
They report strong general performance, long-context RULER scores, and solid code/math numbers for a sub-40B model, with the Instruct variant posting very competitive MMLU/MMLU-Pro and LiveCodeBench results. The architecture is a straightforward dense stack (not MoE), and the models ship with Transformers/vLLM support and 4/8-bit quantization ready to go. If you’ve been hunting for a commercial-friendly, long-context 30-something‑B with an explicit reasoning-control dial, this should be on your shortlist.
A neat detail for the training nerds: two Base releases—one trained with synthetic data, one without—make for a rare apples-to-apples study in how synthetic data shapes base capability. Also worth noting: they previously shipped a Seed-Prover specialized for Lean; it looks like the team is interested in tight domain models and generalists.
NVIDIA Nemotron Nano 9B V2: mixed architecture, open data, and long-context throughput (X, Blog, HF, Dataset, Try It)

NVIDIA shipped a fully open release of Nemotron Nano 9B V2—base, base-before-alignment/pruning, and a realigned reasoning model—and, crucially, they published most of the pretraining dataset details (~6.6T tokens across premium web, math, code, and SFT). That level of data transparency is rare and makes this a great base for fine-tuners who want reproducibility.
Under the hood, this is a mixed Mamba+Transformer architecture. NVIDIA is claiming up to 6x higher throughput versus a pure-Transformer peer (they compare to Qwen3-8B) and specifically highlight that they pruned a 12B down to 9B while preserving quality. They also note a single A10 can handle 128K context after compression and distillation passes, which is the kind of practical systems work that matters when you’re running fleets.
A couple of caveats. The license is NVIDIA Open Model License—not Apache-2.0—so read it; it includes restrictions around illegal surveillance and safety bypasses and has revocation clauses. Personally, I appreciate the data openness and the long-context engineering; as always, just make sure the license fits your use case.
If you’re into longer-context math/coding with small models, the numbers (AIME’25, RULER-128K, GPQA) are impressive for 9B. And if you fine-tune: the availability of both pruned and pre-pruned bases plus the dataset recipe is a rare treat.
Cohere’s Command-A Reasoning: dense, multilingual, and research-only licensing (X, Blog, HF)
Cohere Dropped a new reasoning model focused on enterprise deployment patterns. It’s dense 111B model, supports a 256K context, and includes very strong multilingual coverage (23 languages is what they called out). What caught my eye: on the BFCL (Berkeley Function-Calling Leaderboard) they show 70%—above DeepSeek R1’s ~63% and GPT-OSS’s ~61%—and they plot the now-familiar test-time compute curves where more thinking tokens yield higher scores.
This release uses Cohere’s non-commercial research license; if you want commercial usage you’ll need to go through them. That said, for teams who need privately deployable, on-prem reasoning and can work under a research license for prototyping, it’s a serious option. A meta observation from the show: there’s accumulating evidence that more active parameters help multi-hop tool-use chains compared to very sparse MoE at similar effective capacity. This model nudges in that direction.
Desktop agents leap: ComputerRL hits 48% on OSWorld (Paper)
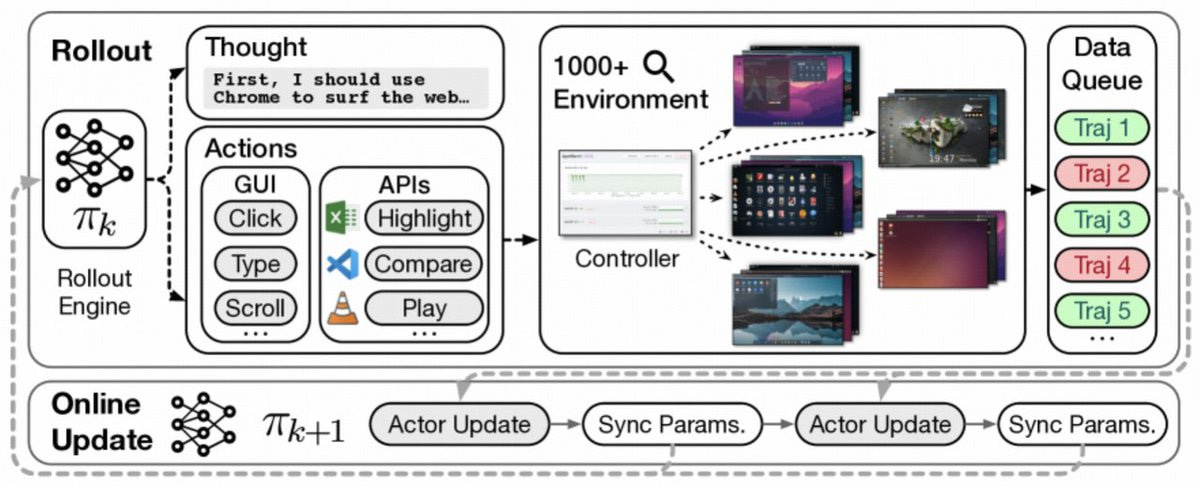
A new framework dubbed ComputerRL from Z.ai and folks at Tsingua Uni, unified API calls with GUI actions and scaled RL across fleets of virtual desktops, posting a 48.1% success rate on OSWorld versus ~12% for earlier open models. The training system spins up thousands of qemu-in-docker VMs via gRPC; the learning loop alternates RL with supervised fine-tuning and uses a clean step-level binary reward to simplify credit assignment. If you care about practical desktop automation across Ubuntu/Windows/macOS, this is a big jump.
IBM + NASA’s Surya: open model for solar weather (HF)

Scientists get some love: IBM and NASA open-sourced Surya, a transformer trained on nine years of multi-instrument observations (nearly 200 TB) to forecast solar dynamics and space weather—the stuff that can knock satellites and power grids sideways. It’s on Hugging Face, it’s actually runnable, and it’s a fantastic example of open models delivering real-world scientific utility.
Smaller but notable: InternLM and OpenCUA, plus Intel’s quants
Two quick flags from the “worth your time” pile. InternLM shipped S1 Mini, an 8B vision+language model (ViT on top) that’s multimodal and lightweight; if you need on-device omni-ish behavior on a laptop or tablet, give it a look. And OpenCUA 32B (Qwen-based) is a specialized computer-usage agent with strong scores; if you’re building automations that need native OS control, it’s worth benchmarking.
Also, if you’re running 4-bit: the Intel quantization work is excellent right now. Their 4-bit quants have been extremely high precision in my testing, especially for large coders and reasoners like DeepSeek V3.1. It’s an easy win if you’re trying to squeeze a 30B+ onto a workstation without hemorrhaging quality.
Big-co updates and platform shifts
Sonic appears in Cursor and Cline
If you open Cursor or fire up Cline, you may see a new “Sonic” model toggle. It’s labeled as a reasoning model and, when you poke the function-calling internals, the call paths include “xai/…” strings. Folks report it’s fast and solid for coding. No official docs yet, but I’d be surprised if this isn’t Grok Code in pre-release clothes.
Agents.md: one file to rule your agents
Agentic dev stacks have multiplied config files like gremlins: Cursor’s rules.json, Windsurf’s prompts, MCP server manifests, tool schemas, install scripts… and every tool wants a different filename and format. OpenAI’s Agents.md is a strong attempt at standardization. It’s just Markdown at repo root that says, “here’s how to set up, build, test, and run this project,” plus any agent-specific caveats. Tools then auto-detect and follow your instructions instead of guessing.
It’s already supported by OpenAI Codex, Amp, Jules, Cursor, RooCode, and more, with tens of thousands of public repos adopting the pattern. In monorepos, the nearest Agents.md wins, so you can override at the package level. And human chat instructions still override the file’s guidance, which is the right default.
GPT‑5 context truncation in the web UI (reports)
There’s been a wave of reports that GPT‑5 in the web UI is truncating long prompts even when you’re under the documented context limit. The folks at Repo Prompt reproduced this multiple times and got confirmation from OpenAI that it’s a bug (not a deliberate nerf). If you saw GPT‑5 suddenly forget the bottom half of your carefully structured system prompt in the web app, this likely explains it. The API doesn’t seem affected. Fingers crossed for a quick fix—GPT‑5 is still the best model I’ve used for 300k‑token “read the whole repo and propose a plan” tasks.
Image and 3D: Nano Banana and Qwen’s open image editor
Nano Banana: 3D-consistent scene editing from thin air

A stealth model nicknamed “Nano Banana” surfaced in a web demo and started doing the kind of edits you’d normally expect from a 3D suite with a modeler at the controls. Take two photos—your living room and a product shot—and it composites the object into the scene with shockingly consistent lighting and geometry. Ask for a 3D mesh “five inches off the skin,” and the mesh really does offset. Ask for a new camera angle on a single still, and it renders the scene from above with plausible structure. People have been calling it a game-changer and, for once, it doesn’t feel like hyperbole.
There’s a strong whiff of 3D world modeling under the hood—some volumetric representation or neural field that enables true view synthesis—and Logan Kilpatrick posted a banana emoji that set speculation on fire. We’ll see where it lands and under what license, but for now the demo has been doing the rounds and it is… wow.

If you’re wondering where to try it: LMarena is the currently only way to give it a try, but it's supossedly dropping soon!
Qwen Image Edit (20B): fully open and already practical (X, HF)
Qwen shipped a 20B image-editing model layered on their existing vision stack, and it’s properly open (permissive license) with strong bilingual text editing in Chinese and English. It handles high-level semantic edits (pose adjustments, rotations, style/IP creation) and low-level touch-ups (add/remove/insert). You can swap objects, expand aspect ratios, keep character identity consistent across panels, and do clean style transfer. It runs locally if you’ve got a decent GPU.
What I appreciate here is the precision. Product placement tasks like “put this book in this person’s hand at this angle,” or “make the shoes match the dress” come out with the kind of control that used to require hand masking and a dozen passes. And yes, the capybara mascot is back in the release materials, which made my day! 👏
If Nano Banana is the closed-world demo of what’s “beyond SOTA,” Qwen Image Edit is the open tool you can actually ship with today.
This week’s buzz from Weights & Biases
Two quick updates from our side. First, we’re working to bring DeepSeek V3.1 to our inference as fast as we can so you can run serious benchmarks without fussing over serving stacks. Keep an eye on our channels; we’ll shout when it’s live and we’ll have some credits for early feedback.
Second, our cofounder Chris Van Pelt released Catnip, a containerized multi‑agent coding workspace that runs multiple Claude Code sessions (or other agents) in isolated sandboxes, each with its own context and notification stream. If you’ve been juggling parallel coding agents that step on each other’s toes, this is catnip indeed.
Catnip Github: https://github.com/wandb/catnip
Closing thoughts
A year ago, “thinking tokens” weren't even a curiosity; We only got the first whiff of "reasoning" back in September, and now we’re watching hybrid models that do more with less thinking, tool calls woven inside the reasoning loop, and long-context training regimes scaled up by an order of magnitude. The agent stack is maturing fast—desktop RL is finally clearing real tasks; editor ecosystems are converging on a single config file; and even the stealth drops are clearly building toward world-model‑aware editing and control.
If you only try two things this week: run DeepSeek V3.1 in both modes (planning with thinking on, execution with thinking off) and throw a complex multi-step tool workflow at it; then take Qwen Image Edit for a spin on a real product-placement or character-consistency task. You’ll feel the future in your hands.
I’m off to the desert next week for a bit (no internet where I’m going), but Wolfram and the crew will keep the ship on course. If you’re at Burning Man, DM me—would love to say hi out there. As always, thank you for tuning in and nerding out with us every week.
— Alex
TL;DR and show notes
ThursdAI - Aug 21, 2025 - TL;DR
ThursdAI - Aug 21, 2024 - TL;DR
TL;DR of all topics covered:
Hosts and Guests
Alex Volkov - AI Evangelist & Weights & Biases
Co Hosts - @WolframRvnwlf, @yampeleg, @nisten, @ldjconfirmed
Open Source LLMs // Papers
ByteDance Seed-OSS - 36B open-source LLM family (X, HF, GitHub)
DeepSeek V3.1 - Updated Hybrid model (HF)
Cohere CMD-a Reasoning - (X, Blog, HF)
Zai/Tsinghua ComputerRL - Framework for desktop agents (X, Paper, Benchmark)
IBM & NASA Surya - Solar weather prediction (HF)
NVIDIA Nemotron Nano 9B V2 - (X, Blog, HF, Dataset, Try It)
Alibaba Quark Med
Big CO LLMs + APIs
AI Art & Diffusion & 3D
This weeks Buzz
Catnip - Containerized AI agent runner (GitHub)
