
The Real Benefits of End-to-End Observability (Sponsored)

How does full-stack observability impact engineering speed, incident response, and cost control? In this ebook from Datadog, you'll learn how real teams across industries are using observability to:
Reduce mean time to resolution (MTTR)
Cut tooling costs and improve team efficiency
Align business and engineering KPIs
See how unifying your stack leads to faster troubleshooting and long-term operational gains.
This week’s system design refresher:
System Design: Design YouTube (Youtube video)
9 Docker Best Practices You Should Know
Kubernetes Explained
N8N versus LangGraph
Where Do We Cache Data?
ByteByteGo Technical Interview Prep Kit
SPONSOR US
System Design: Design YouTube
9 Docker Best Practices You Should Know

Use official images
This ensures security, reliability, and regular updates.
Use a specific image version
The default latest tag is unpredictable and causes unexpected behavior.
Multi-Stage builds
Reduces final image size by excluding build tools and dependencies.
Use .dockerignore
Excludes unnecessary files, speeds up builds, and reduces image size.
Use the least privileged user
Enhances security by limiting container privileges.
Use environment variables
Increases flexibility and portability across different environments.
Order matters for caching
Order your steps from least to most frequently changing to optimize caching.
Label your images
It improves organization and helps with image management.
Scan images
Find security vulnerabilities before they become bigger problems.
Over to you: Which other Docker best practices will you add to the list?
Kubernetes Explained
Kubernetes is the de facto standard for container orchestration. It automates the deployment, scaling, and management of containerized applications.
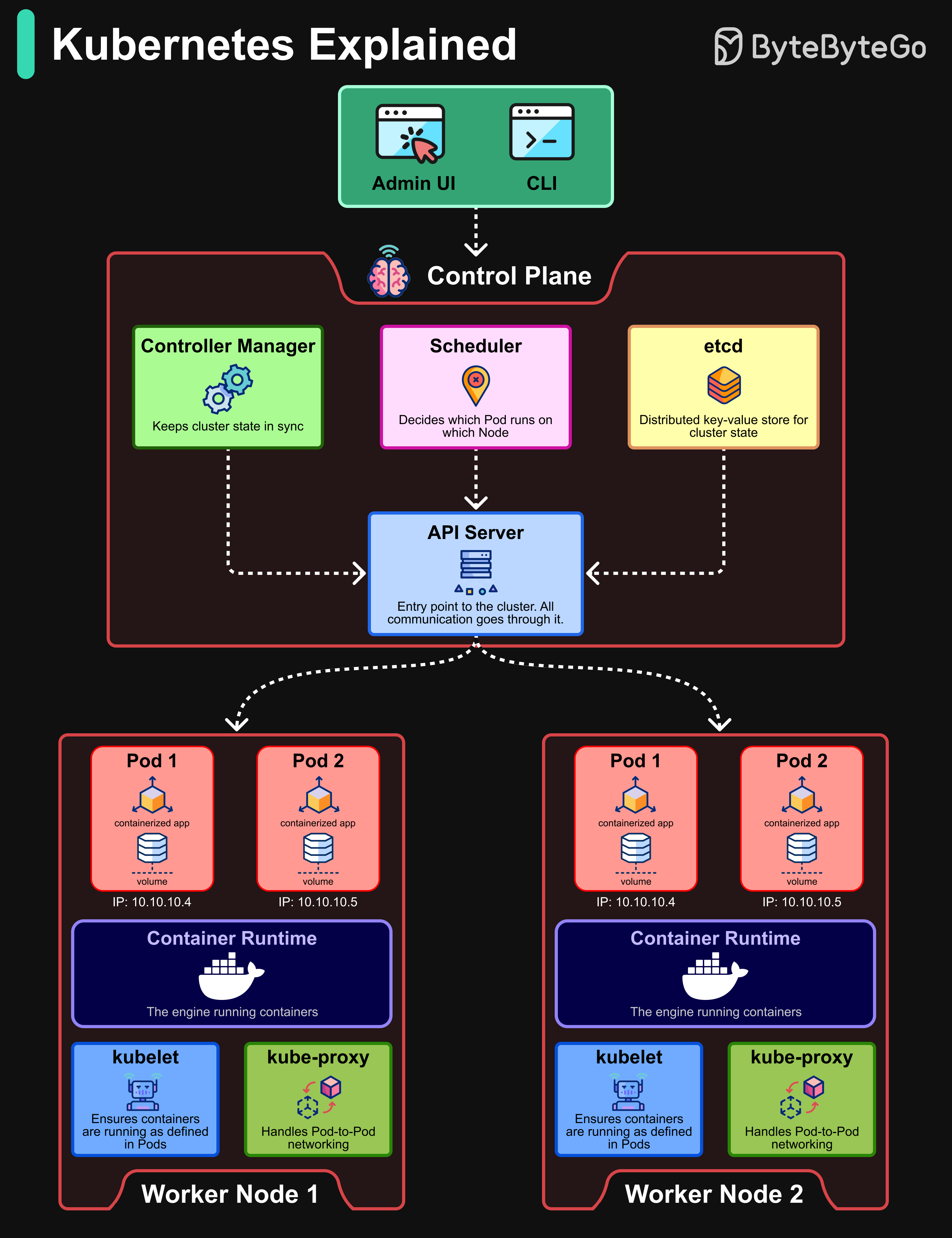
Control Plane:
API Server: Acts as the communication hub between users, the control plane, and worker nodes.
Scheduler: Decides which Pod runs on which Node.
Controller Manager: Keeps the cluster state in sync.
etcd: A distributed key-value store that holds the cluster’s state.
Worker Nodes:
Pods: The smallest deployable unit in Kubernetes, representing one or more containers.
Container Runtime: The engine (like Docker or containerd) that runs the containers.
kubelet: Ensures containers are running as defined in Pods.
kube-proxy: Handles networking between Pods and ensures communication.
Over to you: What’s the toughest part of running Kubernetes in production?
N8N versus LangGraph
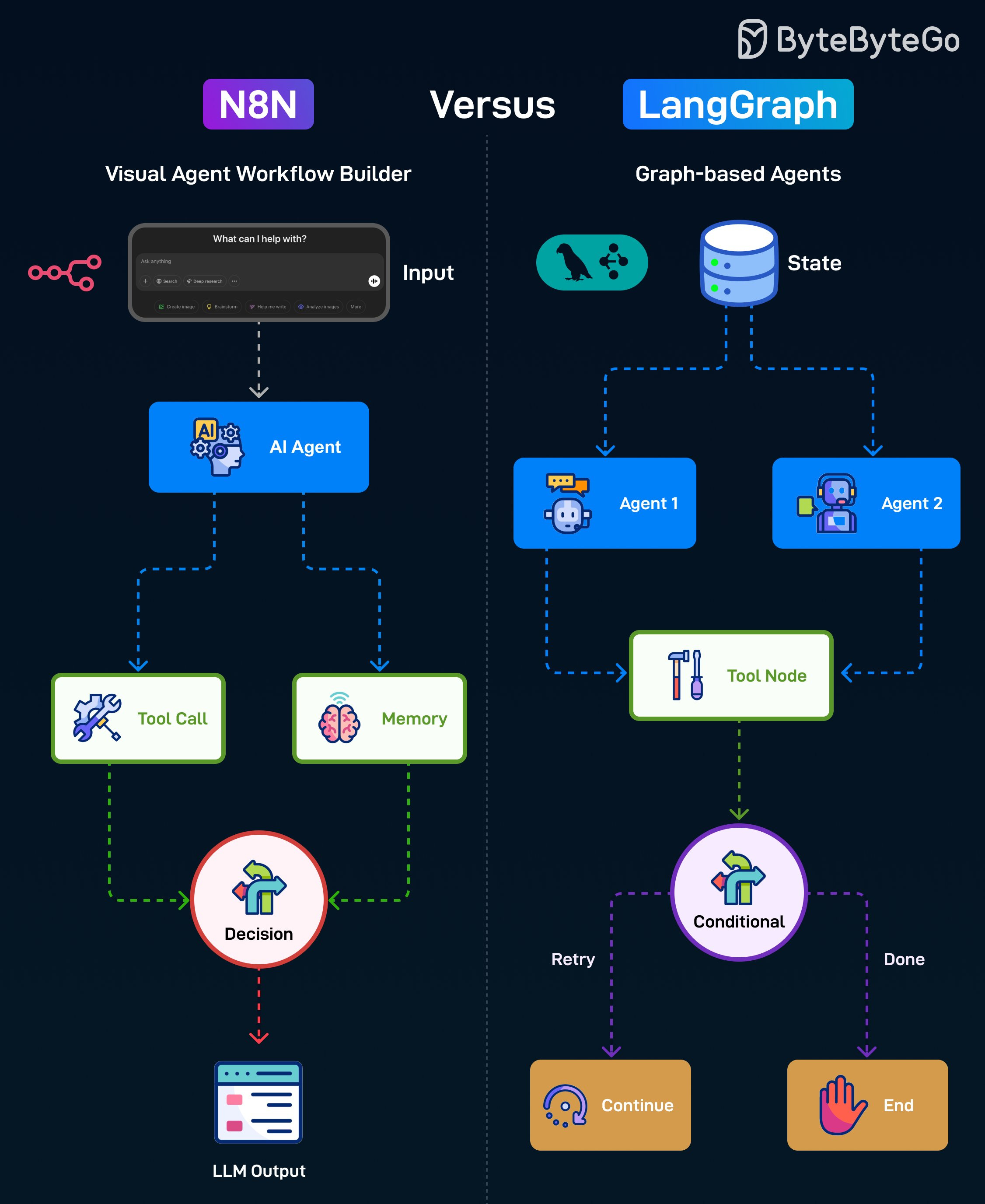
N8N is an open-source automation tool that lets you visually build workflows by connecting different services, APIs, and AI tools in a sequence. Here’s how it works:
Starts with Input from the user.
Passes it to an AI Agent for processing.
The AI Agent can either make a Tool Call or access Memory.
A Decision node chooses the next action and produces the final LLM output for the user.
LangGraph is a Python framework for building AI Agent workflows using a flexible graph structure that supports branching, looping, and multi-agent collaboration. Here’s how it works:
Starts with a shared State containing workflow context.
Can route tasks to different agents.
Agents interact with a Tool Node to perform tasks.
A Conditional node decides whether to retry or mark the process done.
Over to you: Have you used N8N or LangGraph?
Where Do We Cache Data?
Data is cached everywhere, from the front end to the back end!
This diagram illustrates where we cache data in a typical architecture.
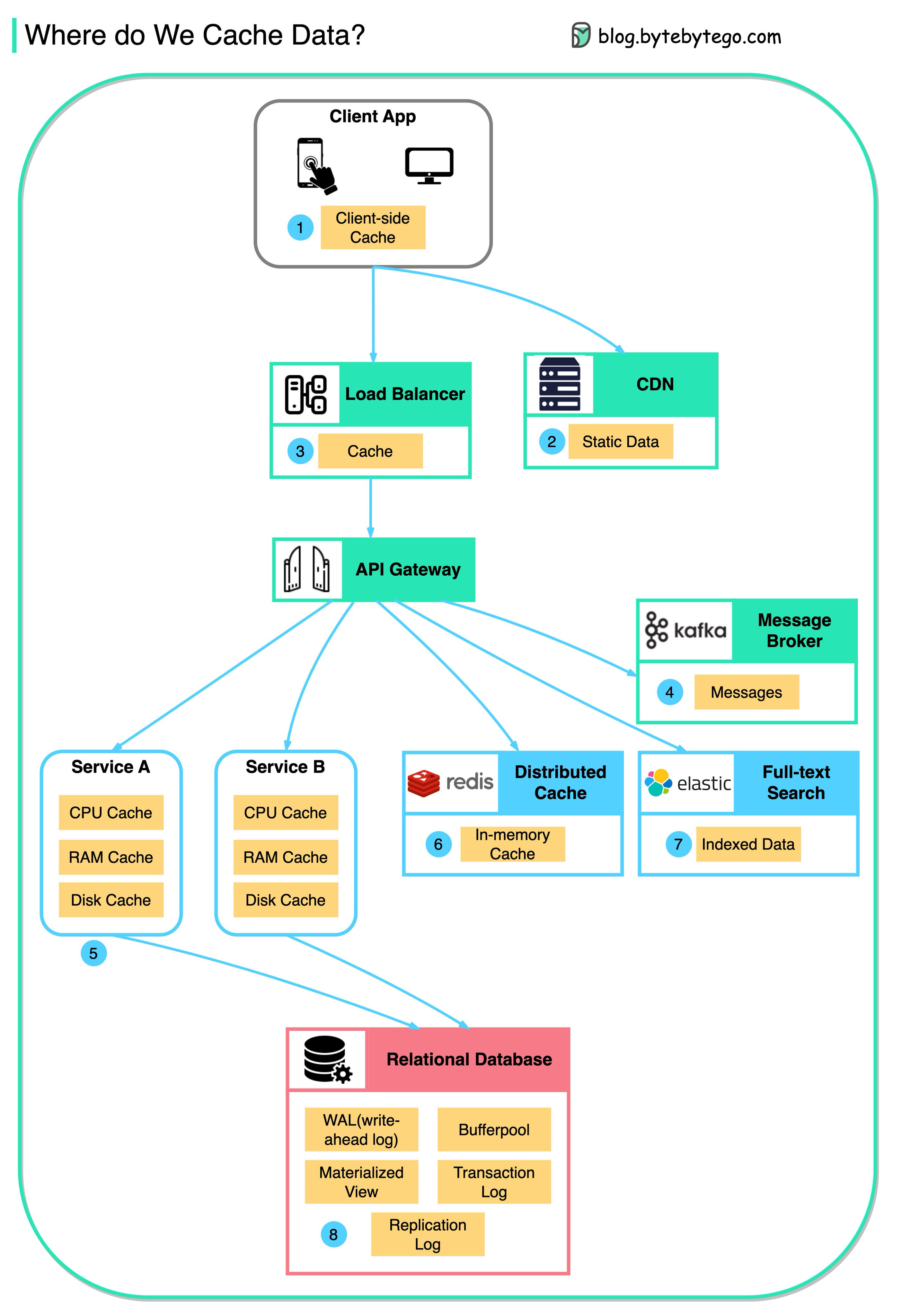
There are multiple layers along the flow.
Client apps: HTTP responses can be cached by the browser. We request data over HTTP for the first time, and it is returned with an expiry policy in the HTTP header; we request data again, and the client app tries to retrieve the data from the browser cache first.
CDN: CDN caches static web resources. The clients can retrieve data from a CDN node nearby.
Load Balancer: The load Balancer can cache resources as well.
Messaging infra: Message brokers store messages on disk first, and then consumers retrieve them at their own pace. Depending on the retention policy, the data is cached in Kafka clusters for a period of time.
Services: There are multiple layers of cache in a service. If the data is not cached in the CPU cache, the service will try to retrieve the data from memory. Sometimes the service has a second-level cache to store data on disk.
Distributed Cache: Distributed cache like Redis hold key-value pairs for multiple services in memory. It provides much better read/write performance than the database.
Full-text Search: we sometimes need to use full-text searches like Elastic Search for document search or log search. A copy of data is indexed in the search engine as well.
Database: Even in the database, we have different levels of caches:
WAL(Write-ahead Log): data is written to WAL first before building the B tree index
Bufferpool: A memory area allocated to cache query results
Materialized View: Pre-compute query results and store them in the database tables for better query performance
Transaction log: record all the transactions and database updates
Replication Log: used to record the replication state in a database cluster
Over to you: With the data cached at so many levels, how can we guarantee the sensitive user data is completely erased from the systems?
ByteByteGo Technical Interview Prep Kit
Launching the All-in-one interview prep. We’re making all the books available on the ByteByteGo website.
What's included:
System Design Interview
Coding Interview Patterns
Object-Oriented Design Interview
How to Write a Good Resume
Behavioral Interview (coming soon)
Machine Learning System Design Interview
Generative AI System Design Interview
Mobile System Design Interview
And more to come
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.
