
Developer-first security for your entire codebase (Sponsored)
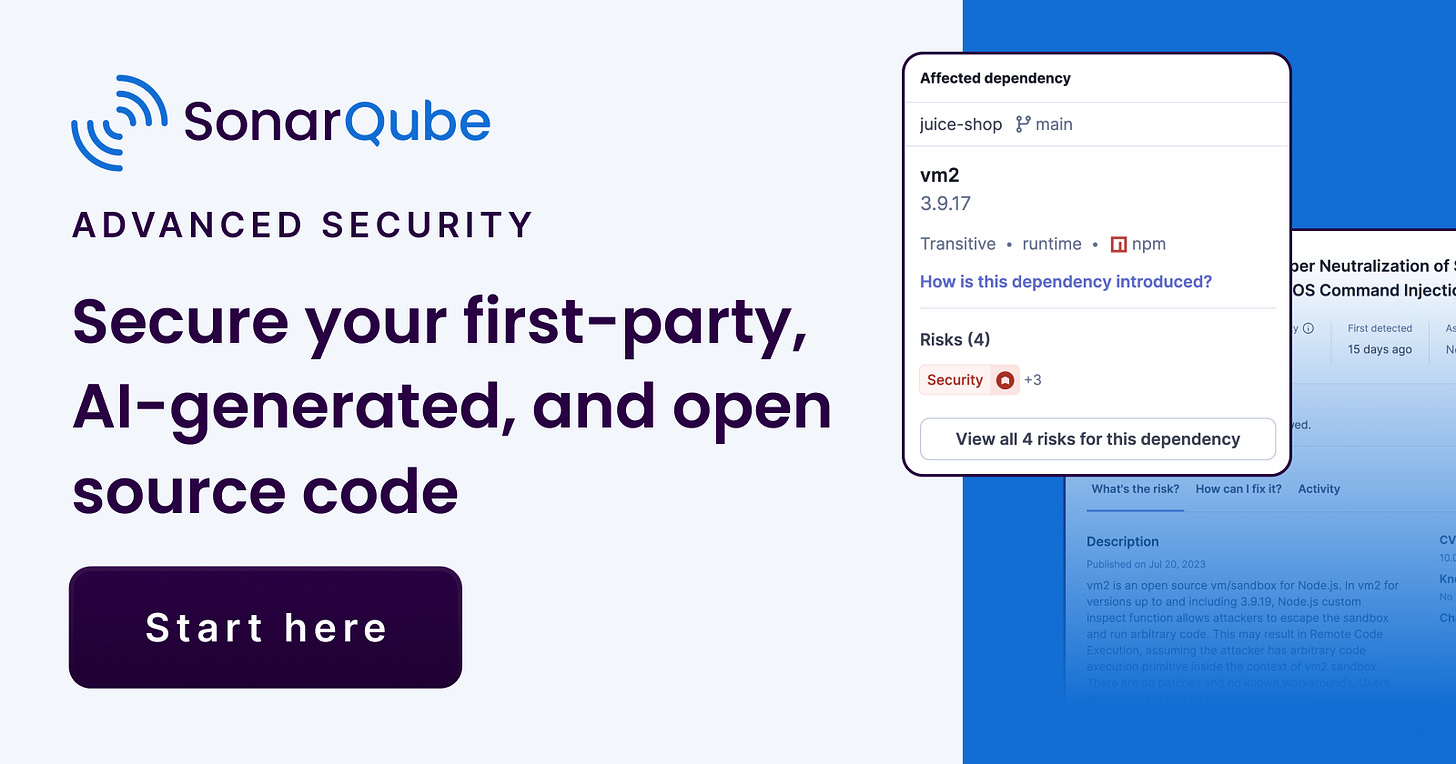
Ready to embrace secure coding without slowing down? SonarQube Advanced Security helps you find and fix quality and security issues across your entire codebase—from first-party and AI-generated code to your open source dependencies.
SonarQube addresses security challenges head on, offering a unified solution for:
Proactive vulnerability identification and management across all code
Streamlined compliance with SBOM generation and license policy management
Integrated code quality and code security solution for comprehensive code health, eliminating tool sprawl
Disclaimer: The details in this post have been derived from the official documentation shared online by the Meta Engineering Team. All credit for the technical details goes to the Meta Engineering Team. The links to the original articles and sources are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
Meta AI’s “animate” feature turns a generated image into a short, dynamic video using AI.
It wasn’t a matter of simply introducing another creative effect, but an attempt at something far more complex: delivering video synthesis at a global scale and in near real time.
Billions of users might click “animate” on any given day, and each request comes with critical constraints. The system must produce results in just a few seconds, maintain a consistently high success rate, and operate within tight GPU budgets that leave little room for waste. What looks like a playful feature in the product UI is a carefully engineered balancing act between cutting-edge AI research and large-scale distributed systems.
The challenge is twofold:
First, the underlying diffusion models must be optimized to run fast enough for interactive use without sacrificing quality
Second, the service must be deployed across Meta’s global infrastructure in a way that minimizes latency, contains failures, and scales to meet demand spikes without degrading user experience.
These two domains (model/inference-level acceleration and planet-scale traffic engineering) form the backbone of Meta’s solution. In this article, we will look at how Meta implemented this feature and the challenges they faced.
Help us Make ByteByteGo Newsletter Better
TL:DR: Take this 2-minute survey so I can learn more about who you are,. what you do, and how I can improve ByteByteGo
Model and Inference Optimizations
The “animate” feature is powered by diffusion models, which normally take a lot of steps and computation to produce good results.
For reference, a diffusion model is a type of AI that creates images (or videos) by starting with pure random noise and then gradually “cleaning” it step by step until a clear picture appears. It learns how to do this by studying lots of real images and figuring out patterns. Think of it like an artist who begins with a messy canvas and slowly refines it.
To make animation practical for billions of users, Meta had to speed up the models without lowering quality. They achieved this with several optimizations as follows:
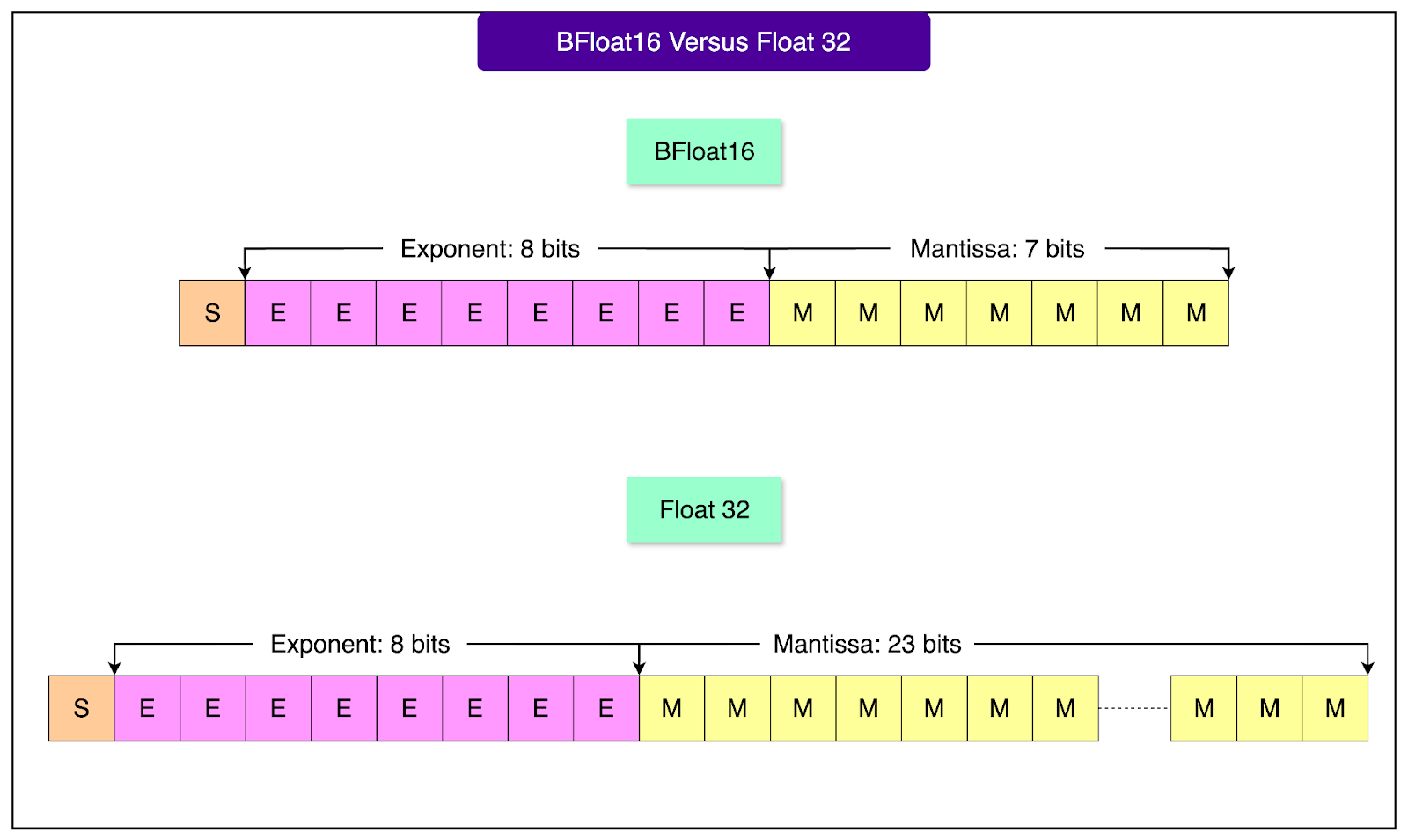
1 - Half-precision with bfloat16
Most AI models run in 32-bit floating point (FP32), which uses a lot of memory and processing power. FP32 has a wide range and fine-grained precision, which helps when weights or gradients are very large or very small.
Meta switched to a lighter format called bfloat16 (a type of 16-bit precision) for both training and inference. Unlike FP16, it keeps the same range as FP32 but sacrifices some precision. This means it can represent very large and very small numbers safely. It cuts the memory requirement in half and allows GPUs to process data faster. The model’s accuracy remains high, but performance improves immediately.
2 - More Efficient Temporal Attention
When creating a video from images, the model needs to understand how frames relate to each other. Normally, this involves copying the same context information across all frames before running attention layers, which wastes memory and compute.
Meta changed the process so that the copying happens after the linear projection step in cross-attention. Since the context is identical, delaying expansion avoids unnecessary work and lowers the memory footprint.
3 - Fewer Sampling Steps with DPM-Solver
Diffusion models usually need to run through many tiny steps to turn random noise into a clear picture or video.
The more steps we use, the better the result, but it takes longer. Meta used a faster method called DPM-Solver, which can get almost the same quality in far fewer steps (about 15 instead of dozens or even hundreds).
This makes the process much quicker while still keeping the output sharp.
4 - Combining Step Distillation and Guidance Distillation
Meta combined two powerful techniques into one process:
Step distillation: Training a smaller “student” model to compress multiple steps of the larger “teacher” model into fewer steps.
Classifier-free guidance distillation: Instead of running the model three times per step (for unconditional, image-only, and text+image inputs), the process is distilled so only one pass is needed.
See the diagram below:
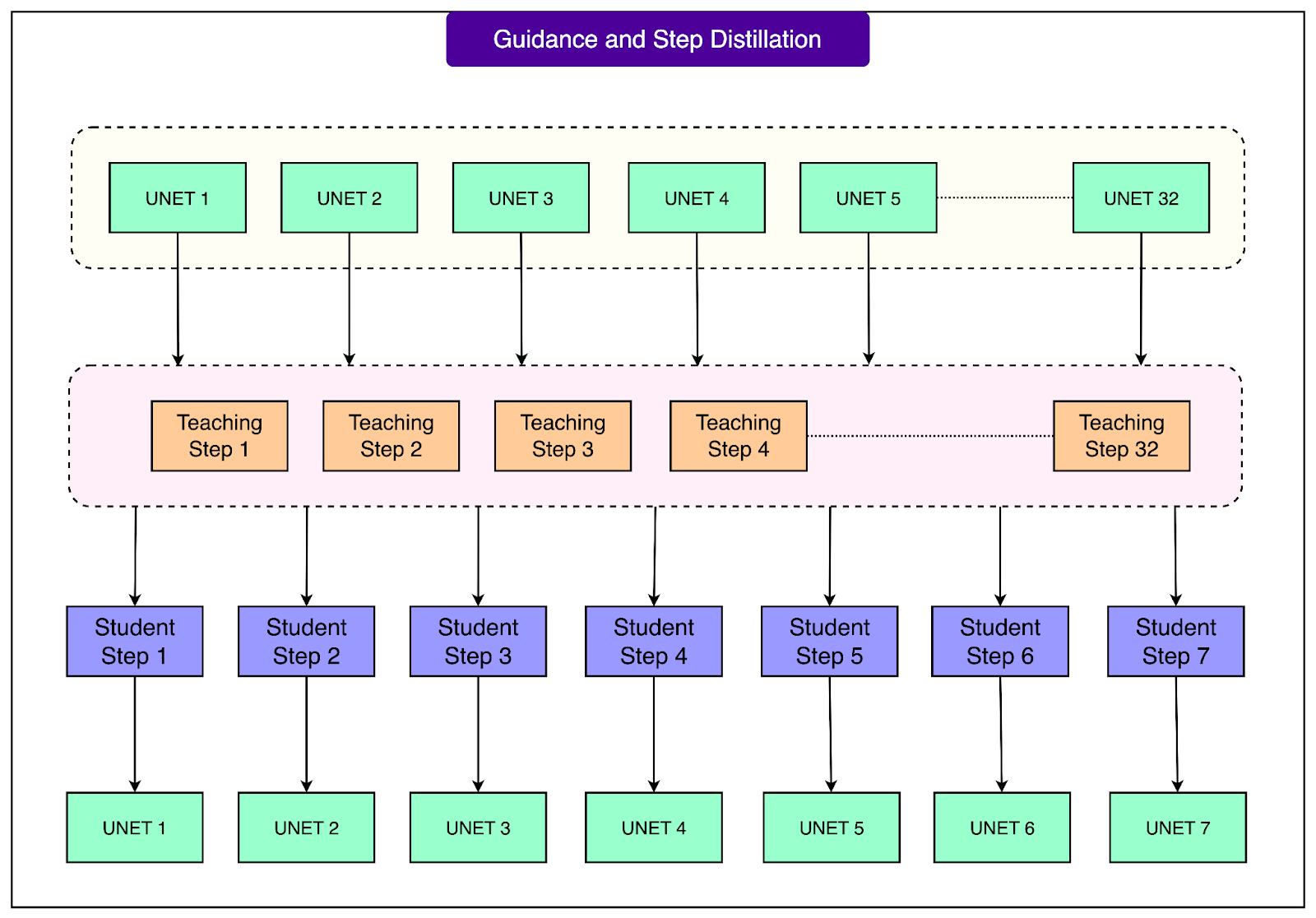
By merging these, Meta reduced the pipeline to 8 solver steps, with just one U-Net forward pass per step. In effect, they compressed 32 teacher steps into 8 student steps, while also removing the overhead of multiple passes per step. This was a 3X reduction.
5 - Improvements with PyTorch Deployment
At first, the system used TorchScript with freezing, which improved performance through graph simplification, constant folding, and fusing operations. Later, Meta migrated to PyTorch 2.0 with torch.compile at the component level.
This provided better tracing, faster iteration for new features, and support for advanced techniques like context parallelism and sequence parallelism, as well as multi-GPU inference for larger workloads.
Running at Planet Scale
Speeding up the model itself was only half the challenge.
Meta also had to make sure the system could handle billions of requests every day across the globe without slowing down or failing. That required careful planning and new traffic management systems.
1 - Capacity Modeling and Load Tests
Meta started by estimating how many people would use the feature.
They looked at data from earlier AI launches, calculated how many requests per second that would mean, and then mapped those numbers to the GPU power required. Using these projections, they ran large-scale load tests, identified bottlenecks, and removed them step by step until the system could handle the expected traffic.
2 - Fixing Latency from Cross-Region Routing
Even after model optimizations, end-to-end latency was higher than expected.
The problem was that requests were often routed to faraway regions, adding seconds of network delay.
To fix this, Meta built a traffic management system that creates a routing table. This ensures requests stay within their own region whenever possible, and are only redirected elsewhere if the local region is close to running out of capacity. This adjustment brought latency back down to target levels.
3 - How the Traffic Manager Makes Decisions
The system works in tiers:
It collects performance metrics from all machines in each region.
It calculates how much extra load each region can handle.
It first tries to keep all traffic in the source region.
If one region is overloaded, it finds the closest region with available capacity and offloads some traffic there.
See the diagram below:
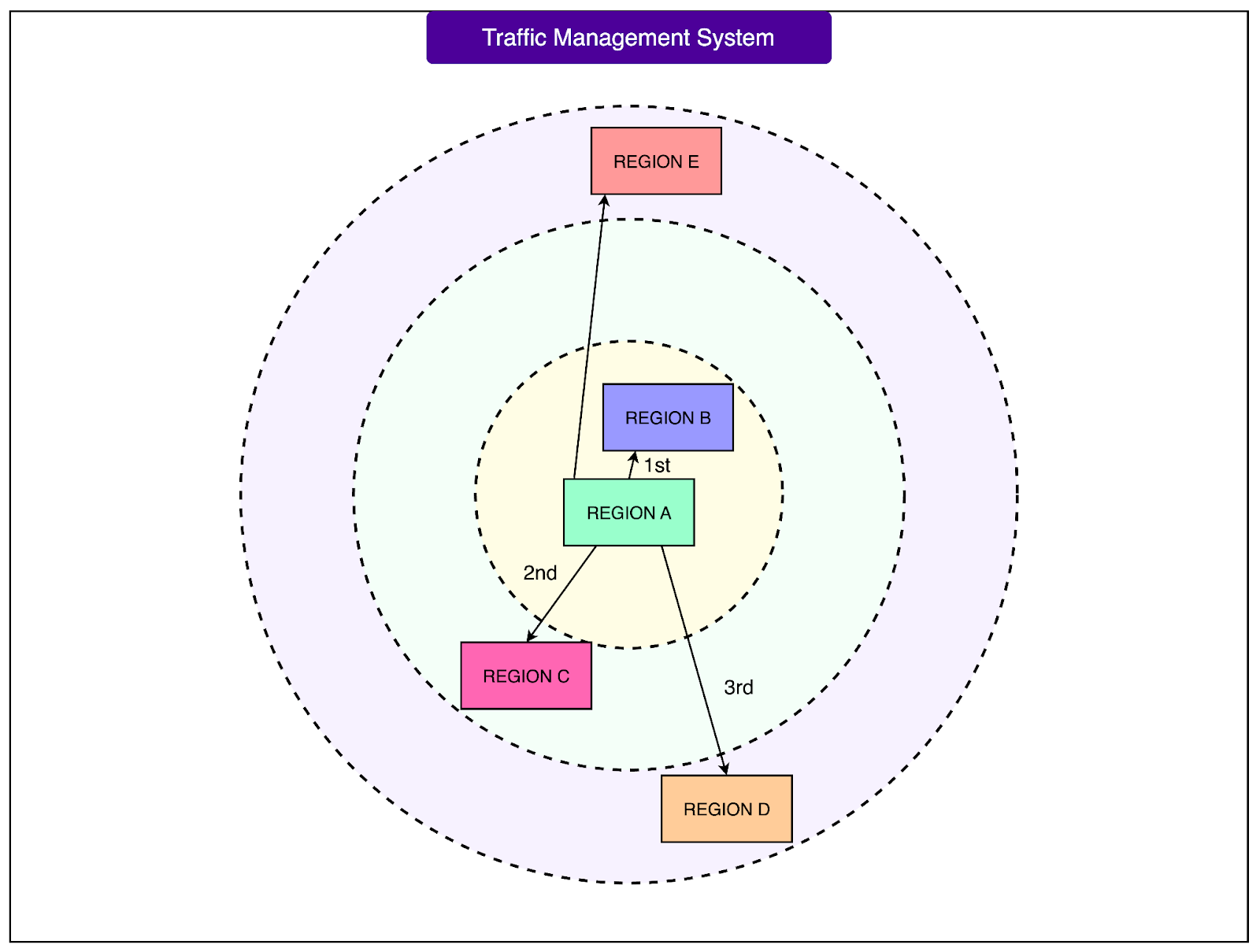
If overloads are severe, the system gradually expands the search radius outward, creating “rings” of nearby regions. Once it finds a stable balance, it locks in a routing table, which is then used for live requests.
4 - No Queue Rule and Success Rate Dips
Each GPU can process only one request at a time.
To keep latency low, Meta does not allow queuing. If a GPU is busy, the request is rejected. This keeps performance consistent, but causes more failures near capacity. Instead of building a large, slow global queue, Meta relied on quick retries to help requests find available GPUs. This worked before regionalization.
5 - Retry Storms
Once traffic was pinned to local regions, retrying became a problem. With fewer machines to send retries to, spikes of retries caused “retry storms,” where too many requests flooded the system at once.
To solve this, Meta made two key changes:
Introduced a small, random delay to some jobs at scheduling time, spreading out arrivals.
Added exponential backoff for retries, so repeated retries waited progressively longer instead of hammering the system immediately.
These adjustments smoothed out traffic, prevented cascades, and restored high success rates.
See the diagram below:
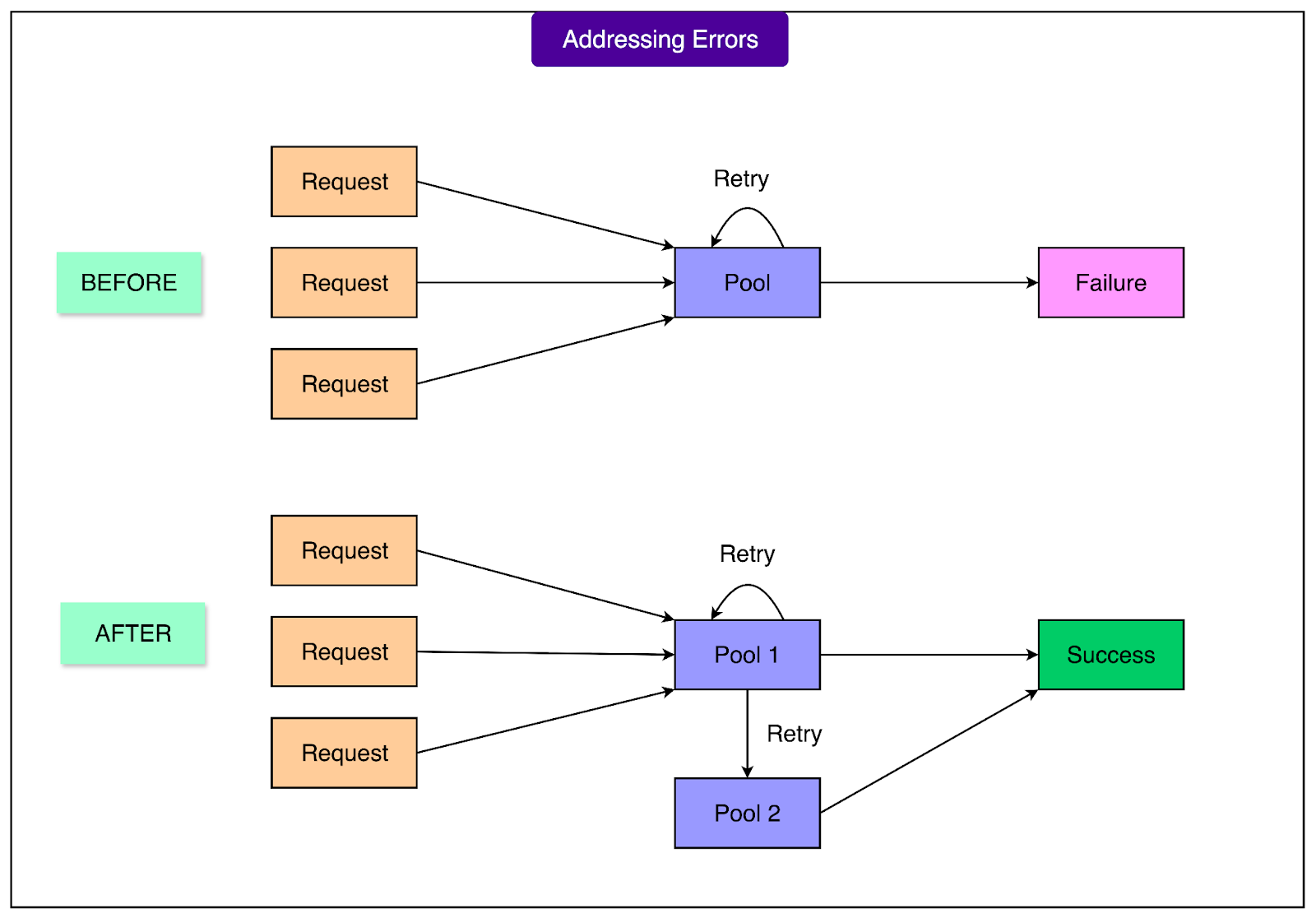
Conclusion
Meta’s “animate” feature demonstrates the kind of engineering discipline required to bring cutting-edge AI research into the hands of billions of people.
What appears to users as a simple transformation from a static picture to a moving image is the outcome of dozens of technical breakthroughs across both model design and infrastructure.
On the modeling side, the team reduced the cost of diffusion-based generation through precision optimizations, more efficient attention mechanisms, faster solvers, and aggressive distillation. Together, these measures compressed what once required dozens of heavy steps into just a handful of efficient operations, all while preserving output quality.
Yet scaling the feature was as much a systems problem as it was a research one. Running diffusion pipelines across a global user base required careful demand forecasting, new approaches to region-aware routing, and strict rules around GPU utilization to keep latency predictable.
The key learning is that AI isn’t just about new models, but also about the infrastructure, software tooling, and operational strategies that allow those models to perform at scale.
References:
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.
