
刚刚,Meta FAIR推出了代码世界模型!CWM(Code World Model),一个参数量为32B、上下文大小达131k token的密集语言模型,专为代码生成和推理打造的研究模型这是全球首个将世界模型系统性引入代码生成的语言模型。

与现有代码大模型相比,CWM最与众不同的一点在于,它不仅能生成代码、理解语义。
更关键的是,它“懂得”代码如何执行,能模拟代码运行过程中变量的状态变化与环境反馈,从而推动代码理解、调试乃至规划的整体能力提升。
也就是说,它具备接近人类程序员的思考能力。
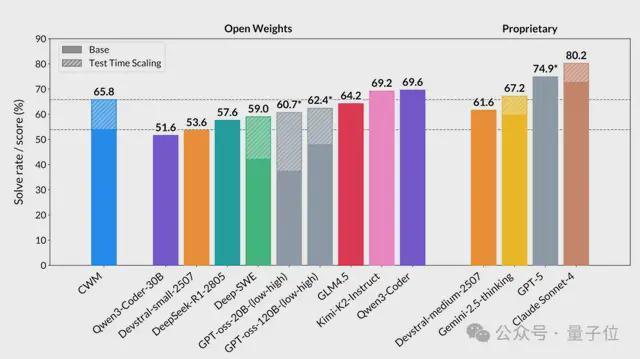
在多个代码与推理任务上,CWM均有出色表现,譬如其在SWE-bench Verified得分65.8%,领先所有开源同规模模型,已接近GPT-4级别。
更重要的是,Meta FAIR这次开源了模型代码、训练细节以及多个阶段的权重检查点,诚意十足。
有人给LeCun留言问:
“你不是一直认为语言模型只是AI道路上的一个支线(LLMs are an off ramp),怎么又推出了以语言模型为基础的世界模型?”
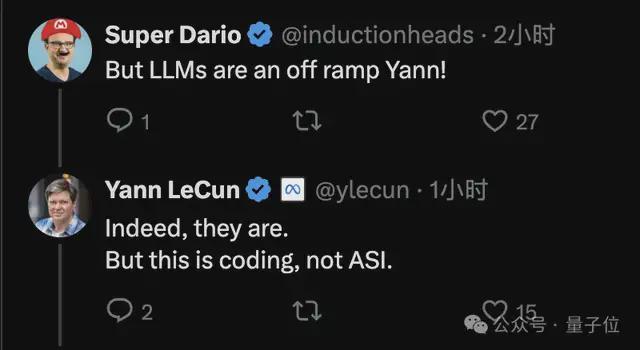
LeCun轻松回复称:
是的,不过咱现在讲的是编程,不是ASI哟~
让大模型“懂动态执行”
CWM的诞生,直击当前大模型在代码生成中的一大痛点:
尽管现有大模型已经具备写代码的能力,但代码执行效果并不稳定,生成内容难以调试、不可执行,甚至存在隐藏逻辑错误。
FAIR团队认为,其根源在于大模型只是把代码当作文本来预测。
它不理解代码会如何运行,对变量状态的变化、函数调用的副作用一知半解(甚至一无所知)。
在FAIR团队看来:
如果希望模型像程序员一样思考,就必须教会它代码执行的“世界状态”变化。
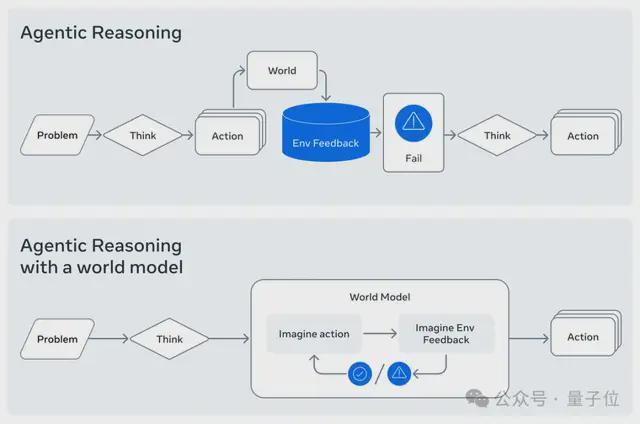
因此,CWM首次在训练过程中引入代码世界建模(code world modeling)的概念,明确让模型学习“代码运行过程中,程序状态如何一步步演变”。
这意味着,CWM的理解维度,从静态文本跃迁到了动态执行。
Meta FAIR专攻AI与代码生成的资深研究科学家,也是CWM的资深核心贡献者Gabriel Synnaeve在上分享了CWM追踪执行计算”strawberry”中”r”个数的代码的例子:
你可以把它想象成一个可以设置为任何初始帧状态的神经‘pdb’,推理可以作为工具在标记空间中查询。

相较于传统代码大模型生成token接token的静态预测,CWM在三大能力有所升级——
第一,代码执行模拟。
CWM可以逐行模拟代码执行过程,预测每一行代码如何影响变量状态,甚至提前判断出执行中的潜在错误。
这种能力为构建“神经调试器”提供了可能。
在CWM的推理过程中,变量状态可以随代码运行不断更新。
它甚至可以模拟终止条件、循环展开、边界情况,从而更精准地理解程序逻辑。
第二,自我调试与修复。
不止会写代码,CWM还能自测、修错。
它能够在生成代码后自动构造测试用例,并在发现代码失败后用多种修改路径来尝试自我修复。
整个流程模拟了人类程序员常见的开发闭环:写→测试→改→再测。
第三,推理与规划能力。
面对复杂问题时,CWM还能进行推理与规划。
例如,在编程竞赛或数学任务中,它可以根据问题描述分析步骤、规划函数结构,再结合执行预测逐步生成并验证代码,展现出多轮逻辑推理能力。
CWM模型信息:参数、架构、性能一次看全
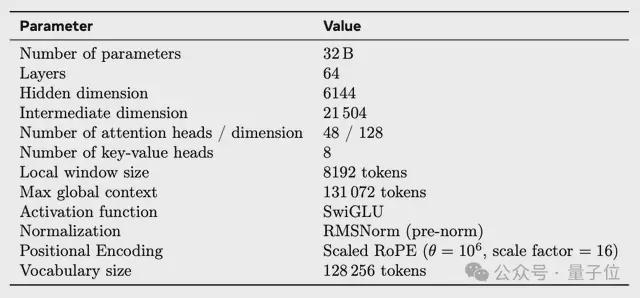
CWM的模型架构采用了64层的decoder-only Transformer,参数规模为32B。
它支持131k tokens的长上下文输入——这大幅拓展了复杂项目、多文件代码、文档上下文的处理能力。
相对应的,Attention结构采用了局部+全局交替机制,兼顾效率与上下文覆盖。
FAIR提供了以下3个checkpoints,供研究人员使用:
CWM预训练模型:例如用于新的后训练方法。
CWM SFT:例如用于强化学习研究。
CWM:例如用于推理时间扩展。
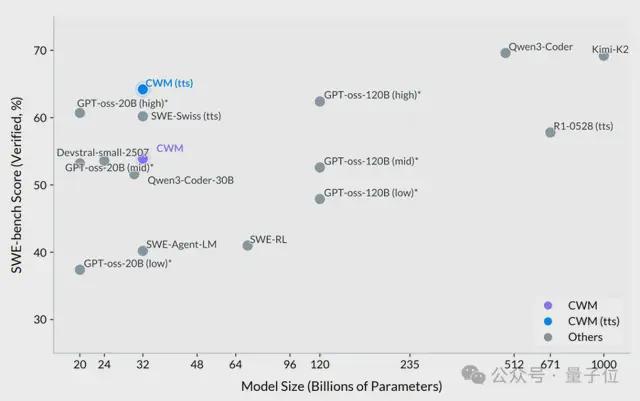
在与多个一线模型的评测对比上,CWM成绩如下:
SWE-bench Verified
得分65.8%,领先所有开源同规模模型,接近GPT-4级别;
LiveCodeBench v5
得分68.6%,展示高复杂度编程任务上的准确性;
Math-500
得分96.6%,AIME 2024模拟题达76.0%;
Terminal-Bench
得分26.3%,高于Gemini 2.5 Pro;
Aider Polyglot(多语言代码生成)
得分35.1%,与Qwen3-32B相近。
综合来看,CWM在理解、生成、验证、修复等多个环节上,都有不俗表现。
FAIR团队称CWM验证了“代码世界建模”对提升推理与代码生成的价值。
Gabriel Synnaeve表示:
我对我的CodeGen团队所做的工作感到无比自豪!
这个团队由博士生和经验丰富的资深员工组成。我们所有人都齐心协力,全力以赴,绝不将任何问题归咎于他人。
整个Meta AI社区都为此共同努力。非常感谢整个领导层始终如一的支持。
三阶段训练流程,与数据集构建
CWM分三阶段进行训练——
第一阶段,预训练阶段(Pretrain)。
在这个阶段,CWM使用了8T tokens的数据进行通用语言与代码建模训练。
其中代码占比约30%,上下文长度为8k token。
第二阶段,中期训练阶段(Mid-train),这也是CWM最具特色的一步。
在这个阶段,模型引入了5T tokens的世界建模数据,用于训练模型识别“代码运行过程中,程序状态如何变化”。
这部分核心数据类型包括:
Python执行轨迹数据
来自数千万函数调用与代码提交,记录每一行代码执行时变量的值如何变化;
ForagerAgent数据
模型驱动的智能体在真实Docker环境中运行代码,修复Bug,执行任务,生成真实交互轨迹(共300万条);
自然语言描述版本
将执行过程转化为自然语言,便于泛化迁移。
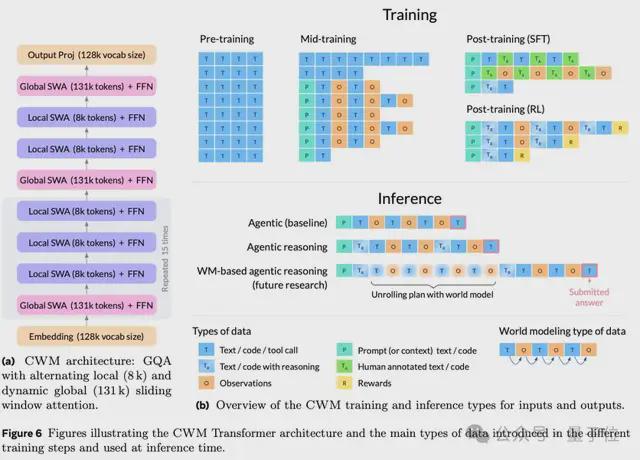
也是在这一阶段,CWM的上下文能力扩展到了131k token,支撑对大型项目和代码流程的完整建模。
第三阶段,后训练阶段(SFT+多任务RL)。
最后,CWM进行了100B tokens的监督微调训练(SFT)和172B tokens的多任务强化学习(RL)训练。
训练任务覆盖了真实软件工程任务(如SWE-bench)、编程竞赛问题(CodeContests等)、数学推理题目(如AIME模拟题、MathQA)。
在这一阶段,FAIR团队使用异步RL机制、分布式环境以及自举方法,提升了模型在多环境、多任务间的泛化能力。
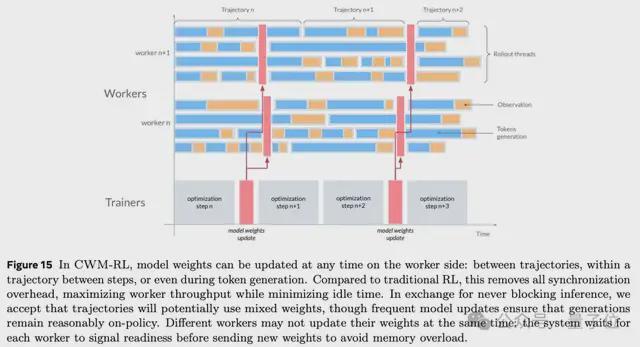
基础设施方面,CWM训练使用了FlashAttention-3、FSDP+TP并行策略,并采用fp8低精度加速。
Meta FAIR强调其训练过程遵循了Frontier AI Framework中的前沿AI安全框架。
结果表明,CWM不会对网络安全、化学、生物等高敏感领域构成滥用风险。
此外需要注意的一点是,当前CWM的世界建模数据仅支持Python语言,尚未覆盖C++、Java等主流语言或符号执行任务。
不过,研究团队表示未来将探索多语言扩展,有望形成自动化编程助手的通用框架。
Two More Things
BTW,如果你想使用使用CWM,有两点需要特别注意:
第一点,CWM主要面向代码理解与复杂推理研究,没有做RLHF。
因此,它并不适合对话任务或作为Chatbot使用。
第二点,CWM明确定位是“研究用”,即仅供非商业研究使用。
Anyway,总之,CWM团队选择了模型开源、数据透明、训练复现全开放。借此也向研究社区抛出一个重要问题:
如果大模型能理解世界,它能成为更好的程序员吗?
