
近日消息,在今日2025云栖大会上,阿里通义大模型迎来7连发,阿里云智能首席技术官周靖人发布了多项重磅技术更新。
通义大模型在模型智能水平、Agent工具调用和Coding能力、深度推理、多模态等方面实现多项突破。
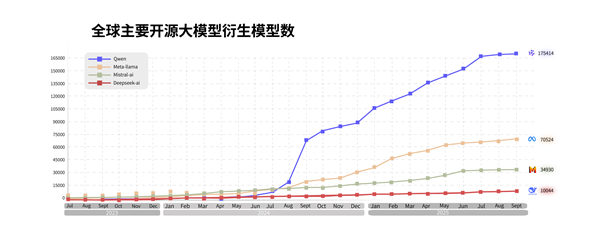
截至目前,通义大模型已成为全球第一开源模型,也是中国企业选择最多的模型。
当前,阿里通义开源了300余个模型,覆盖不同大小的“全尺寸”及LLM、编程、图像、语音、视频等“全模态”,全球下载量突破6亿次,全球衍生模型17万个,稳居全球第一。
超100万家客户接入通义大模型,权威调研机构沙利文2025上半年报告显示,在中国企业级大模型调用市场中,阿里通义占比第一。
在大语言模型中,阿里通义旗舰模型Qwen3-Max全新亮相,性能超过GPT5、Claude Opus 4等,跻身全球前三。
Qwen3-Max包括指令(Instruct)和推理(Thinking)两大版本,其预览版已在Chatbot Arena排行榜上位列第三,正式版性能可望再度实现突破。
Qwen3-Max是通义千问家族中最大、最强的基础模型,预训练数据量达36T tokens,总参数超过万亿,拥有极强的Coding编程能力和Agent工具调用能力。
下一代基础模型架构Qwen3-Next及系列模型也正式发布,模型总参数80B仅激活3B,性能即可媲美千问3旗舰版235B模型,实现模型计算效率的重大突破。
而在专项模型方面,千问编程模型Qwen3-Coder迎来重磅升级。
新的Qwen3-Coder与Qwen Code、Claude Code系统联合训练,应用效果显著提升,推理速度更快,代码安全性也显著提升。
其开源后调用量曾在知名API调用平台OpenRouter上激增1474%,位列全球第二。
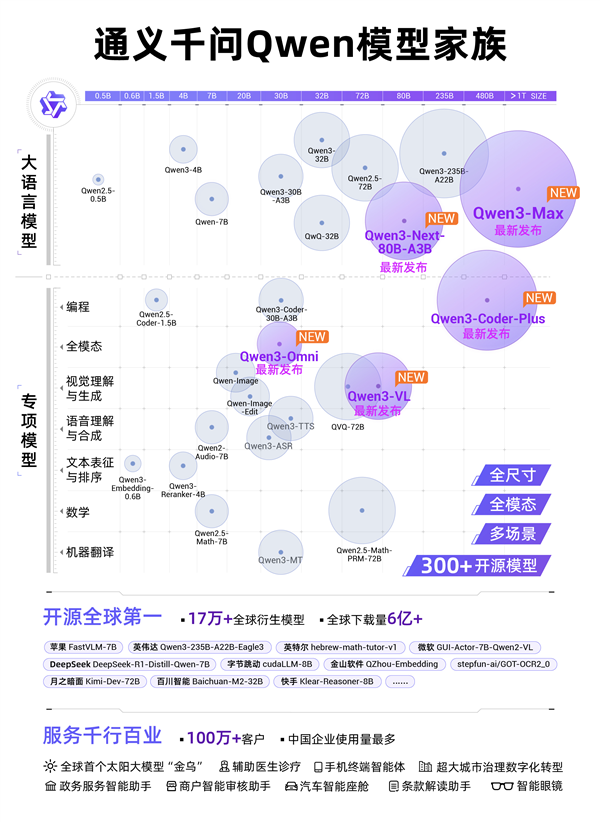
在多模态模型中,视觉理解模型Qwen3-VL重磅开源,在视觉感知和多模态推理方面实现重大突破,在32项核心能力测评中超过Gemini-2.5-Pro和GPT-5。
Qwen3-VL拥有极强的视觉智能体和视觉Coding能力,不仅能看懂图片,还能像人一样操作手机和电脑,自动完成许多日常任务。
而全模态模型Qwen3-Omni也惊喜亮相,音视频能力狂揽32项开源最佳性能SOTA,可像人类一样听说写,应用场景广泛,未来可部署于车载、智能眼镜和手机等。
同时,用户还可设定个性化角色、调整对话风格,打造专属的个人IP。
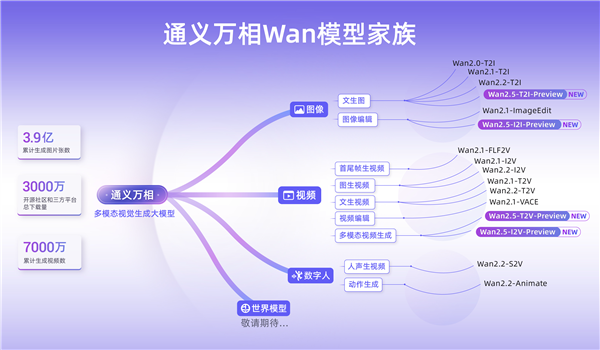
而在视觉基础模型中,通义万相推出Wan2.5-preview系列模型,涵盖文生视频、图生视频、文生图和图像编辑四大模型。
通义万相2.5视频生成模型能生成和画面匹配的人声、音效和音乐BGM,首次实现音画同步的视频生成能力,进一步降低电影级视频创作的门槛。
视频生成时长从5秒提升至10秒,支持24帧每秒的1080P高清视频生成,并进一步提升模型指令遵循能力。
最后,通义大模型家族还迎来了全新的成员——语音大模型通义百聆,包括语音识别大模型Fun-ASR、语音合成大模型Fun-CosyVoice。
Fun-ASR基于数千万小时真实语音数据训练而成,具备强大的上下文理解能力与行业适应性。
Fun-CosyVoice可提供上百种预制音色,可以用于客服、销售、直播电商、消费电子、有声书、儿童娱乐等场景。
