最近,谷歌研究团队新发了一篇很牛的论文。
他们推出了他们的深度研究型智能体——TTD-DR(Test-Time Diffusion Deep Researcher),翻译过来就是测试时扩散深度研究员。
说白了,就是让AI学会像人一样打草稿。
如果让你写一篇深度研究报告,你会怎么做?
一般都是先列个提纲,然后写个初稿,接着查资料、改来改去,最后才能交出一份像样的成果。
这个看似平常的过程,却难倒了一众AI。
比如今年2月,OpenAI推出了Deep Research功能,号称能帮你写出专业级的研究报告。Perplexity紧随其后,Grok也不甘示弱。
一时间,AI研究助手赛道热闹非凡。
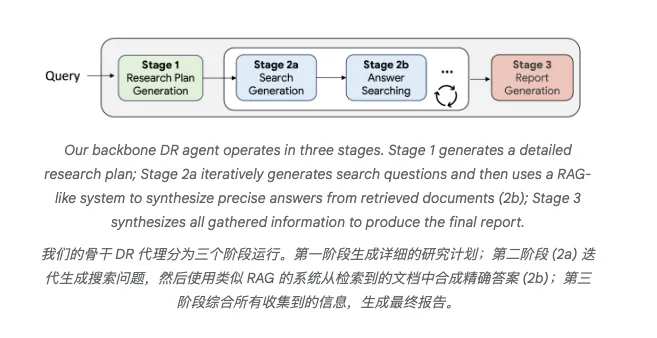
但问题来了,现有的AI研究助手基本都是一条道走到黑:接到任务,搜索资料,生成报告,完事儿。
这就像考试时不打草稿直接往答题卡上写,一旦跑偏了就很难纠正。
谷歌团队仔细研究了人类的写作习惯后发现,没有人是从第一个字写到最后一个字的。
1981年的一项认知研究就指出,人类写作是个反复迭代的过程:先有个大概框架,然后不断修改完善。
这个过程中,我们会不停地查资料、调整思路、推倒重来。
有意思的是,这个过程跟物理学里的扩散模型惊人地相似。
扩散模型简单说,就是从一团噪声开始,逐步去噪,最终生成清晰的图像。
谷歌团队灵机一动:既然能用这个方法生成图像,为啥不能用来生成研究报告呢?
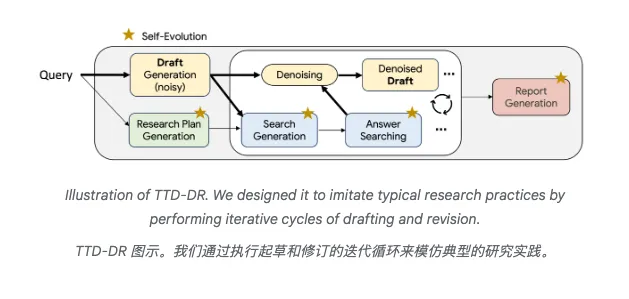
TTD-DR的核心创新在于两个机制同时发力。
第一条腿是去噪优化。
系统先根据用户需求生成一个粗糙的初稿,就像画画时的草图。
然后,每次搜索到新信息,就对这个草稿进行一次修订。
这个过程就像雕刻家一点点雕琢大理石,每一刀都让作品更接近理想状态。
第二条腿是自我进化。
系统的每个组件(制定计划的、生成问题的、搜索答案的、写报告的)都会产生多个版本,然后通过内部评分机制选出最优解。
这就像让五个人同时写同一份报告,然后取各家之长,合成最终版本。
这两条腿配合起来威力惊人。
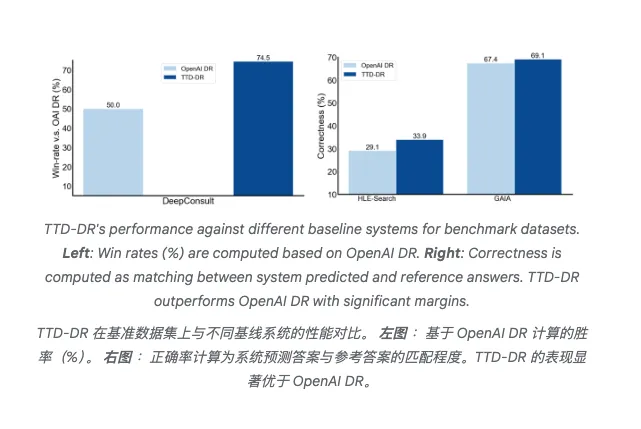
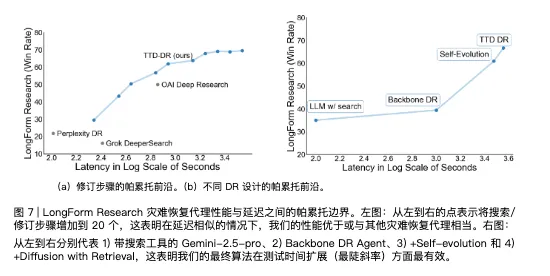
在测试中,TTD-DR在长篇研究报告生成任务上的胜率达到69.1%和74.5%,碾压OpenAI Deep Research。
在需要多跳推理的复杂问题上,准确率也提升了4.8%到7.7%不等。
论文里有个特别有意思的发现:系统在第9步修改时,就已经包含了最终报告51.2%的信息。
这意味着传统方法要搜索20次才能达到的效果,新方法不到一半的步骤就能实现。
更妙的是,这个系统会根据草稿的内容动态调整搜索策略。比如写到一半发现某个观点站不住脚,它会立即去搜索相关反驳材料。
这种灵活性是传统线性方法望尘莫及的。
研究团队还做了个有趣的对比实验,他们让系统分别用传统方法和新方法处理同样的问题,然后记录每一步的信息增量。
结果发现,传统方法的信息积累是线性的,而新方法呈现出一条优美的凸曲线——前期快速积累核心信息,后期精雕细琢。
这项技术的商业价值不言而喻。
首先是效率得到了很大提升,同样质量的报告,新方法能节省近一半的计算资源。
对于动辄烧钱几百万美元训练模型的AI公司来说,这是实打实的成本节约。
其次是用户体验,传统AI助手生成报告要等很久,因为它得把所有搜索做完才能开始写。
新方法边搜边写,用户能更早看到初步结果,体验自然更好。
最关键的是技术护城河。
这套方法不需要重新训练模型,只要在推理阶段应用就行。这意味着任何公司都能快速部署,但真正做好需要大量工程优化。
谷歌凭借在扩散模型上的深厚积累,暂时领先一个身位。
当然,TTD-DR也不是完美的。
论文坦承,系统目前只支持文本搜索,不支持浏览网页或执行代码。
这在某些场景下是硬伤,比如分析最新的财报数据,如果不能直接访问公司官网,就只能依赖可能过时的二手信息。
另一个问题是可解释性。
系统内部的多次迭代和自我进化过程就像个黑箱,很难说清楚某个结论是怎么得出的。
对于需要严格溯源的学术研究或法律文书,这可能是个大问题。
成本也是个考量因素,虽然相对效率提升了,但绝对成本仍然不低。
每生成一份深度报告,背后是几十次的模型调用。
对于个人用户可能还好,企业级应用的成本压力不小。
认知科学家早就发现,人类思维的精妙之处不在于一次就想对,而在于不断修正的能力。
从这个角度看,TTD-DR让AI向真正的智能又迈进了一步。
谷歌这次的创新,本质上也是一次向人类学习的回归。