
华为的芯片节奏,全面走上了新轨道。
继余承东三折叠手机发布会上亮相麒麟芯片后,AI算力芯片也有了最新进展。
就在华为全联接大会上,轮值董事长徐直军,带来了全球最强算力超节点和集群!
Atlas 950 SuperPoD和Atlas 960 SuperPoD超节点,分别支持8192及15488张昇腾卡。
Atlas 950 SuperPoD预计在2026年第四季度上市,完全超越英伟达预计在2027年上市的NVL576,在未来2年内保持全球算力第一。
同时还发布了全球最强超节点集群,分别是Atlas 950 SuperCluster和Atlas 960 SuperCluster,算力规模分别超过50万卡和达到百万卡,同样坐稳全球最强集群宝座。
此外,华为还公布了昇腾芯片、鲲鹏芯片未来2年的演进规划。包括昇腾950系列/960系列,鲲鹏950/960等。
华为轮值董事长也坦承,由于制程和流片方面的原因,“短期在单芯片性能上和英伟达有差距”……
但是,可以通过极致的系统架构和互联技术,将大量芯片整合成一个“超级计算机”,在集群级别实现全面超越。

明年Q1推出昇腾950PR,采用华为自研HBM
芯片方面,华为将坚持“一年一代,算力翻倍”的节奏,持续演进数据格式和带宽技术,以满足AI算力增长的无限需求。
由此公布了昇腾950系列、昇腾960系列和昇腾970系列的演进路线。
昇腾950系列
昇腾950芯片架构亮点如下:
具体芯片如下:
昇腾950PR
定位:面向推荐(Recommendation)和偏好(Prefill)场景的推理(Inference)优化芯片。
推出这款芯片是因为随着AIGC发展,输入上下文越来越长,计算资源消耗增大。在电商、内容平台和社交媒体中,推荐算法需要更高的准确度和更低的时延。
技术创新:采用华为自研HBM内存方案,可显著降低成本。
产品形态:标准卡和超节点服务器。
上市时间:2026年第一季度。
昇腾950DT
定位:面向训练(Training)和深度学习(Deep Learning)场景。
技术创新:
采用自研HBM:HiZQ 2.0
内存容量高达144GB,访问带宽达4TB/s。
互联带宽提升至2TB/s。
支持FP8、MXFP8、MXFP4、HF8等多种数据格式,提升训练效率。
上市时间:2026年第四季度。
昇腾960(规划中)
定位:旗舰训练芯片,各项规格相比昇腾950实现翻倍提升。
技术创新:
算力、内存容量、访问速度、互联端口数全面翻倍。
支持华为自研的Hi-F4数据格式,它是目前业界最优的4bit精度实现,能进一步提升推理吞吐,并且比业界FP4方案的推理精度更优。
上市时间:2027年第四季度。
昇腾970(规划中)
定位:全面升级的训练芯片,各项指标大幅提升。
初步规格:相比昇腾960,FP4、FP8算力全面翻倍,内存访问带宽提升至少1.5倍。
上市时间:2028年第四季度。
Atlas 950:预计未来2年保持全球第一
华为副董事长、轮值董事长徐直军坦言,华为在单芯片制造上受到限制,但是通过过去30年在基础软件和系统架构上的积累,可以通过极致的算力架构和互联技术,将大量芯片整合成一个“超级计算机”,从而在集群层面实现超越。
超节点(SuperNode)是将大量计算单元(如芯片、服务器)通过高速互联技术整合成一台逻辑上统一的、能像单台计算机一样学习、思考和推理的巨型AI计算机。它正成为AI基础设施建设的新范式。
目前华为现有Atlas 900 A3超节点,支持384颗昇腾910C芯片。最大算力达300PFlops,至今仍是全球算力最强的AI超节点。自上市以来,已交付超300套,服务20多家客户。
Atlas 950超节点
此次最新发布Atlas 950超节点。
支持8,192张昇腾950DT芯片,规模是Atlas 900的20多倍。
它由128个计算柜和32个互联柜组成,占地约1000平方米,采用全光连接。
关键指标如下:
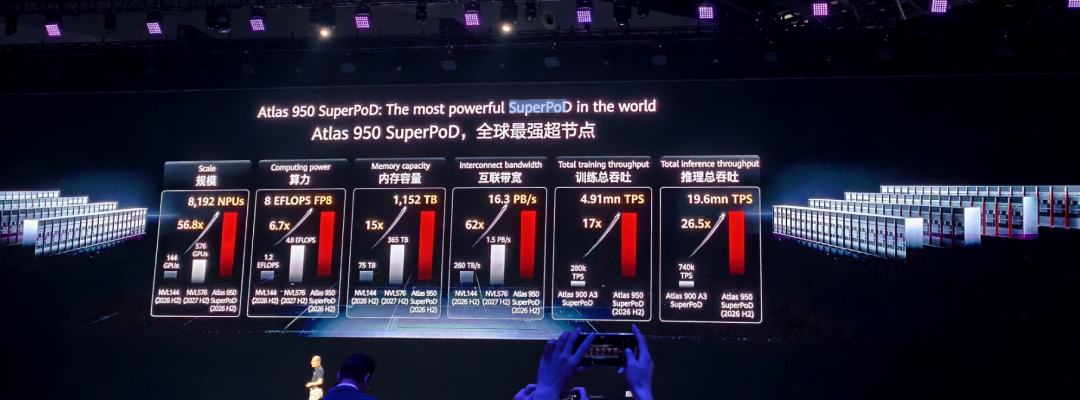
相比英伟达2025年将上市的NVL144,卡规模是其56.8倍,总算力是其6.7倍,内存容量是其15倍,互联带宽是其72倍。
Atlas 950 超节点上市时间为2026年第四季度。预计在未来两年内保持全球算力第一。
Atlas 960超节点
一同发布的还有Atlas 960 超节点 。
它基于昇腾960/昇腾950DT芯片,最大支持15,488卡。使用跨柜全光互联。
关键指标在Atlas 950基础上再度翻番:
FP8算力:30 EFlops
FP4算力:60 EFlops
内存容量:4460 TB
互联带宽:34 PB/s
大模型训练和推理性能相比Atlas 950提升3-4倍。
预计在2027年第四季度上市。
开创面向超节点的互联协议灵衢
超节点技术不仅用于AI,同样重塑通用计算。
华为发布鲲鹏950、鲲鹏960芯片以及对应超节点。

鲲鹏950处理器:
版本:96核/192线程;192核/384线程
特性:支持机密计算,新增四层安全隔离。
上市时间:2026年第一季度。
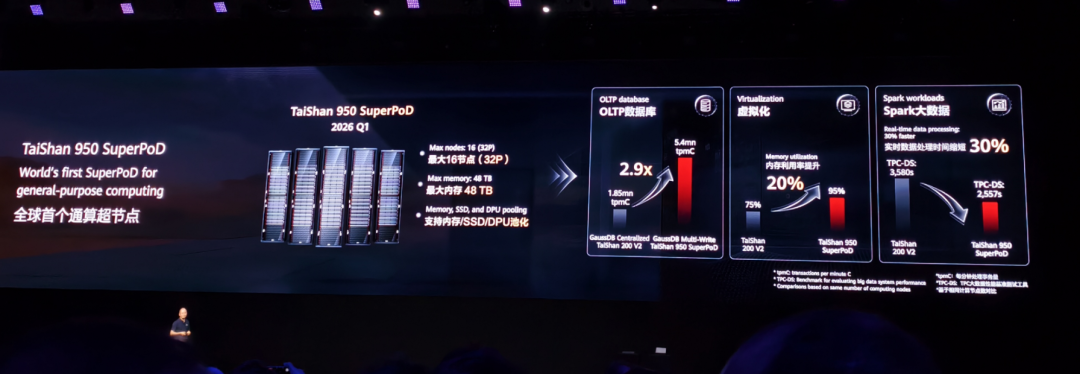
基于鲲鹏950,组成泰山950超节点。
这将是全球首个通用计算超节点。最大支持16节点,32个处理器,最大内存48TB。同时支持内存、SSD、DPU池化。
基于TaiShan 950超节点打造的GaussDB读写架构无需对数据库进行分布式改造,性能提升2.9倍。
最终可平滑替代大型机、小型机上的传统数据库。TaiShan 950加上分布式GaussDB将成为各类大型机、小型机的终结者,彻底取代各种应用场景的大型机和小型机以及Oracle的Exadata数据库服务器。
除了核心数据库场景,TaiShan 950超节点在更广泛的场景里,表现也很亮眼:比如虚拟化环境的内存利用率提升20%,在Spark大数据场景,实时数据处理时间缩短30%。
上市时间为2026年第一季度。
构建万卡超节点的最大挑战在于互联技术。华为通过系统性创新攻克了两大难题:
第一是如何做到长距离而且高可靠。大规模超节点机柜多,柜间联接距离长,当前电互联和光互联技术都不能满足需求。其中,当前的电互联技术在高速时联接距离短,最多只能支持两柜互联,而当前的光互联技术虽然可以把长距离的多机柜联接在一起,但无法满足可靠性需求。
第二是如何做到大带宽而且低时延。当前跨柜卡间互联带宽低,和超节点的需求差距达5倍;跨柜的卡间时延大,当前互联技术最好只能做到3微秒左右,和Atlas 950/960设计需求仍然有24%的差距,当时延已经低至2~3个微秒时,已经逼近物理极限,哪怕0.1微秒的提升,挑战都很大。

基于此,华为开创了灵衢(UnifiedBus) 互联协议,并正式开放云衢2.0技术规范,邀请产业伙伴共建生态,推动超节点产业发展。

最后,华为还有大招放出,发布超级集群:Atlas 950 SuperPlus集群。
它由64个Atlas 950超节点并联组成,整合52万颗昇腾950T芯片。
总算力达524 EFlops。支持UBOE和RoCE两种组网协议,UBOE在时延、可靠性和成本上更具优势。
上市时间为2026年第四季度。

另外Atlas 960 SuperPlus集群也在规划中。
规模将达百万卡级,FP8总算力达2 ZFlops,FP4达4 ZFlops。上市时间为2027年第四季度。
最后,徐直军强调,华为将以基于灵衢的超节点和集群持续满足算力快速增长的需求,推动人工智能持续发展,创造更大的价值。
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
🏆 年度科技风向标「2025人工智能年度榜单」评选报名开启啦!我们正在寻找AI+时代领航者 点击了解详情
❤️🔥 企业、产品、人物3大维度,共设立了5类奖项,欢迎企业报名参与 👇

一键关注 👇 点亮星标
内容中包含的图片若涉及版权问题,请及时与我们联系删除
