
Key Takeaways:
We've collaborated with NVIDIA to deliver NVIDIA TensorRT-optimized versions of Stable Diffusion 3.5 (SD3.5), making enterprise-grade image generation available on a wider range of NVIDIA RTX GPUs.
The SD3.5 TensorRT-optimized models deliver up to 2.3x faster generation on SD3.5 Large and 1.7x faster on SD3.5 Medium, while reducing VRAM requirements by 40%.
The optimized models are now available for commercial and non-commercial use under the permissive Stability AI Community License.You can download the weights on Hugging Face and code on NVIDIA’s GitHub.

In collaboration with NVIDIA, we've optimized the SD3.5 family of models using TensorRT and FP8, improving generation speed and reducing VRAM requirements on supported RTX GPUs.
SD3.5 was developed to run on consumer hardware out of the box. The Nvidia optimizations extend that accessibility further for creative professionals and developers working across a variety of hardware setups.
Where the models excel
These performance improvements make SD3.5's core strengths more accessible. SD3.5 excels in the following areas, making it one of the most customizable image models on the market, while maintaining top-tier performance in prompt adherence and image quality:
Versatile Styles: Capable of generating a wide range of styles and aesthetics like 3D, photography, painting, line art, and virtually any visual style imaginable.
Diverse Outputs: Creates images representative of the world, not just one type of person, with different skin tones and features, without the need for extensive prompting.
Prompt Adherence: Our analysis shows that SD3.5 Large leads the market in prompt adherence, allowing the model to closely follow a given text prompt, making it a top choice for efficient, high-quality performance.
Now available across more NVIDIA RTX GPUs
TensorRT optimization reduces model size while maintaining quality by streamlining how models run on NVIDIA hardware. Model size reduction is achieved through FP8 quantization, a technique that makes models more efficient while maintaining high output quality. These improvements mean that five RTX 50 Series systems can now run SD3.5 Large from memory, compared to just one system before optimization.
Enhanced performance across NVIDIA RTX GPUs
SD3.5 TensorRT-optimized models run more efficiently across NVIDIA GeForce RTX 50 and 40 Series GPUs, as well as NVIDIA Blackwell and Ada Lovelace generation NVIDIA RTX PRO GPUs. They deliver up to 2.3x faster generation on SD3.5 Large and 1.7x faster on SD3.5 Medium, while reducing VRAM requirements by 40%.
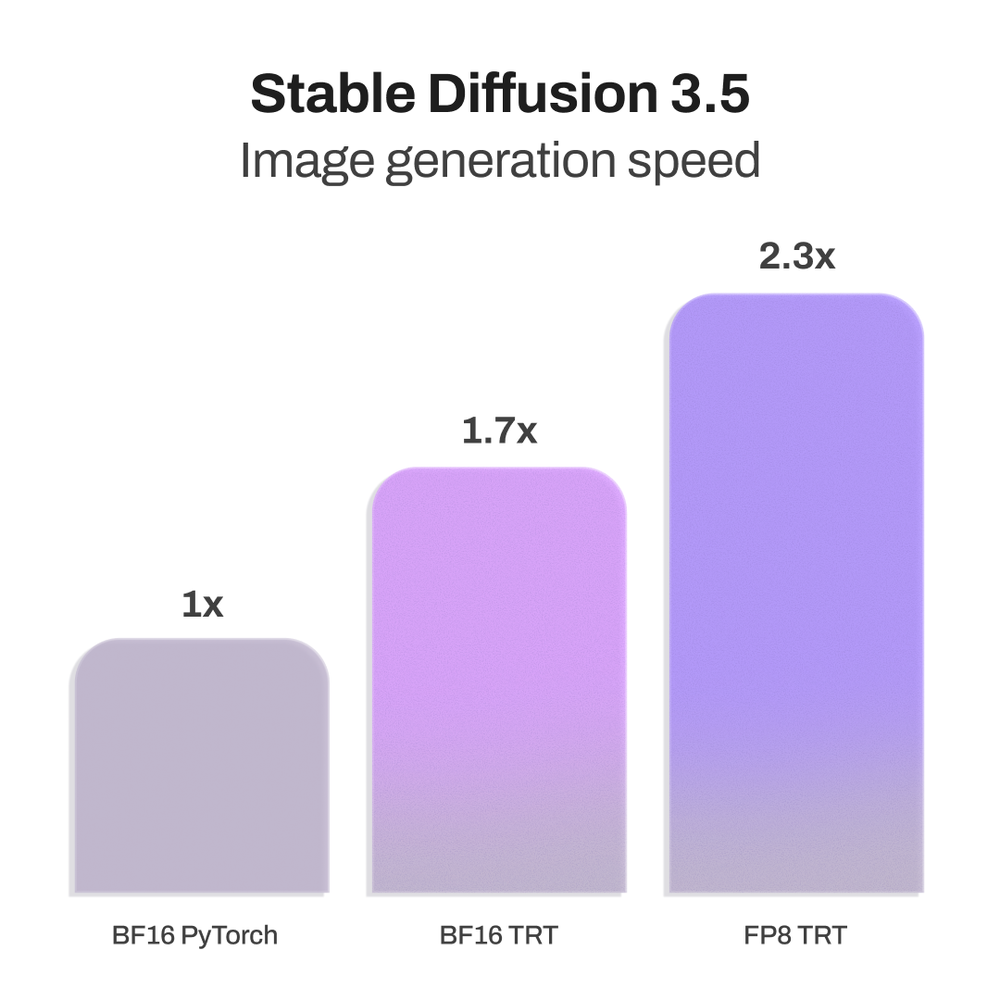
FP8 TensorRT boosts SD3.5 Large performance by 2.3x vs. BF16 PyTorch, with 40% less memory use. For SD3.5 Medium, BF16 TensorRT delivers a 1.7x speedup.
SD3.5 Large
2.3x faster image generation compared to compared to the base PyTorch models.
Memory use reduced by 40%, from 19GB to 11GB, all while maintaining professional quality.
SD3.5 Medium
1.7x faster image generation for users prioritizing speed and efficiency.
Lower memory footprint, ideal for creators working on mid-range RTX hardware.
Getting started
The optimized models are now available for commercial and non-commercial use under the permissive Stability AI Community License.You can download the weights on Hugging Face and code on NVIDIA’s GitHub.
To stay updated on our progress, follow us on X, LinkedIn, Instagram, and join our Discord Community.
