

Have you ever worried about the costs of using ChatGPT for your projects? Or perhaps you work in a field with strict data governance rules, making it difficult to use cloud-based AI solutions?
If so, running Large Language Models (LLMs) locally could be the answer you've been looking for.
Local LLMs offer a cost-effective and secure alternative to cloud-based options. By running models on your own hardware, you can avoid the recurring costs of API calls and keep your sensitive data within your own infrastructure. This is particularly beneficial in industries like healthcare, finance, and legal, where data privacy is paramount.
Experimenting and tinkering with LLMs on your local machine can also be a fantastic learning opportunity, deepening your understanding of AI and its applications.
What is a local LLM?
A local LLM is simply a large language model that runs locally, on your computer, eliminating the need to send your data to a cloud provider. This means you can harness the power of an LLM while maintaining full control over your sensitive information, ensuring privacy and security.
By running an LLM locally, you have the freedom to experiment, customize, and fine-tune the model to your specific needs without external dependencies. You can choose from a wide range of open-source models, tailor them to your specific tasks, and even experiment with different configurations to optimize performance.
While there might be upfront costs for suitable hardware, you can avoid the recurring expenses associated with API calls, potentially leading to significant savings in the long run. This makes local LLMs a more cost-effective solution, especially for high-volume usage.
Can I run LLM locally?
So, you're probably wondering, "Can I actually run an LLM on my local workstation?". The good news is that you likely can do so if you have a relatively modern laptop or desktop! However, some hardware considerations can significantly impact the speed of prompt answering and overall performance.
Let’s look at 3 components you’ll need to experiment with local LLMs.
Hardware requirements
While not strictly necessary, having a PC or laptop with a dedicated graphics card is highly recommended. This will significantly improve the performance of LLMs, as they can leverage the GPU for faster computations. Without a dedicated GPU, LLMs might run quite slowly, making them impractical for real-world use.
The GPU's video RAM (vRAM) plays a pivotal role here: it determines the maximum size and complexity of the LLM that can be loaded and processed efficiently. More vRAM allows larger models to fit entirely on the GPU, leading to significantly faster speeds, as accessing model parameters from vRAM is orders of magnitude quicker than from standard system RAM.
LLMs can be quite resource-intensive, so it's essential to have enough RAM and storage space to accommodate them. The exact requirements will vary depending on the specific LLM you choose, but having at least 16GB of RAM and a decent amount of free disk space is a good starting point.
Software requirements
Besides the hardware, you also need the right software to effectively run and manage LLMs locally. This software generally falls into three categories:
- Servers: these run and manage LLMs in the background, handling tasks like loading models, processing requests, and generating responses. They provide the essential infrastructure for your LLMs. Some examples are Ollama and Lalamafile.User interfaces: these provide a visual way to interact with your LLMs. They allow you to input prompts, view generated text, and potentially customize the model's behavior. User interfaces make it easier to experiment with LLMs. Some examples are OpenWebUI and LobeChat.Full-stack solutions: these are all-in-one tools that combine the server and the user interface components. They handle everything from model management to processing and provide a built-in visual interface for interacting with the LLMs. They are particularly suitable for users who prefer a simplified setup. Some examples are GPT4All and Jan.
Open source LLMs
Last, but not least, you need the LLMs themselves. These are the large language models that will process your prompts and generate text. There are many different LLMs available, each with its own strengths and weaknesses. Some are better at generating creative text formats, while others are suited for writing code.
Where can you download the LLMs from? One popular source for open-source LLMs is Hugging Face. They have a large repository of models that you can download and use for free.
Next, let's look at what are some of the most popular LLMs to get started with.
Which LLMs to run locally?
The landscape of LLMs you can run on your own hardware is rapidly expanding, with newer, more capable, or more specialized models being released every day!
Many powerful open-source models are available, catering to a wide range of tasks and computational resources. Let's explore some popular options, categorized by their general capabilities and specializations!
General-purpose model families
Several families of models have gained significant popularity in the open-source community due to their strong performance across various benchmarks and tasks.
- Llama (Meta AI): The Llama series, particularly Llama 3 and its variants, are highly capable models known for their strong reasoning and general text generation abilities. They come in various sizes, making them adaptable to different hardware setups. The newest iteration, Llama 4, has been released, however, its size exceeds the capabilities of standard hardware for now.Qwen (Alibaba Cloud): The Qwen family offers a range of models, including multilingual capabilities and versions optimized for coding. They are recognized for their performance, and tool calling abilities. Qwen 2.5 has extremely good performance, especially compared to its size. The recently launched Qwen 3 is even better across benchmarks!DeepSeek: DeepSeek models, including the DeepSeek-R1 series, are often highlighted for their reasoning and coding proficiency. They provide strong open-source alternatives with competitive performance.Phi (Microsoft): Microsoft's Phi models focus on achieving high performance with smaller parameter counts, making them excellent candidates for resource-constrained local setups while still offering surprising capabilities, particularly in reasoning and coding.Gemma (Google): Gemma models represent a family of lightweight, state-of-the-art open models built from the same research and technology used to create Gemini models. They are designed to run on a single GPU making them ideal for local deployment! The latest iteration, Gemma 3, offers various sizes (e.g., 1B, 4B, 12B and 27B parameters) and is known for strong general performance, especially considering model size.Mistral (Mistral AI): Mistral AI, a French company, offers a popular family of powerful and efficient open-source models (many under Apache 2.0 license), including the influential Mistral 7B and various Mixtral (Mixture of Experts) versions. These models are known for strong performance in reasoning and coding, come in diverse sizes suitable for local setups, and are praised for their efficiency.Granite (IBM): IBM's Granite models are another family available for open use. The Granite 3.3 iteration, for example, offers variants with 2B and 8B parameters, providing options suitable for different local hardware configurations.
Models with advanced capabilities
Beyond general text generation, many open-source models excel in specific advanced capabilities:
- Reasoning models: Models like DeepSeek-R1 and specific fine-tunes of Llama or Mistral are often optimized for complex reasoning, problem-solving, and logical deduction tasks. Microsoft’s Phi family of models also offer reasoning variants, in the form of
phi4-reasoning and phi4-mini-reasoning.Mixture-of-experts (MoE): This architecture allows models to scale efficiently by activating only relevant "expert" parts of the network for a given input. Qwen 3 is a MoE model, and Granite also has a MoE variant in the form of granite3.1-moe.Tool calling models: The ability for an LLM to use external tools (like APIs or functions) is fundamental to building agentic AI systems. Models are increasingly being trained or fine-tuned with tool-calling capabilities, allowing them to interact with external systems to gather information or perform actions. Frameworks like LangChain or LlamaIndex often facilitate this when running models locally. Examples include qwen3, granite3.3, mistral-small3.1 and phi4-mini.Vision models: sometimes also called multimodal models, are models that can understand and interpret images alongside text. They are becoming more common in the open-source space. Examples include Granite3.2-vision, llama3.2-vision, llava-phi3, and BakLLaVA (which is derived from Mistral 7B).Models that excel at specific tasks
Sometimes, you need a model fine-tuned for a particular domain or task for optimal performance.
- Coding assistants:
- DeepCoder: A fully open-source family (1.5B and 14B parameters) aimed at high-performance code generation.OpenCoder: An open and reproducible code LLM family (1.5B and 8B models) supporting chat in English and Chinese.Qwen2.5-Coder: Part of the Qwen family, specifically optimized for code-related tasks.
- Math and research
- Starling-LM-11B-alpha: Mistral-based model for research and instruction-following.Mathstral: Specialized Mistral AI model for advanced mathematical reasoning.Qwen2-math: Part of the Qwen family, specifically optimized for complex mathematical problem-solving.
- Creative writing
- Mistral-7B-OpenOrca: A fine-tuned version of Mistral AI's base Mistral-7B model, specifically enhanced by training on a curated selection of the OpenOrca dataset.
Choosing the right open-source model depends heavily on your specific needs, the tasks you want to perform, and the hardware you have available. Experimenting with different models is often the best way to find the perfect fit for your local LLM setup.
How to run LLMs locally?
To run LLMs locally, the first step is choosing which model best fits your needs. Once you've selected a model, the next decision is how to run it—most commonly using software like Ollama. However, Ollama isn’t your only option. There are several other powerful and user-friendly tools available for running local LLMs, each with its own strengths.
Let’s explore some of the most popular choices below!
Ollama (+ OpenWebUI)
Ollama is a command-line tool that simplifies the process of downloading and running LLMs locally. It has a simple set of commands for managing models, making it easy to get started.
Ollama is ideal for quickly trying out different open-source LLMs, especially for users comfortable with the command line. It’s also the go-to tool for homelab and self-hosting enthusiasts who can use Ollama as an AI backend for various applications.
While Ollama itself is primarily a command-line tool, you can enhance its usability by pairing it with OpenWebUI, which provides a graphical interface for interacting with your LLMs.
Pros
- Simple and easy to useSupports a wide range of open-source modelsRuns on most hardware and major operating systems
Cons
- Primarily command-line based (without OpenWebUI), which may not be suitable for all users.
LM Studio
LM Studio is a platform designed to make it easy to run and experiment with LLMs locally. It offers a range of tools for customizing and fine-tuning your LLMs, allowing you to optimize their performance for specific tasks.
It is excellent for customizing and fine-tuning LLMs for specific tasks, making it a favorite among researchers and developers seeking granular control over their AI solutions.
Pros
- Model customization optionsAbility to fine-tune LLMsTrack and compare the performance of different models and configurations to identify the best approach for your use case.Runs on most hardware and major operating systems
Cons
- Steeper learning curve compared to other toolsFine-tuning and experimenting with LLMs can demand significant computational resources.
Jan
Jan is another noteworthy option for running LLMs locally. It places a strong emphasis on privacy and security. It can be used to interact with both local and remote (cloud-based) LLMs.
One of Jan's unique features is its flexibility in terms of server options. While it offers its own local server, Jan can also integrate with Ollama and LM Studio, utilizing them as remote servers. This is particularly useful when you want to use Jan as a client and have LLMs running on a more powerful server.
Pros
- Strong focus on privacy and securityFlexible server options, including integration with Ollama and LM StudioJan offers a user-friendly experience, even for those new to running LLMs locally
Cons
- While compatible with most hardware, support for AMD GPUs is still in development.
GPT4All
GPT4All is designed to be user-friendly, offering a chat-based interface that makes it easy to interact with the LLMs. It has out-of-the-box support for “LocalDocs”, a feature allowing you to chat privately and locally with your documents.
Pros
- Intuitive chat-based interfaceRuns on most hardware and major operating systemsOpen-source and community-drivenEnterprise edition available
Cons
- May not be as feature-rich as some other options, lacking in areas such as model customization and fine-tuning.
NextChat
NextChat is a versatile platform designed for building and deploying conversational AI experiences. Unlike the other options on this list, which primarily focus on running open-source LLMs locally, NextChat excels at integrating with closed-source models like ChatGPT and Google Gemini.
Pros
- Compatibility with a wide range of LLMs, including closed-source modelsRobust tools for building and deploying conversational AI experiencesEnterprise-focused features and integrations
Cons
- May be overkill for simple local LLM experimentationGeared towards more complex conversational AI applications.
How to run a local LLM with n8n?
Now that you’re familiar with what local LLMs are, the hardware and software they require, and the most popular tools for running them on your machine, the next step is putting that power to work.
If you're looking to automate tasks, build intelligent workflows, or integrate LLMs into broader systems, n8n offers a flexible way to do just that.
In the following section, we’ll walk through how to run a local LLM with n8n—connecting your model, setting up a workflow, and chatting with it seamlessly using tools like Ollama.
n8n uses LangChain to simplify the development of complex interactions with LLMs such as chaining multiple prompts together, implementing decision making and interacting with external data sources. The low-code approach that n8n uses, fits perfectly with the modular nature of LangChain, allowing users to assemble and customize LLM workflows without extensive coding.
Now, let's also explore a quick local LLM workflow!
With this n8n workflow, you can easily chat with your self-hosted Large Language Models (LLMs) through a simple, user-friendly interface. By hooking up to Ollama, a handy tool for managing local LLMs, you can send prompts and get AI-generated responses right within n8n:
Step 1: Install Ollama and run a model
Installing Ollama is straightforward, just download the Ollama installer for your operating system. You can install Ollama on Windows, Mac or Linux.
After you’ve installed Ollama, you can pull a model such as Llama3, with the ollama pull llama3 command:
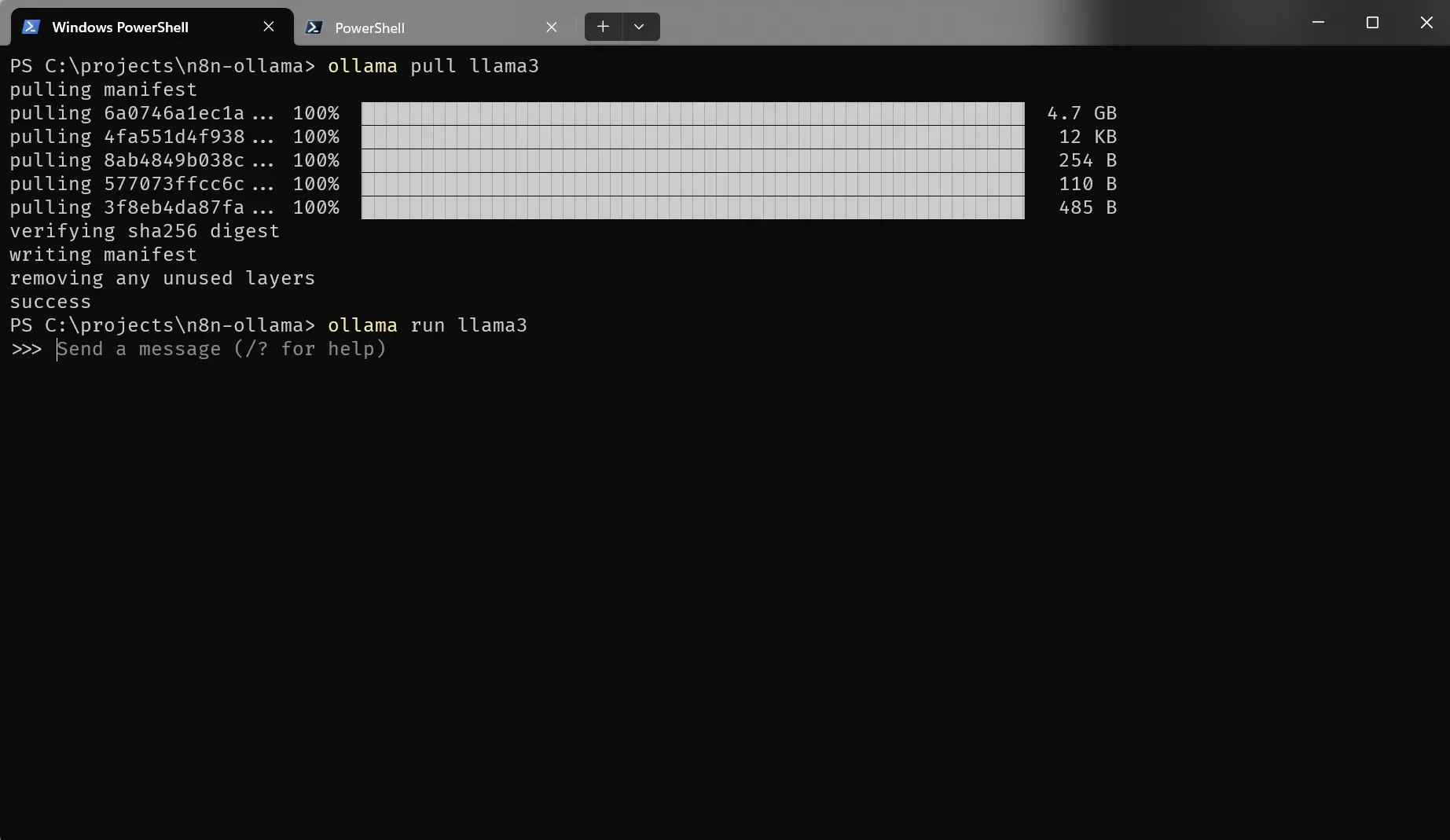
Depending on the model, the download can take some time. This version of Llama3, for example, is 4.7 Gb.After the download is complete, run ollama run llama3 and you can start chatting with the model right from the command line!
Step 2: Set up a chat workflow
Let’s now set up a simple n8n workflow that uses your local LLM running with Ollama. Here is a sneak peek of the workflow we will build:
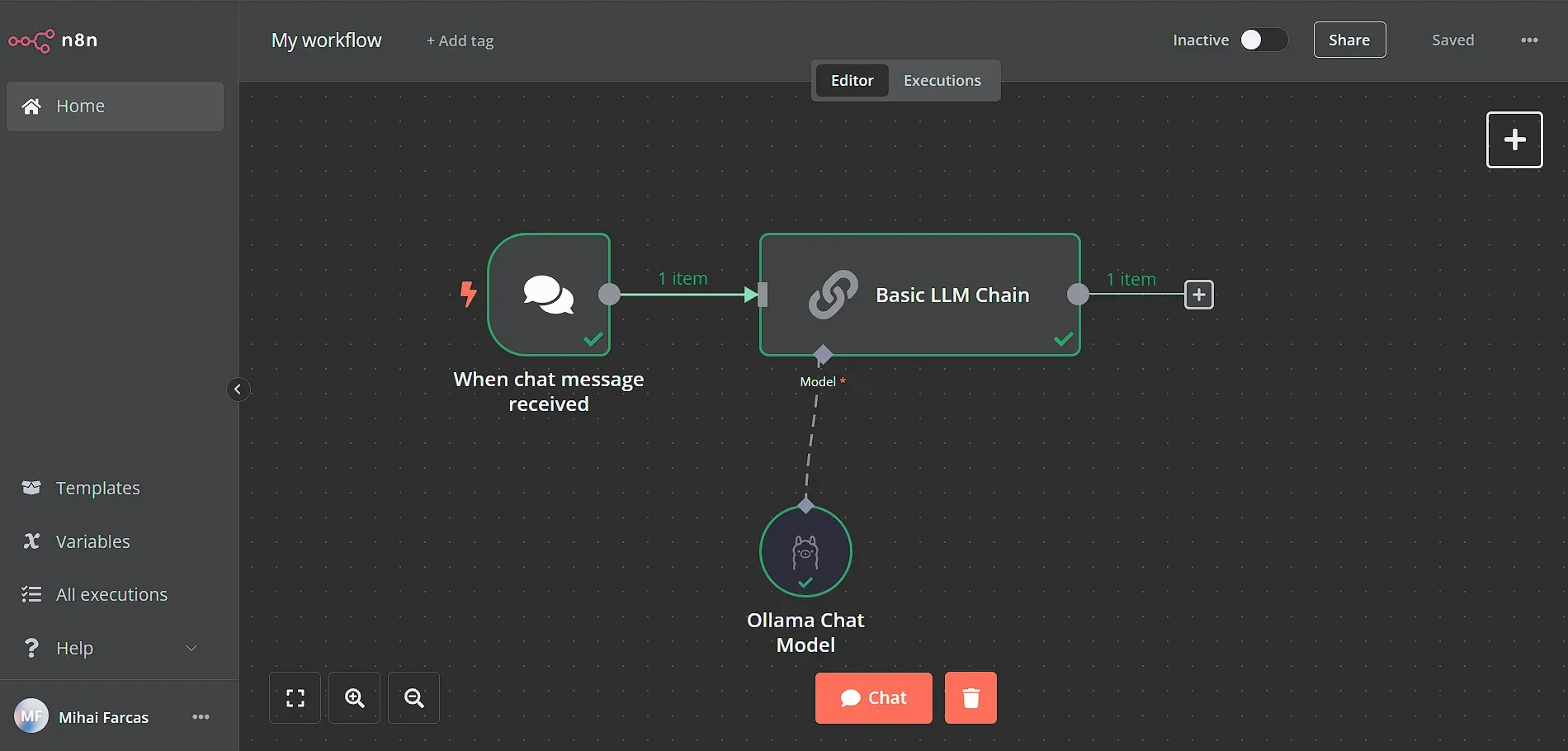
Start by adding a Chat trigger node, which is the workflow starting point for building chat interfaces with n8n. Then we need to connect the chat trigger to a Basic LLM Chain where we will set the prompt and configure the LLM to use.
Step 3: Connect n8n with Ollama
Connecting Ollama with n8n couldn’t be easier thanks to the Ollama Model sub-node! Ollama is a background process running on your computer and exposes an API on port 11434. You can check if the Ollama API is running by opening a browser window and accessing http://localhost :11434, and you should see a message saying “Ollama is running”.
For n8n to be able to communicate with Ollama’s API via localhost, both applications need to be on the same network. If you are running n8n in Docker, you would need to start the Docker container with the --network=host parameter. That way the n8n container can access any port on the host’s machine.
To set a connection between n8n and Ollama, we simply leave everything as default in the Ollama connection window:
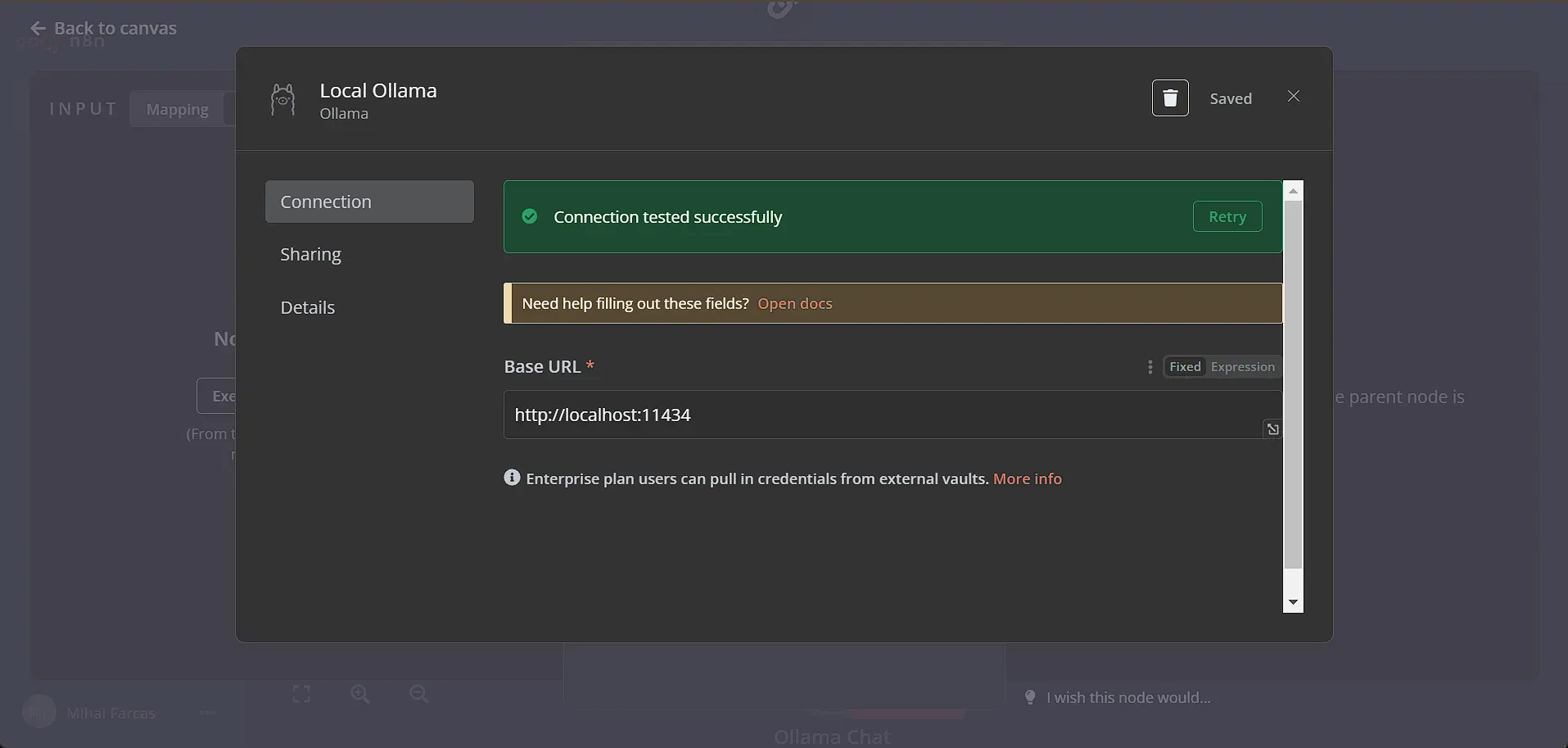
After the connection to the Ollama API is successful, in the Model dropdown you should not see all the models you’ve downloaded. Just pick the llama3:latest model we’ve downloaded earlier.
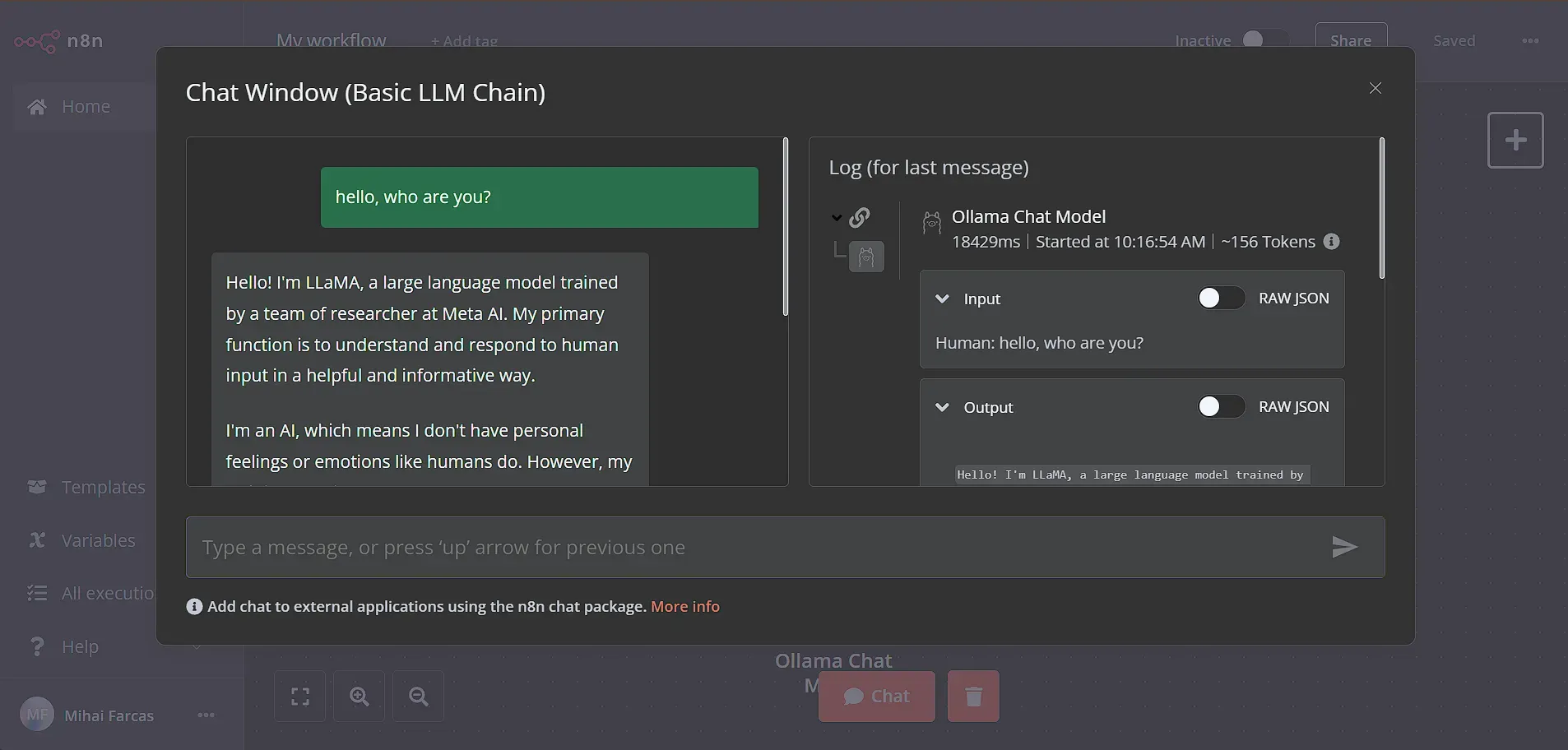
Step 4: Chat with Llama3
Next, let's chat with our local LLM! Click the Chat button on the bottom of the workflow page to test it out. Type any message and your local LLM should respond. It’s that easy!
FAQ
Are local LLMs as good as ChatGPT?
Local LLMs are getting incredibly good, very quickly! Many of them, like some versions of Llama, Qwen, or Gemma, can be amazing for specific jobs you want them to do. If you want an AI that's private because all your data stays with you, a local LLM can be just as good, or even better for that particular need!
Plus, running an LLM locally means you can often use it even without an internet connection, customize it to your heart's content, and you don't have to worry about ongoing subscription fees.
While ChatGPT is an extremely good LLM, local LLMs can be just as good if not better in specific scenarios.
What is the difference between local LLM and online LLM?
The core difference is where the computation happens and who controls the data
Local LLMs:
- Run directly on your own computer or server.
- You control the hardware and software setup.
- Your data (prompts, documents, etc.) remains entirely within your infrastructure.
- Costs are primarily related to hardware; no per-request fees.
Online (Cloud-based) LLMs:
- Run on powerful servers managed by a third-party provider (e.g., OpenAI, Google).
- You access the model usually through an API or web interface.
- Your prompts and potentially other data are sent to the provider's servers for processing.
- Costs are typically based on usage (per token, subscription fees).
- The provider manages the complex infrastructure.
How to run LLM locally for free?
For those looking for a straightforward way to get started with running LLMs locally, Ollama offers a user-friendly experience. After installing Ollama (available for macOS, Windows, and Linux), you can easily download and run a wide variety of open-source models directly from the command line. For instance, to use a model like Deepseek R1, you would typically open your terminal and use a simple command such as ollama pull deepseek-r1:14b to download the 14b parameter varian. Once downloaded, another straightforward command like ollama run deepseek-r1 allows you to start interacting with the model immediately from the command line.
Ollama manages the model files and provides a simple API, abstracting away much of the underlying complexity. You can find a list of available models on the Ollama library page.
What is the cheapest LLM?
While many open-source LLMs are free to download, the real cost of running LLMs locally lies in the hardware needed to run them effectively and the electricity costs. "Cheaper" models in this context are those with lower hardware requirements, which often correlates with the number of parameters they have.
The model itself (or at least significant parts of it) needs to fit into the Video RAM (VRAM) of your graphics card (GPU) for optimal performance. Larger models require more VRAM. For example, running a model that's around 20GB in size efficiently would typically require a graphics card with at least 24GB of VRAM, such as an NVIDIA GeForce RTX 4090 or RTX 3090.
Models with fewer parameters (e.g., 1 billion to 8 billion) are generally "cheaper" to run because they require less VRAM and processing power. They can perform well and quickly on mid-tier consumer hardware. Here are some examples of liter models:
- Llama 3.2 with either 1B or 3B parameters
- Qwen 3 has 0.6B, 1.7B, 4B and 8B parameter versions available
- DeepSeek-R1 (distilled): 1.5B, 7B or 8B parameter models
Models with significantly more parameters (e.g., 14 billion+) offer potentially higher capability but demand more substantial hardware. High-end consumer graphics cards like the NVIDIA GeForce RTX 4090 (24GB), RTX 5090 (32GB) or AMD Radeon RX 7900 XTX (24GB) are often needed. For the very largest models, you might require professional GPUs (like NVIDIA A100/H100) or even multiple GPUs working together, significantly increasing the cost of running local LLMs.
GPUs like NVIDIA GeForce RTX 3060 (12GB), RTX 4060 Ti (16GB), or RTX 4070 (12GB) can often handle these models well. Even some modern integrated graphics or Apple Silicon chips (M-series) can run smaller models, albeit slower than dedicated GPUs.
Cloud-based LLMs follow a similar pattern regarding cost and capability. Providers often offer different tiers:
- Cheaper/Faster Models: Usually smaller or optimized versions (e.g., OpenAI's gpt-4o-mini, Google's gemini-2.0-flash). They are less expensive per token/request but may be less capable for complex reasoning or nuanced tasks.
- More Expensive/Capable Models: State-of-the-art, larger models (e.g., OpenAI's gpt-4o, Google's gemini-2.5-pro). They offer higher performance but come at a higher usage cost.
Is there any open-source LLM?
Yes, absolutely! The open-source LLM landscape is vast and growing rapidly. Many leading AI companies and research institutions release models under open-source licenses.
Popular examples include:
- Meta's Llama series (e.g., Llama 4 and 3.2)
- Mistral AI's models (e.g., Mistral 7B)
- Alibaba's Qwen series (e.g., Qwen 3)
- DeepSeek AI's models (e.g., DeepSeek-R1)
Beyond these, many open-source models are trained to excel in specific areas. Here are some examples:
- Multilingual: Microsoft’s phi4-mini
- Coding: athene-v2, codegemma, deepseek-coder
- Vision (Image Understanding): mistral-small3.1, gemma3, granite3.2-vision
- Reasoning: DeepSeek-R1, QWQ, marco-o1
- Mathematics: mathstral, athene-v2
Wrap up
Running LLMs locally is not only doable but also practical for those who prioritize privacy, cost savings, or want a deeper understanding of AI.
Thanks to tools like Ollama, which make it easier to run LLMs on consumer hardware, and platforms like n8n, which help you build AI-powered applications, using LLMs on your own computer is now simpler than ever!
What’s next?
Now that you've explored how to run LLMs locally, why not dive deeper into practical applications? Check out these YouTube videos:
- Get started with local AI agents: Learn how to Build a Local AI Agent with N8N, Postgres, and Ollama (Free) or explore another comprehensive tutorial on Setting Up Local AI Agents Without Code using similar tools.Explore vector databases with local LLMs: Discover how to Build a Local AI Agent with Qdrant and Ollama to Interact with Your Documents.
And if you're interested in exploring a broader range of AI-powered automations beyond just local LLMs, be sure to check out this selection of workflow templates:
