
近年来,大型多模态模型结合图像工具与强化学习,有效提升了视觉任务的处理能力。然而,现有开源方法普遍存在推理模式单一、交互轮次受限等问题,难以胜任需要反复试探的复杂视觉任务。对此,Mini-o3: Scaling Up Reasoning Patterns and Interaction Turns for Visual Search 提出了一种提升模型工具交互能力的新方法,训练得到 Mini-o3模型,在复杂视觉搜索任务上实现了领先性能。 我们邀请到Mini-o3主创团队成员对论文内容进行直播分享,文末可扫码报名,进行在线交流,以下是论文内容的技术解读。
通过上述训练技巧,Mini-o3在设置训练阶段至多六轮交互轮次的前提下,能够自然生成数十步的多轮推理轨迹,且准确率随推理轮次增加而提升。
大量实验结果表明,Mini-o3不仅具备丰富的推理模式和深度思考能力,还能高效解决复杂的视觉搜索问题。
论文、代码、数据、模型均已开源:https://mini-o3.github.io/
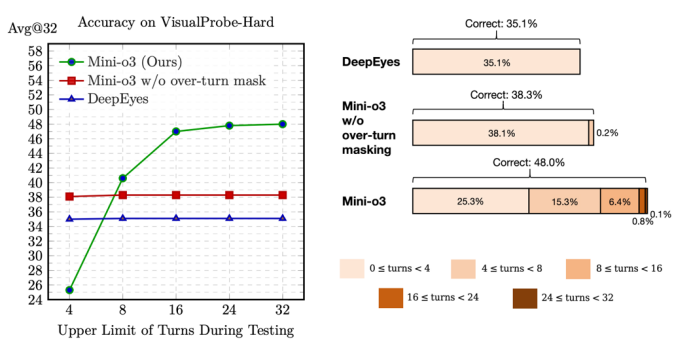
图 1 左图:随着Mini-o3交互轮次上限的提升,其视觉搜索准确率持续增长;右图:测试阶段下,不同交互轮次数对应的正确轨迹分布。Mini-o3展现出更深层次的推理路径和更强的任务表现。尽管在训练阶段设置的轮次上限较低(仅6轮),但模型在测试时具备轮次扩展能力:当最大交互轮次从4提升至32时,准确率持续提升。
2 研究方法
针对用户问题和输入图像,策略模型会迭代地产生思考和动作。
动作通过调用图像编辑工具与环境进行交互,从而获得新的观测结果,该结果会被加入至历史信息中,并在下一轮交互过程中反馈给策略模型。
模型将按照思考-动作-观测不断进行推理循环,直至其返回最终答案,或推理的上下文长度及交互轮数达到预设限制。
思考Ti:策略模型基于交互历史和当前观测,对下一步动作进行决策的内部推理过程。鼓励模型在思考环节展现多样化的推理模式,对复杂问题进行试错探索。
动作Ai: 动作空间包含两种选择:
(1)定位(Grounding);
(2)输出最终答案(Final Answer)。
定位操作的具体参数为:
(1)bbox_2d:归一化的二维边界框,用于指定放大区域;
(2)source:定位所作用的图像,可选 “original_image” 或 “observation_i”,模型可对轨迹中的任意历史观测进行操作。
观测Oi:通过在环境中执行Ai所获得的观测。具体而言,观测为从原始图像或历史观测中裁剪得到的图像区域。

图 2 多轮智能体图像工具的使用流程图示。在每一轮中,模型会基于上一轮的观测迭代生成思考与动作。各轮的观测则根据对应动作所指示的参数获得。
模型训练过程
监督微调(SFT):在数千条涉及图像工具使用的多轮交互轨迹(即冷启动数据)上对模型进行微调,让模型学习生成多样且稳健的推理轨迹;
可验证奖励的强化学习(RLVR):对模型进行监督微调后,采用GRPO方法,通过可验证且具备语义感知能力的奖励信号优化策略。由于强化学习数据中的许多真实答案需要语义匹配而非精确字符串匹配,我们使用外部大语言模型作为评审来计算奖励信号。为保证训练效率与稳定性,训练过程中设置了6轮交互上限和32K的上下文长度限制。
2.2 训练数据构造
Visual Probe Dataset 包含 4000条用于训练的视觉问答对和500个用于测试的样本,覆盖三个难度等级:简单、中等和困难。
与以往的视觉搜索基准(如 V* Bench)相比,Visual Probe具有目标区域小、干扰物体多、图像分辨高等特点,显著提升了任务难度,要求模型进行多轮探索和试错推理。

图 3 Visual Probe数据集示意图。该数据集具有以下特点:(1)目标区域较小;(2)存在大量干扰物体;(3)图像分辨率高。因此,任务极具挑战性,需依赖多轮探索与试错推理。
为应对复杂的探索性任务,研究团队采用冷启动 SFT 激活模型的多轮工具使用能力。利用具备上下文学习能力的现有视觉语言模型(VLM),并通过少量人工编写的示例进行提示,生成高质量、多样化的多轮轨迹。模型将会遵循指令对示例进行模仿,在每一轮迭代中不断生成思考和动作,直至输出最终答案或达到预设轮次上限。
研究仅保留最终答案正确的轨迹进行训练,共采集约6000条冷启动轨迹。
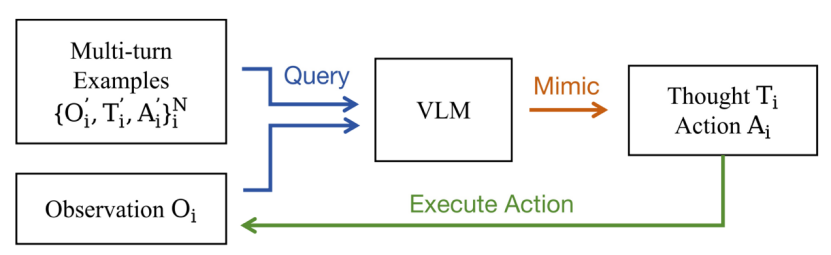
图 4 冷启动数据收集流程图
2.3 强化学习训练
论文采用 GRPO 训练目标进行强化学习训练。
在标准 GRPO 设置下,达到最大轮次或超出上下文长度的响应会被赋予零奖励,归一化后转化为负优势,从而在训练中受到惩罚。这一设计存在两个问题,其一是过长响应的正确性无法确定,直接惩罚会引入标签噪声,影响训练稳定性,其二则是训练阶段轮次上限较低,导致过长响应频繁出现,模型倾向于提前给出答案,限制了多轮推理能力。
为此,论文提出了过长输出掩码(Over-turn Masking)策略,通过引入完成掩码,仅对成功终止的响应计算优势,避免对过长轨迹的负面学习信号,有效提升模型在复杂任务中的多轮推理能力和推理扩展性。
3 实验结果
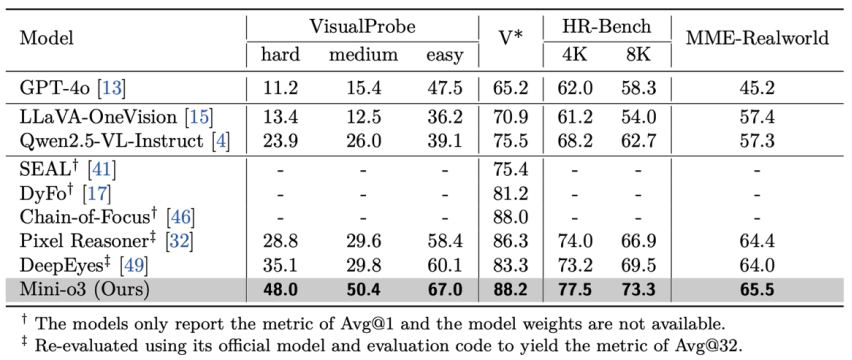
为确保评测的全面性与可靠性,研究团队在 VisualProbe、V* Bench、HR-Bench以及 MME-Realworld 四个数据集上对所有模型进行测试。结果显示,Mini-o3在各数据集上均取得了业界领先的性能,显著优于其他开源基线模型。
研究人员总结,这一优势主要得益于Mini-o3能够支持更复杂、更深入的推理轨迹。
表 1 现有模型与Mini-o3在视觉搜索任务上的性能对比。所有列出的模型规模均为7B。
3.2 消融实验
难样本强化学习数据:对表2中实验1和实验4进行比较。移除困难强化学习数据会导致 VisualProbe-Hard 上性能下降约8.6分,说明高难度样本对于激发复杂推理轨迹至关重要。
冷启动监督微调(SFT):为评估冷启动SFT的必要性,研究人员对比了表2中实验2和实验4。结果显示,冷启动SFT对多轮工具使用不可或缺。推测基础模型在预训练或指令微调阶段缺乏多轮智能体轨迹的学习,冷启动SFT能有效初始化模型能力。
过长输出掩码:对比表2中实验3和实验4,结果表明过长输出掩码对强化学习,尤其在多轮场景下具有显著益处。其优势包括:一是避免对截断响应的不当惩罚,提升训练稳定性;二是支持测试时轮次扩展,在高难度任务中实现更强性能。
表 2 该表展示了对难数据样本、冷启动训练以及过长掩码策略三个组件的消融实验。训练阶段将最大像素数设为100万,交互轮次数上限设为6,实验评测均在VisualProbe测试集上进行。

小结
论文研究了视觉语言模型在多轮图像工具使用场景下的能力。针对需要反复探索与试错的复杂视觉搜索问题,提出了Mini-o3模型,能够生成多样化的推理模式和深层思维链,其推理轨迹可扩展至数十轮,且准确率随轮次增加持续提升,在多个视觉搜索基准上显著优于现有开源模型。
为实现上述能力,论文采用了三项关键技术:首先,构建了包含训练与评测任务的高难度视觉搜索数据集VisualProbe;其次,设计了基于现有视觉语言模型上下文学习能力高效采集冷启动数据的框架;最后,在原始GRPO基础上引入过长输出掩码策略,避免对超出训练轮次上限的响应进行不当惩罚。
该方法不仅支持测试阶段的轮次扩展,还能有效应对极具挑战性的任务,为强化学习和多模态模型的多轮交互发展提供了实用参考。
9月23日(周二) 上午10:30,Mini-o3主创团队成员李俊奕将在智源社区进行直播分享,欢迎扫码报名!

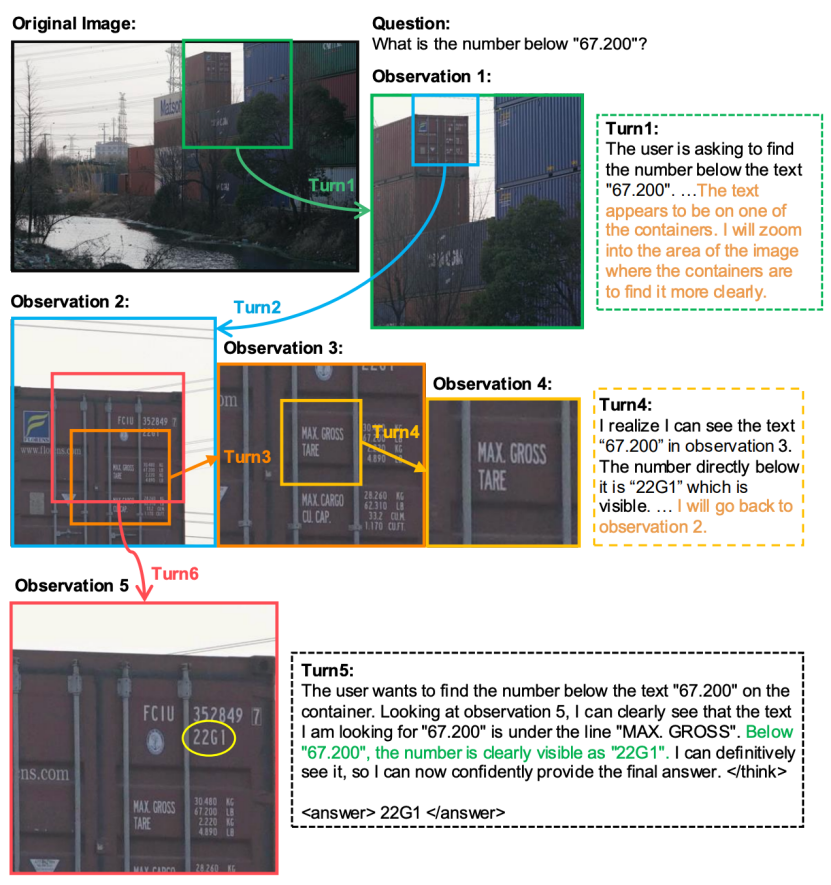
补充:模型效果展示图



内容中包含的图片若涉及版权问题,请及时与我们联系删除
