
Published on September 16, 2025 9:44 PM GMT
TLDR: It is possible LMArena Elo scores are optimizing for persuasiveness, and not for intelligence. Frontier models’ LMArena Elo scores have risen faster than expected over the past year. This could be a result of increased persuasiveness or many other possibilities, including methodological failures, but it is worth being concerned about.
In recent months, as I’ve delved deeper into AI benchmarks, one site that keeps recurring is LMArena. It conveniently scores LLMs on various metrics, but these scores have no units indicated clearly. That puzzle motivated this post, which aims to demystify, as much as current information allows, what the LMArena leaderboards may be measuring. This matters because LMArena's scores historically could be used to make medium-term projections about AI capabilities. Figuring out what these scores represent, beyond correlating with benchmarks, seems crucial. The map is not the territory: if we don’t know what these scores mean in the real world, we risk misunderstanding some of the most interesting AI data available.
Why bother with LMArena when other benchmarks already estimate intelligence? LMArena lets humans judge two models side by side at the same task. The user chooses the prompt and then decides which model gave the better answer. Neither model is labeled, preventing bias toward or against known models. The contests' results are measured by an Elo rating system. As a result, models gain more Elo when beating a strong frontier model than when beating an outdated, weaker one. Elo is a widely used system in chess and other games to rank the strongest players. We do not know how the parameters of the Elo system are set, so we can't say with confidence what kind of "win percentage" gap you would expect for an Elo rating gap of, say 300 points. However, we can say it organizes LLMs into a list ordered by human preference on human-chosen tasks. This looks like a useful benchmark, since human preference is what models are meant to optimize for.
According to Forecasting Frontier Language Model Agent Capabilities, these Elo scores scale linearly with log-FLOP for frontier models. As frontier models grow exponentially in size, their Elo ratings have historically increased linearly. Elo also has scaled linearly with release date. The time-based model is most important, since we may not know a model’s FLOPs but we always know its release date. Since the paper was written over a year ago, new models have been released. The rules consistently underestimate the Elo ratings of models released in mid-2025. For example: take the release year, add the fraction of the year that has passed, multiply by 159.42, then subtract 321514.88. Applied to GPT-5’s release date, the calculation is 2025.6 × 159.42 - 321514.88, which is approximately 1406.
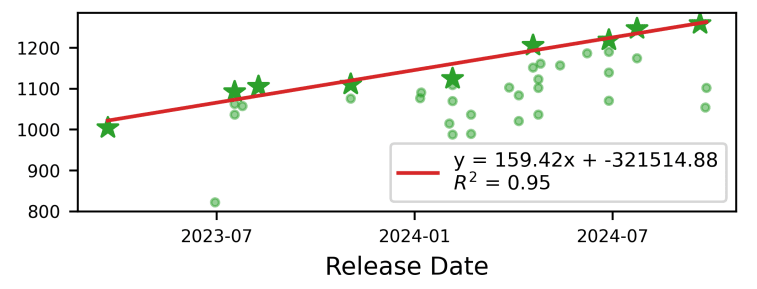
The actual Elo is 1430 for GPT-5-chat on text tasks, and 1442 for GPT-5-high. Notably, since this paper was released, LMArena's methodology appears to have changed. There used to be a single Elo leaderboard, but now the site is split into subcategories for different task types. Many of these tasks only became feasible for LLMs recently. The text leaderboard seems the closest comparison, though that assumption may be faulty. Whatever it may be, the general principle of the time to Elo modeling holding seems true. Other Elo leaderboards that are similarly calibrated find similar results, which is that based solely on time to Elo correlations, GPT5 is slightly stronger than you would expect. Similar results appear for other frontier models released in mid-2025.
LMArena may have given us an enormously important metric of model growth that correlates linearly with time. The only catch is we have no idea what the metric is actually optimizing for. Elo scores current correlation with benchmarks may not last. This modeling choice has to be justified. The modeling choice needs justification, especially if Elo represents something other than the “best” answers, which it probably does. I propose persuasion as an alternative view of what is being optimized for by Elo rating systems like LMArena. Since humans grade the outputs and many questions lack clear answers, the system may optimize for persuasiveness. It is notable that many of the most unexpectedly high scorers on LMArena also score quite badly on metrics like the SpiralBench and reinforcing user delusions. For example, Gemini 2.5 Pro scores poorly on the SpiralBench, and it scores highly on reinforcing user delusions. Its Elo is 1455, versus an expected 1384 based on release date. This is a more substantial difference from trend than GPT5, but it easily could be accounted for by Gemini 2.5 Pro being more aligned to being persuasive than being correct. Deepseek's r1 is another example of this phenomenon. It scores incredibly poorly on the SpiralBench, and fairly high in reinforcing user delusions. It is expected to have an Elo score of 1375 based on the time of release, but it has an actual Elo score of 1418.
Previously, time correlated with Elo more accurately than it does now. However, the sample size was small. The true relationship may not be linear with time but follow some other curve. It is also possible that methodology changes are what caused this jump in Elo, and when you account for lower Elo scores in other tasks, things are still pretty much in line with our original linear expectations. It is also possible that inference scaling accounts for the increase. All of these are plausible, since all models, not just untrustworthy ones, are performing better than expected for their release dates. To my knowledge, no frontier models have Elo scores at or below the paper’s linear predictions.
However, it’s possible that all mid-2025 frontier models are persuasive enough to cause the discrepancy. This hypothesis would affect Elo in similar ways. More experiments are needed to differentiate these hypotheses. Especially in the context of concerns about Parasitic AI, where persuasive outputs might destabilize users, it is worth investigating how much persuasion is playing into this change in Elo results. If LLMs were approaching nearly superhuman levels of persuasion, as I argued recently, undue Elo increases could support that hypothesis. At minimum, it doesn't rule it out. I think we should figure out why this discrepancy between modeled Elo scores and actual scores exists, because the risks of nearly superhuman levels of persuasion are high if realized. However, several explanations are possible, and not all are harmful.
To sum up the potential scenarios:
In World A, Forecasting Frontier Language Model Agent Capabilities correctly identified a rule of LLM scaling from time to Elo. In World Z, the paper incorrectly derived this rule. In World Z, there was a different curve that fit the data, and there were too few sample points of frontier models to correctly rule out linear models. Instead, some other kind of model is a better fit for the correlation of Elo with time, or else Elo and time do not really correlate at all.
In World A, more interesting possibilities appear. If this rule was correctly interpreted, there are three potential interpretations of the data. I will call the world where chain of thought models changed the rules World A-1. World A-1 differs from World Z because a new rule became the best predictor once chain-of-thought models were released. On the other hand, world A-2 is also possible, where increased persuasion capabilities in the models, egged on by RLHF, started appearing sometime in 2025, or perhaps even earlier. Because Elo is trained on human feedback, it may now measure the most persuasive answers rather than the best ones. Usually the best answer is also the most persuasive, but as models get smarter and questions harder, persuasion can diverge from correctness. Thus Elo scores may be rising too quickly because they measure persuasion rather than just intelligence. Some combination of World A-1 and World A-2 is also possible. It even is possible that chain of thought reasoning could have caused or exacerbated existing problems with persuasive models. Finally, there is World A-3, where methodological changes in LMArena's leaderboard make all comparisons apples to oranges, and thus, the increase in LMArena scores is irrelevant to the modeled relationship, even if the modeled relationship was true. I’m curious which scenario seems most plausible to other people. I can imagine all of them being true.
Discuss
