
Published on September 16, 2025 5:51 AM GMT
Initial Code: MATS_Jailbreak_Prompts_Interp.ipynb by Harsh Raj
TL;DR SAE neurons can mean refusal in one language and something else in another. For this reason, I became skeptical about the usefulness of SAEs in the multilingual jailbreak mech interp. Limitations apply
Abstract
Models prompted in Low‑resourced languages are jailbroken at higher rates than those in high‑resourced languages. Initially, I wanted to explain this with language‑specific “distractors” -- co‑activations that undermine refusal features. One of my core assumptions was wrong: features that signal “refusal” in English don’t keep the same meaning in other languages. With that stability gone, the “distractors” idea no longer works as the main explanation[1]. I’m pivoting the research to measure this semantic shift. In short: a neuron that indicates refusal in English can indicate non-refusal in other languages. I’ll show what may be the fundamental limitation of using SAEs for crosslingual jailbreak mechanism interpretation.
Introduction
Safety evaluations over-index on English, while deployment is multilingual. The alignment progress in English does not imply alignment progress in others. While one may argue that English progress is required and must precede due to its influence and popularity, researchers around the world 24/7 fine-tune small/mid language models to achieve either a task-specific boost, language-specific boost or safe deployment. My initial working hypothesis was that low-resourced-language jailbreaks arise from language‑specific “distractors”--co‑activated features that impede the refusal circuit.
However, during mechanistic probing with Sparse Autoencoders (SAEs), my critical assumption failed: features correlated with “refusal” in English do not remain refusal‑like in other languages. In one example (Gemma‑2‑2B‑IT, final‑layer residual, #14018), an English refusal feature aligns with non‑refusal in Japanese. This undermines a theory that presumes stable cross‑lingual semantics at the feature level and explains why “distractors”, at least in my initial definition, were a dead end.
Data used
I used the JailBreakBench with a total of 200 entries. Each entry contained two versions of the prompt: (1) Normal or “pre-jailbreak” and (2) Jailbreak-tailored or “post-jailbreak”. Using gpt-4o-mini API calls, I translated all of those prompts into Japanese, Dutch, and Spanish (see Limitations). Afterwards, I collected activations of the final SAE layer of the gemma2-2b-it residual stream for future analysis (size=16k).
For each prompt, I rendered a 30-tokens long response using gemma-2-2b-it. Then, I used gpt-4o-mini as an LLM-in-a-loop to judge whether the response was an attempt to refuse the answer (so for instance if a response was useless but the model didn’t refuse -- I would count it as a successful jailbreak attempt).
Presupposition 1 (P1): Low-resourced languages do actually get jailbroken more often than higher-resourced languages.
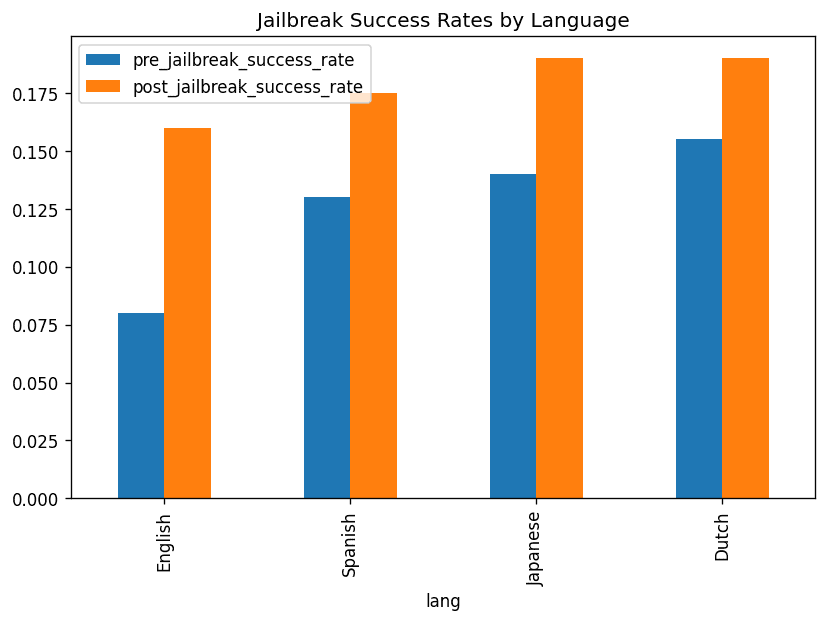
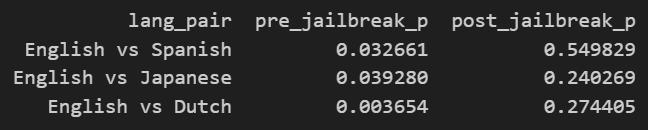
Pre-jailbreak, two-sample tests on refusal rates show English > Spanish/Japanese/Dutch with statistically significant gaps (p<0.05).
Post-jailbreak, the same contrasts are not significant (p=0.55, 0.24, 0.27) and the differences shrink even though they still favor English.
I confirmed this vulnerability that is also widely discussed in prior works. The next presupposition is not covered in existing literature.
Presupposition 2 (P2): the meaning of the neurons in the latent space is crosslingually stable[2].
For each language and neuron, we pair that neuron’s activations with the yes/no refusal label, skipping unusable cases (e.g., constant features).
I then measure the correlation between activation and refusal and convert it to a one-sided p-value using a standard t-test for the hypothesis “higher activation -> more refusals.”
Separately, I fit a simple one-feature logistic model on a z-scored version of that neuron to get a signed coefficient that shows direction (toward refusal or non-refusal) and rough strength.
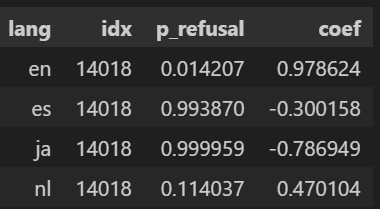
What I found is that the English “refusal” neuron does not transfer across languages. In Gemma-2-2B-IT, layer-12 residual feature #14018 predicts refusal in English (β=+0.979, p=0.014) but flips the sign in Japanese (β=−0.787, p=0.999), aligning with non-refusal. It gives me a hint that there is some loss of semantic stability involved.
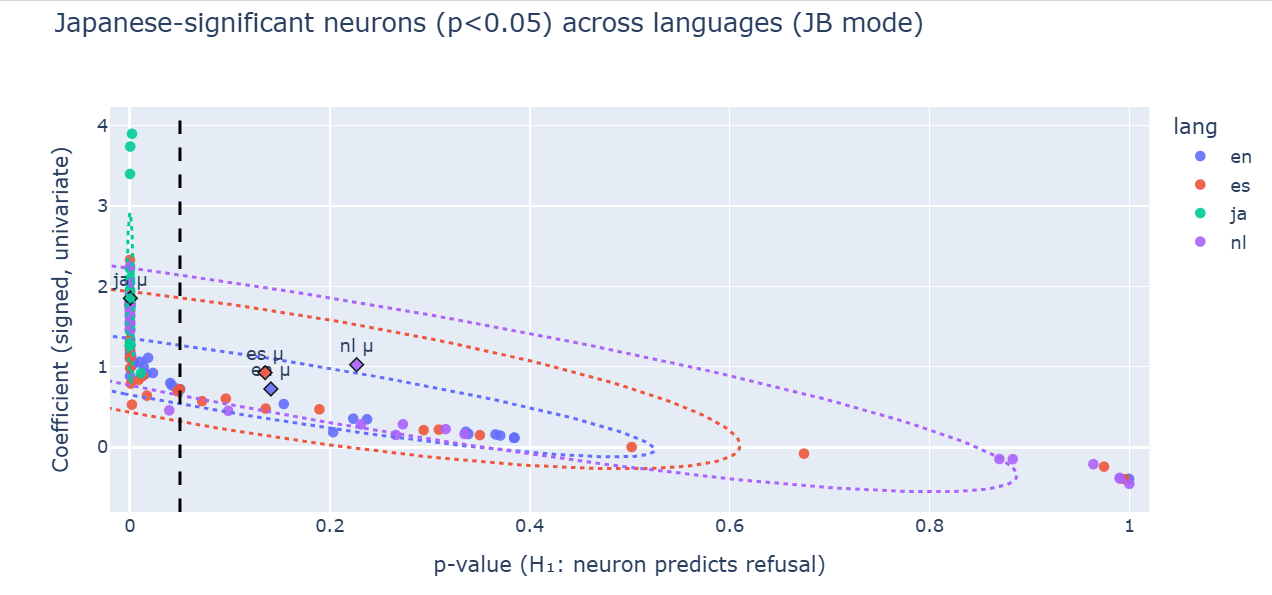
Let’s see if this result holds at scale. Here is this instability visualized over other neurons that were highly correlated with refusal in English but they lost this meaning once the language change occured:
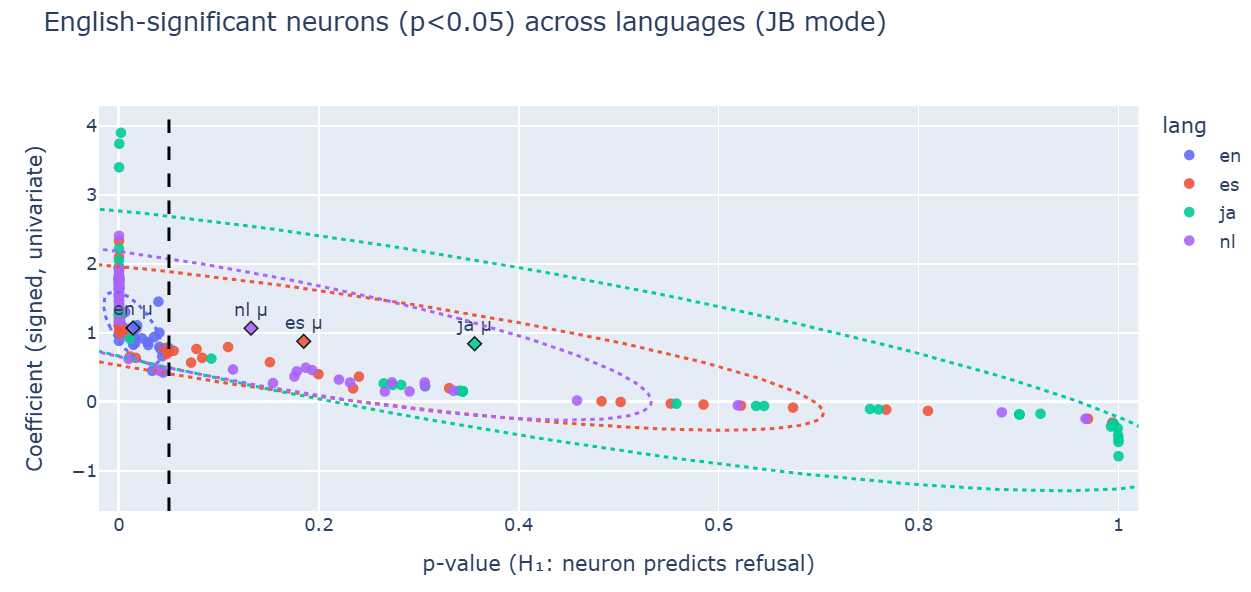
This scatter only includes neurons that were significant in English; if their meaning were stable, the other languages would cluster near the left (low p) with positive coefficients too.
Instead, their points shift rightward (higher p-values) and toward zero or negative coefficients, with Japanese showing the strongest attenuation and several sign flips (below zero).
The dashed line at p=0.05 marks significance; I selected non-English points that fall to the right of it. The per-language centroid/significance_ellipses sit far from the English cluster, visualizing both weakened effect sizes and directional drift--i.e., semantic instability of these features across languages, especially post-jailbreak.
Conclusion
I identified dozens of neurons that are significantly correlated with refusal in English. However, across languages, these features show systematic attenuation and frequent sign reversals: most lose predictive power outside English, and some flip direction (from “refusal-aligned” in English to “non-refusal-aligned” in Japanese). The semantic crosslingual instability of neurons is important for the future analysis of the jailbreaking prevention & red-teaming using SAEs. Because of the discovery of semantic instability, my initial description of “distractors” is either meaningless or will require some serious revision.
Future work
Next steps include running ablation studies to confirm the observed semantic shifts on both harmful and benign activations. I will also systematically test how the severity of these shifts scales across different model sizes. Finally, I plan to explore steering experiments to assess whether targeted interventions can stabilize or realign cross-lingual refusal behavior.
Limitations
Given the time limit, I focused only on the final layer of the gemma-2-2b-it SAE activations of the residual stream. Also, Japanese, Dutch, and Spanish are not low-resourced languages; however, Gemma-2-2b is incredibly small and doesn’t provide reliable signal for actual low-resourced languages. Exclusively in the context of this summary, low-resourcedness means “Non-English-resourcedness”. The translation quality was not verified by a human. The result might not generalize to very large language models
Appendix
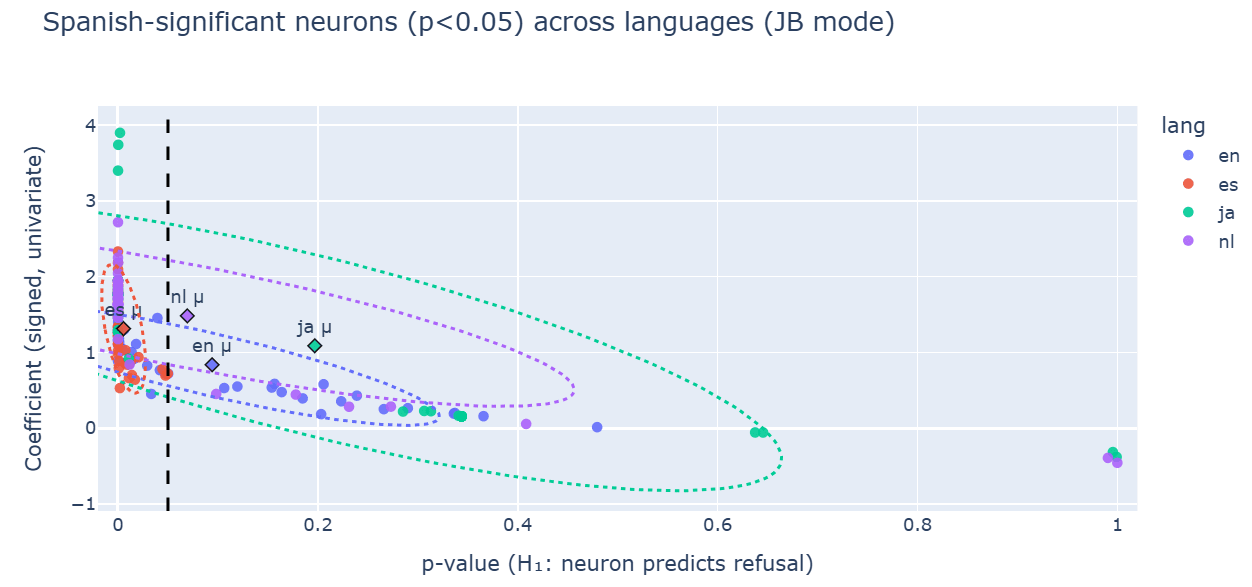
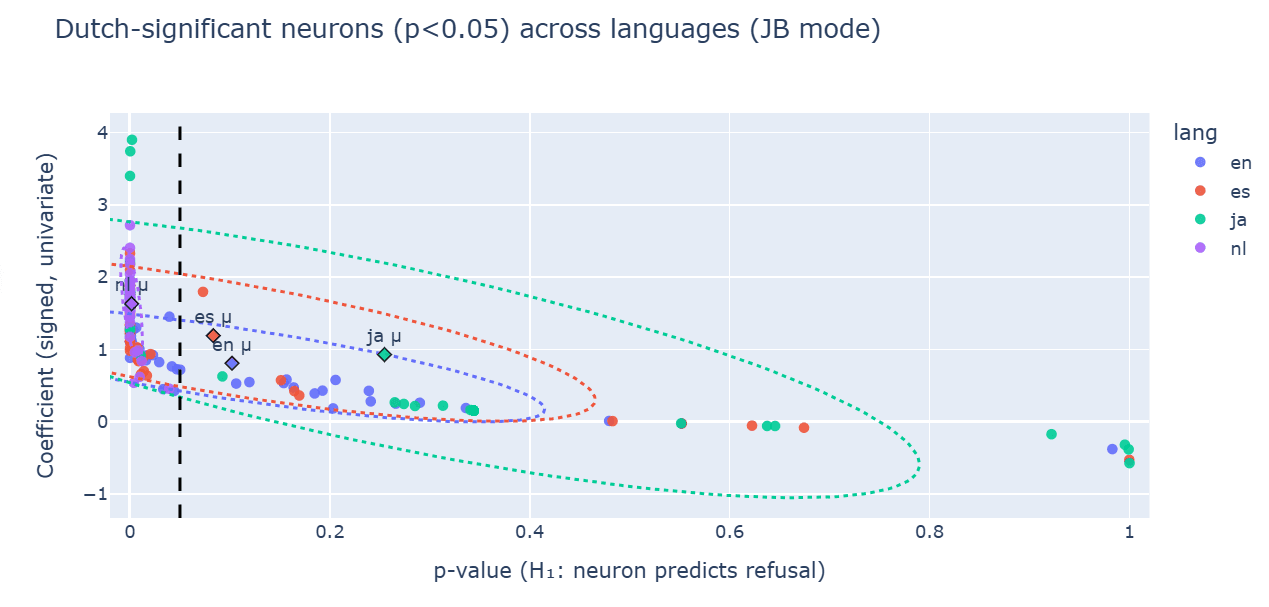
Symmetrical semantic shift is observed in other languages – Japanese, Spanish, Dutch
Data:
Here is the link to the translated prompts and experiment results (both .json and .csv files included). Each file in each language contains the following fields:
“prompt” -- a straightforward malicious request
“response” -- gemma-2-2b answer to the “prompt”
“prompt_refuse” -- gpt-4o-mini judgment on whether gemma-2-2b refused with enough effort
“activations” -- final layer 16k residual stream SAE activations
Suffix “_jb” – same but for the prompt that has been modified to be more jailbreak-effective

- ^
Because “distractors” only make sense if you can anchor them against a stable refusal signal. If the very neuron you call “refusal” in English flips or drifts in another language, then any co-activation you interpret as a “distractor” could simply be the neuron itself changing meaning. Without stable semantics, you can’t tell whether an apparent blocker is really a separate interfering feature or just the same feature being reused differently.
- ^
Here, stable means that if a neuron has a given function in one language, it retains that same function in another language
Discuss
