
Read Online | Sign Up | Advertise

Good morning, {{ first_name | AI enthusiasts }}. Every AI user has experienced it: an LLM’s supremely confident answers that turn out to be completely made up. Now, OpenAI thinks they've finally cracked why chatbots can't stop hallucinating.
The company’s latest research paper suggests that solving AI hallucinations might come down to something surprisingly simple — teaching models that it's okay to say "I don't know."
In today’s AI rundown:
OpenAI reveals why chatbots hallucinate
Anthropic agrees to $1.5B author settlement
Automate web monitoring with AI agents
OpenAI’s own AI chips with Broadcom
4 new AI tools, community workflows, and more
LATEST DEVELOPMENTS
AI RESEARCH
🔬 OpenAI reveals why chatbots hallucinate

Image source: Gemini / The Rundown
The Rundown: OpenAI just published a new paper arguing that AI systems hallucinate because standard training methods reward confident guessing over admitting uncertainty, potentially uncovering a path towards solving AI quality issues.
The details:
Researchers found that models make up facts because training test scoring gives full points for lucky guesses but zero for saying "I don't know."
The paper shows this creates a conflict: models trained to maximize accuracy learn to always guess, even when completely uncertain about answers.
OAI tested this theory by asking models for specific birthdays and dissertation titles, finding they confidently produced different wrong answers each time.
Researchers proposed redesigning evaluation metrics to explicitly penalize confident errors more than when they express uncertainty.
Why it matters: This research potentially makes the hallucination problem an issue that can be better solved in training. If AI labs start to reward honesty over lucky guesses, we could see models that know their limits — trading some performance metrics for the reliability that actually matters when systems handle critical tasks.
TOGETHER WITH CONCIERGE
👋 Your brand's AI answer engine

The Rundown: Today’s SaaS buyers use AI every day to answer their questions, and have no patience for a scavenger hunt. Concierge is a Perplexity-style answer engine, trained on your company, that lives on your website and delivers accurate, personalized responses to ultra-specific questions.
Modern brands use Concierge to:
Handle any buyer question (no matter how technical) with advanced RAG on your sources & media
Control and visibility over every conversation, with guardrails and sentiment analysis
Build trust with website visitors before they are willing to commit to a demo
Use Concierge to turn every question into a conversation — and every conversation into revenue.
ANTHROPIC
💰 Anthropic agrees to $1.5B author settlement

Image source: Ideogram / The Rundown
The Rundown: Anthropic just agreed to pay at least $1.5B to settle a class-action lawsuit from authors, marking the first major payout from an AI company for using copyrighted works to train its models.
The details:
Authors sued after discovering Anthropic downloaded over 7M pirated books from shadow libraries like LibGen to build its training dataset for Claude.
A federal judge ruled in June that training on legally purchased books constitutes fair use, but downloading pirated copies violates copyright law.
The settlement covers approximately. 500,000 books at $3,000 per work, with additional payments if more pirated materials are found in training data.
Anthropic must also destroy all pirated files and copies as part of the agreement, which doesn’t grant future training permissions.
Why it matters: This precedent-setting payout is the first major resolution in the many copyright lawsuits outstanding against the AI labs — though the ruling comes down on piracy, not the “fair use” of legal texts. While $1.5B sounds like a hefty sum at first glance, the company’s recent $13B raise at a $183B valuation likely softens the blow.
AI TRAINING
📝 Automate web monitoring with AI agents
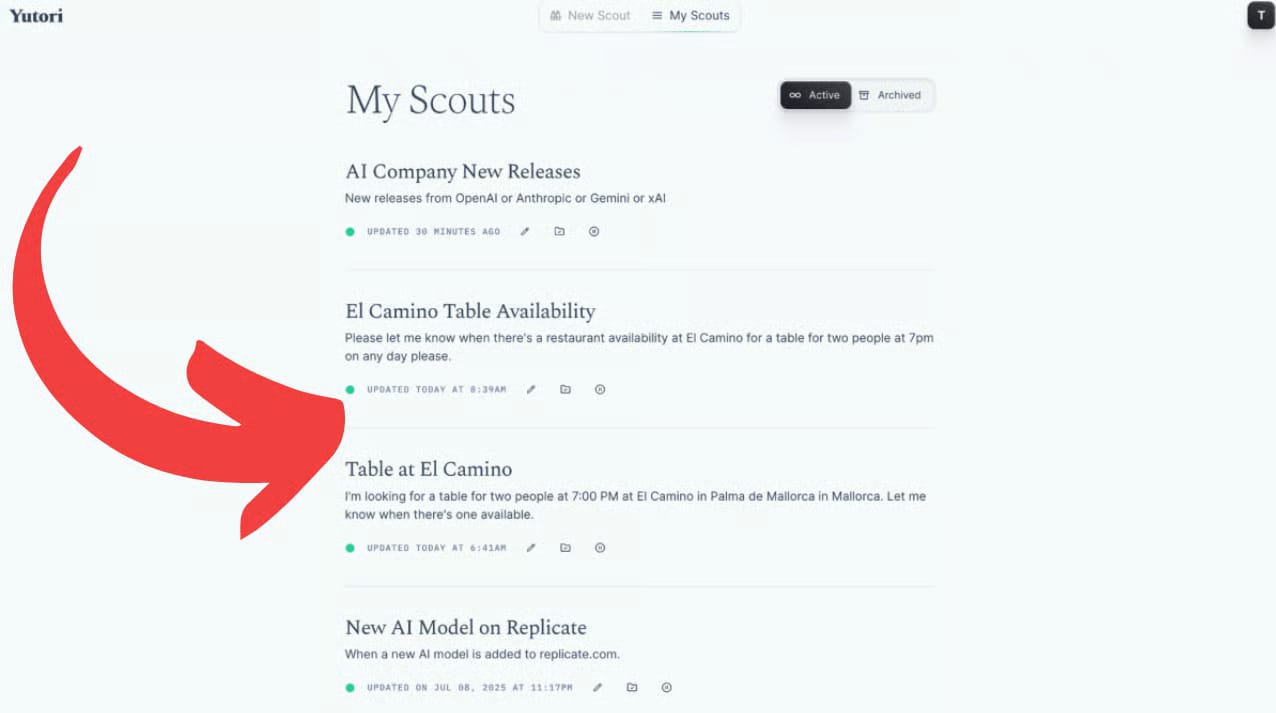
The Rundown: In this tutorial, you’ll learn how to use Yutori Scouts, an AI web monitoring agent that watches for specific updates online and alerts you via email. No more refreshing pages or manually checking for changes.
Step-by-step:
Enter your request in the Yutori homepage input box (e.g., “New releases from OpenAI or Anthropic or Gemini or xAI”) to create your Scout
Choose how often you want alerts — instant, daily, or weekly — then click Start scouting to activate it
View and manage all your active Scouts from the “My Scouts” dashboard, where you can edit, pause, or delete them anytime
Check reports sent to your email or in-app, each with clear findings and a direct link to the source for quick action
Pro tip: Use Scouts for time-sensitive opportunities like reservations, product restocks, or industry news, and pair with automations to get updates.
PRESENTED BY POPCORN
🎬 Agentic workflows now auto-create movies in minutes

The Rundown: Popcorn's agentic product transforms how movies are made. Drop one conceptual prompt and get a complete 1-3-minute movie with narrative arcs, dialogue, lip-sync, soundtrack, and sound effects.
Unlike tools that just produce individual shots, Popcorn handles:
The entire creative process, from ideation to agentic production and auto-editing
Creation of full narrative movies from a single prompt
Instant style, genre, and narrative changes
Consistent character, props, and sets libraries
Try Popcorn and create your first movie for free with code AGENTIC.
OPENAI
🔧 OpenAI’s own AI chips with Broadcom

Image source: Ideogram / The Rundown
The Rundown: OpenAI will begin mass production of its own custom AI chips next year through a partnership with Broadcom, according to a report from the Financial Times — joining other tech giants racing to reduce dependence on Nvidia's hardware.
The details:
Broadcom's CEO revealed a mystery customer committed $10B in chip orders, with sources confirming OpenAI as the client planning internal deployment only.
The custom chips will help OpenAI double its compute within five months to meet surging demand from GPT-5 and address ongoing GPU shortages.
OpenAI initiated the Broadcom collaboration last year, though production timelines remained unclear until this week's earnings announcement.
Google, Amazon, and Meta have already created custom chips, with analysts expecting proprietary options to continue siphoning market share from Nvidia.
Why it matters: The top AI labs are all pushing to secure more compute, and Nvidia’s kingmaker status is starting to be clouded by both Chinese domestic chip production efforts and tech giants bringing custom options in-house. Owning the full stack can also eventually help reduce OAI’s massive costs being incurred on external hardware.
QUICK HITS
🛠️ Trending AI Tools
📱 EmbeddingGemma - Google’s open-source, on-device embedding model
❤️ Lovable Voice Mode - Code and build apps with voice commands
🤖 Qwen3-Max - Alibaba’s massive new 1T parameter model
💄 Higgsfield Ads 2.0 - Create realistic custom AI product placement ads
📰 Everything else in AI today
MongoDB.local NYC, Sep. 17 — Unlock new possibilities for your data in the age of AI. Register here and use code SOCIAL50 to save 50%.*
Alibaba introduced Qwen3-Max, a 1T+ model that surpasses other Qwen3 variants, Kimi K2, Deepseek V3.1, and Claude Opus 4 (non-reasoning) across benchmarks.
OpenAI revealed that it plans to burn through $115B in cash over the next four years due to data center, talent, and compute costs, an $80B increase over its projections.
French AI startup Mistral is reportedly raising $1.7B in a new Series C funding round, which will make it the most valuable company in Europe with a $11.7B valuation.
OpenAI Model Behavior lead Joanne Jang announced OAI Labs, a team dedicated to “inventing and prototyping new interfaces for how people collaborate with AI.”
A group of authors filed a class action lawsuit against Apple, accusing the tech giant of training its OpenELM LLMs using a pirated dataset of books.
*Sponsored Listing
COMMUNITY
🤝 Community AI workflows
Every newsletter, we showcase how a reader is using AI to work smarter, save time, or make life easier.
Today’s workflow comes from reader Avi F. in Portland, ME:
"I plugged my 100+ page health insurance coverage document into a custom GPT and asked it how I can use my coverage and what things cost. It turns out I have free, unlimited therapy via telehealth, and have been able to find answers hidden in otherwise nebulous language. Before AI, I would have had to call, which could take over an hour to get to the right person through customer service, and sometimes they wouldn't even know the answer. This took about five minutes to build and then just a few minutes to ask and get answers."
How do you use AI? Tell us here.
🎓 Highlights: News, Guides & Events
Read our last AI newsletter: OpenAI takes on LinkedIn with jobs platform
Read our last Tech newsletter: OpenAI to make its own AI chip
Read our last Robotics newsletter: Apple loses robotics lead to Meta
Today’s AI tool guide: Automate web monitoring with AI agents
RSVP to our next workshop 9/9 @ 2 PM EST: Intro to agentic development
See you soon,
Rowan, Joey, Zach, Shubham, and Jennifer — the humans behind The Rundown

