

💡 MiniCPM 4.1 亮点一览
🏃首个原生稀疏架构的深思考模型,通过可训练稀疏注意力创新,代码、数学推理等任务的推理速度比同尺寸开源模型快 3 倍以上;
🌟在知识、推理、编程、指令遵循等综合能力方面,达到同级 SOTA 水平;
🪄支持高效双频换挡:长文本用稀疏,短文本用稠密。
➤ 相关链接
🔗 Github 链接:
https://github.com/openbmb/minicpm
🔗 Hugging Face:
https://huggingface.co/openbmb/MiniCPM4.1-8B
🔗 Model Scope:
https://modelscope.cn/models/OpenBMB/MiniCPM4.1-8B

综合性能SOTA
综合能力直接反映了模型的智能水平,我们选择了 C-Eval、CMMLU、MMLU、MMLU-Redux、GSM8K、Math-500、AIME-2024、AIME-2025、HumanEval、MBPP、LCB-v5、LCB-v6、MultiPL-E、IFEval、BBH 等最具代表性的 15 个评测基准,取得综合平均分同尺寸模型第一。

其中,在 CMMLU、MMLU、AIME-2024、HumanEval、BBH 等榜单获得同级最优成绩。

端侧友好
更快思考、更高效能
模型思考快慢、推理效率高低已经成为模型最重要的评判标准之一,尤其是端侧应用时,更高的推理效能将极大提升用户的使用体验。其核心是在保证准确性的前提下,要让 AI 既能以最少的算力去解决每一个问题,又能在最短的时间内给出回应。
在 LiveCodeBench、AIME 等代码、数学推理的测试中,MiniCPM 4.1 推理速度比 Qwen3 8B 等同尺寸开源模型快 3 倍以上。
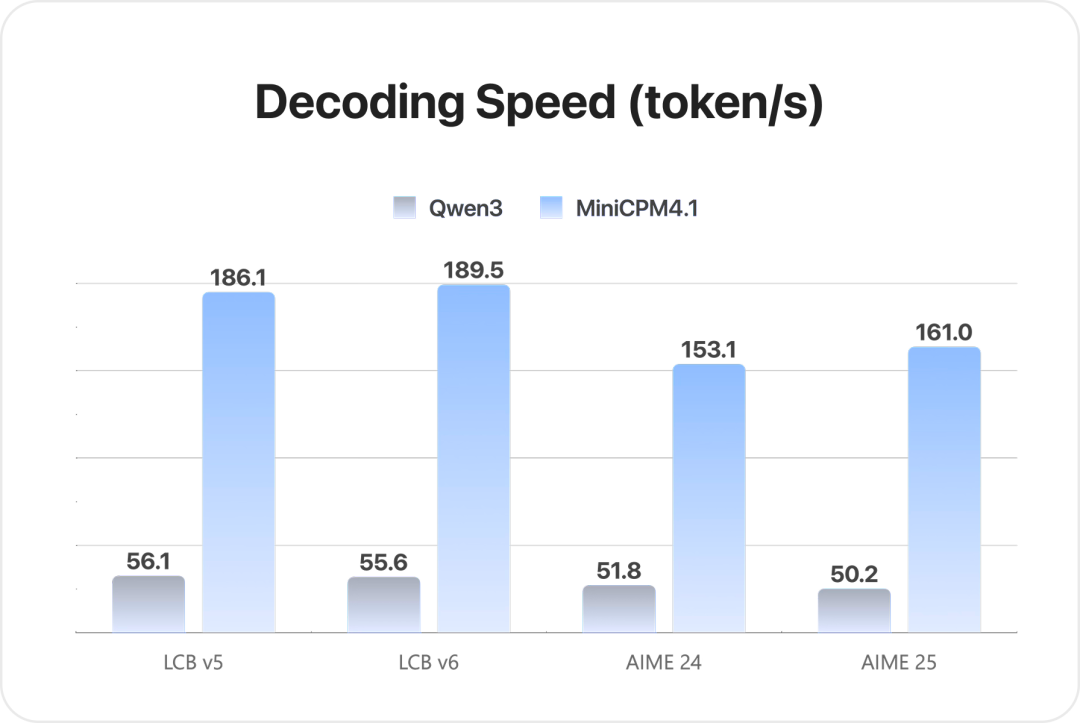
此外,MiniCPM 4.1 进一步实现了长文本缓存的大幅锐减,在 128K 长文本场景下,MiniCPM 4.1-8B 相较于 Qwen3-8B 仅需 25% 的缓存存储空间,让端侧算力不再有压力,成为业界目前最为友好的端侧模型。
针对单一架构难以兼顾长、短文本不同场景的技术难题,MiniCPM 4.1 采用「高效双频换挡」机制,能够根据任务特征自动切换注意力模式:在处理高难度的长文本、深度思考任务时,启用稀疏注意力以降低计算复杂度;在短文本场景下,切换至稠密注意力以确保精度与速度,实现了长、短文本切换的高效响应。
目前,MiniCPM 4.1 可在Ollama、vLLM、SGLang、llama.cpp、LlamaFactory、XTuner等开源框架部署。

首个基于原生稀疏注意力的深思考模型
深思考、长文本是模型发展的重要技术发力点,可以保证生成文本的连贯性和一致性,有助于提高模型的通用能力并拓展应用场景,尤其在端侧,需求更加强烈。因为终端上有海量的用户个人信息上下文,处理好这些上下文,才能真正做出最懂用户的个人助理产品。而这些个人信息的隐私性非常高,如聊天记录、位置信息等,模型运行在纯端侧,可以更好地保证个人信息安全。
由于传统稠密模型的上下文窗口受限,再加上传统 Transformer 模型的相关性计算方式(每个词元都需要和序列中所有词元进行相关性计算),长文本需要较高的内存和算力代价,导致过去长文本在端侧场景几乎不可用。
MiniCPM 4.1 通过高效的架构创新及自研的极速推理框架,确保了深思考、长文本在端侧上高效应用。
01 架构高效:新一代稀疏注意力架构 InfLLM 2.0
MiniCPM 4.1 采用了 InfLLM 2.0 稀疏注意力架构,摒弃了传统 Transformer 模型的相关性计算方式,改为分块分区域高效「抽查」——对文本进行分块分区域处理后,通过智能化选择机制,只需对最有相关性的重点区域进行注意力计算“抽查”,摆脱了逐字重复计算的低效。
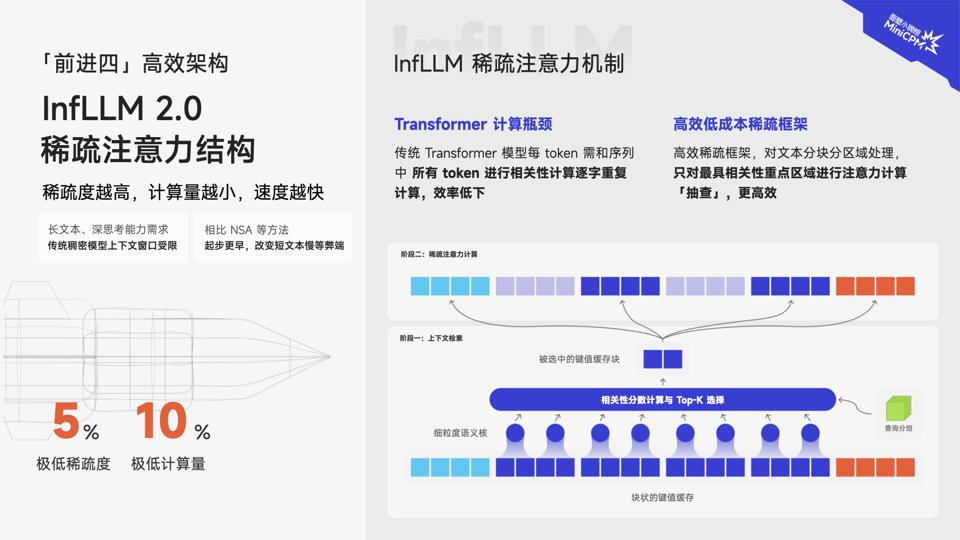
在 128k 长文本下,InfLLM 2.0 通过将稀疏度从行业普遍的 40%-50% 降至极致的 5%,注意力层仅需 1/10 的计算量即可完成长文本计算。且对算子底层重写,进一步加速提升,并使得对文本相关性、精准性大大提升。
02 推理高效:高性能推理框架 CPM.cu
CPM.cu 端侧自研推理框架,做到了稀疏、投机的高效组合。其中,FR-Spec 轻量投机采样类似于小模型给大模型当「实习生」,并给小模型进行词表减负、计算加速。通过创新的词表裁剪策略,让小模型专注于高频基础词汇的草稿生成,避免在低频高难度词汇上浪费算力,再由大模型进行验证和纠正。
本文由 Hugging Face 中文社区内容共建项目提供,稿件由社区成员投稿,经授权发布于 Hugging Face 公众号。文章内容不代表官方立场,文中介绍的产品和服务等均不构成投资建议。了解更多请关注公众号
https://hf.link/tougao
内容中包含的图片若涉及版权问题,请及时与我们联系删除
