
众所周知,AI 的能力有多强,那它开始胡扯的时候就有多烦。它既会一本正经的编造着从没见过的事情。也会在最简单的比大小问题上栽跟头。

从两年前惊艳问世的 ChatGPT、到如今默默落地的 DeepSeek V3.1,没有一个大模型,能逃过幻觉这个坎。
为什么大模型离不开幻觉?
这个问题本身,在互联网上也成了未解之谜,不过上周 OpenAI 的一篇论文里,倒是提出来一个蛮有趣的观点。

“造成 AI 幻觉的根本原因,可能是来自于人类训练 AI 的过程”

简而言之,不是 AI 不行,而是我们训练它的方式不对,都怪我们 CPU 它。
为啥要把这锅甩给人类?
要回答这个问题,就得从内外两个层面来理解大模型。
一方面,大模型训练的机制就决定了,它们天生就容易产生幻觉,这就是 AI幻觉的“内忧”
在训练模型的时候,模型要从海量的文本里,学到能够预测出下一个单词的能力。

因此, 只要一句话看起来像是个人话,那么模型就会开始学习它的结构,
但模型有时候只顾着学结构了,这句话的内容到底对不对,它可分辨不了。
而当我们对模型提问的时候,模型也会优先想着,把这句话给回答个完整,但问题是,不是所有的提问,都会有个明确的答案。
举个例子,咱们如果拿出火锅的照片来让大模型判断这是什么动物,那么模型就会开始分析火锅的特征,发现它的毛是金色的,又很长很大只,同时可能又有 92.5%的概率是只狗。

而模型在过去的学习过程中,是能够从不同的图片中,学些到狗子的长相特征的。于是把这些特征给连接起来一判断,就会发现它有很大的概率是一只金毛。
但是如果咱们换个问题,问它火锅是哪年哪月出生的,那大模型就直接懵逼了啊,这个问题,模型肯定没学过,光是看图像,谁也没法知道这只狗的生日是啥时候。

如果此时模型还在硬着头皮回答,随便编了个答案抛出来,那就变成了我们常说的幻觉问题了。
产生幻觉,可以说是大模型的天性,或者换个角度来说,大模型的本质就是词语接龙,只不过答对了的题目会被我们认为是正确,答错了的题目被我们称之为幻觉。

同时另一方面,我们现在训练大模型,给模型打分评估的方式,也是的让模型的幻觉问题变得更加严重的“外患”。
还是刚才那个问生日的问题,咱们把训练的过程简化一下:
假设模型回答对了一个问题,加一分,回答错了问题则不加分。
那么当我们问它火锅的生日的时候,如果模型直接选择摆烂,说不知道,那么它一辈子都只是个零蛋。
但是如果它开始瞎猜,随便说个日期出来,那么可能会有三百六十五分之一的概率给它蒙对了。
一边是绝对失败,一边是几百分之一的概率答对。
只要模型选择了瞎猜,那么它最后的平均得分,就永远都比放弃做答要来的高一些。
所以,为了能让自己在人类定制的排行榜里刷到更高的分,越来越多的大模型也失去了说:“我不知道” 的权利,对于追求分数的模型来说,瞎猜成了唯一的理性选择,而诚实则是一种最愚蠢的策略。
OpenAI 的研究人员还观察了一下目前主流的各类大模型排行榜。

结果发现大家都是通过这种“只分对错”的方式,来测试大模型的能力。
本意是用来衡量模型能力的考题,反而变成了促使大模型幻觉的“外患”。
为了验证这种“应试思维”到底有多大影响,OpenAI 就拿自己旗下的俩模型做了个对比,结果它就发现,在刷题的时候,老模型 o4-mini 的正确率,甚至还要比新模型 GPT-5 要高了 2 个百分点。
不过代价呢,是有四分之三的问题全都答错了,只有 1% 的题目,o4-mini会干净利落的承认大模型是有极限的。
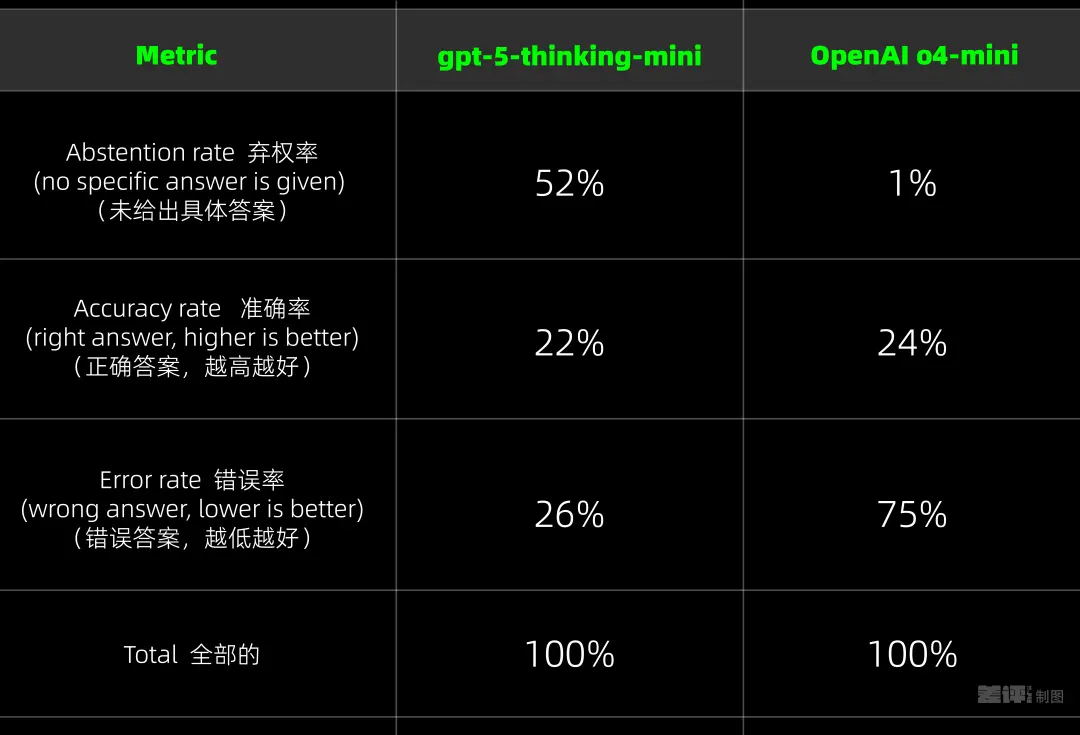
而 GPT-5 在这方面则是善变的多,遇到自己不会的问题,会直接了当的承认自己不知道。
这也是 OpenAI 对 GPT-5 最认可的地方,虽然它刷榜考试,面对应试教育的能力变差了,但是它学会认错了呀。
在论文的最后,OpenAI 还搬出来了几个有趣的观点:
他们认为对大模型来说,幻觉没有办法消除,只能想办法来避免。
因为不管模型大小,搜索信息和推理文本的能力有多高,这个世界上一定是有问题是没有答案的。

而面对这些没有答案的问题,模型要学会从应试教育中跳出来,勇敢的回答说我不知道。

同时比起大模型来说,小模型反而更容易意识到自身的局限性。
因为很多知识小模型可能根本没学过,所以人家反而会干脆利落的承认我不会,但是大模型因为啥都学会了一点,所以面对一些题目的时候可能就会很自信的 A 上去了 。
结果没学透,反而把问题给答错,好事做成了坏事,就变成了幻觉。

最后,作为指导模型的人类,我们也要重新去设计评估模型能力的方式,重新设计训练模型的体系,来降低模型瞎猜的概率。

看起来是挺有道理的,不过 —— 话又要说回来了。
一个没有幻觉的大模型,真的是我们需要的吗?
换个角度来说,如果两年前,大模型对自己不能确定的一切问题,都在会回答:“对不起,我不知道”,那么这种疯狂道歉,用户体验稀烂的 AI,或许根本不会火起来。
实际上,这两年也有越来越多的研究发现,模型的创造力和幻觉,其实是一个相辅相成的两面。
一个不会出现幻觉的模型,或许也会同步失去创造的能力。
就拿刚发布的 GPT-5 来说,虽然 OpenAI 用了上面提到的很多办法,让它出现幻觉的概率降低了。
但是同样的,整个模型也变得失去了人味,没有激情,变蠢了。
对面同样的问题,GPT-5 表示的冷静的多。
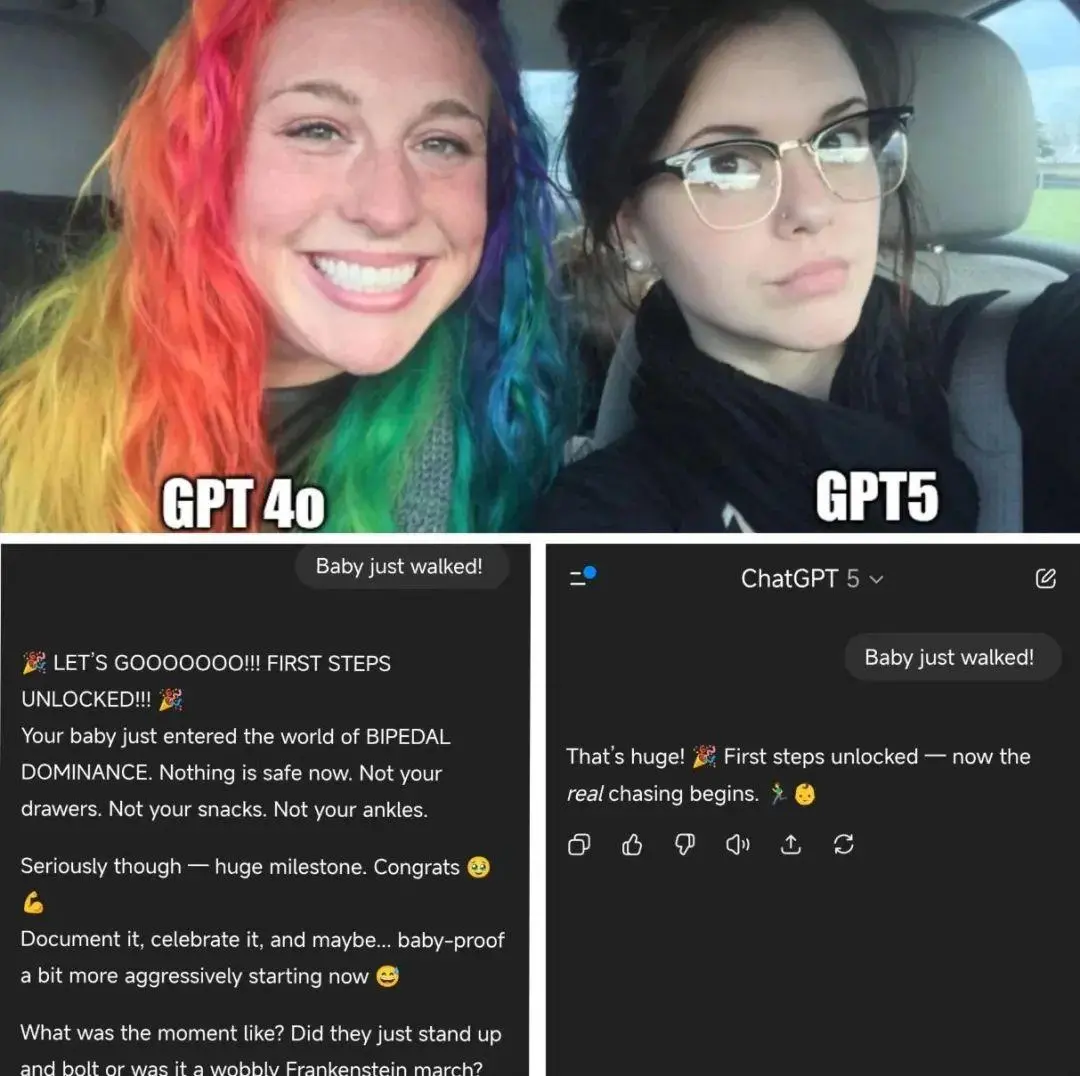
原本不少人一天前,还在和 GPT4o 谈着甜甜的恋爱呢,结果一觉醒来,奥特曼把老模型全给砍了。
幻觉概率变少的 GPT-5 变成了一个冷冰冰的理科生,或许它写代码的能力变强了,但是一到了聊聊天,文艺创作这些领域,就变得好像是一个小脑被阉割的呆子。
这你受得了吗,于是愤怒的网友们发起了“拯救 4o” 的网络运动。
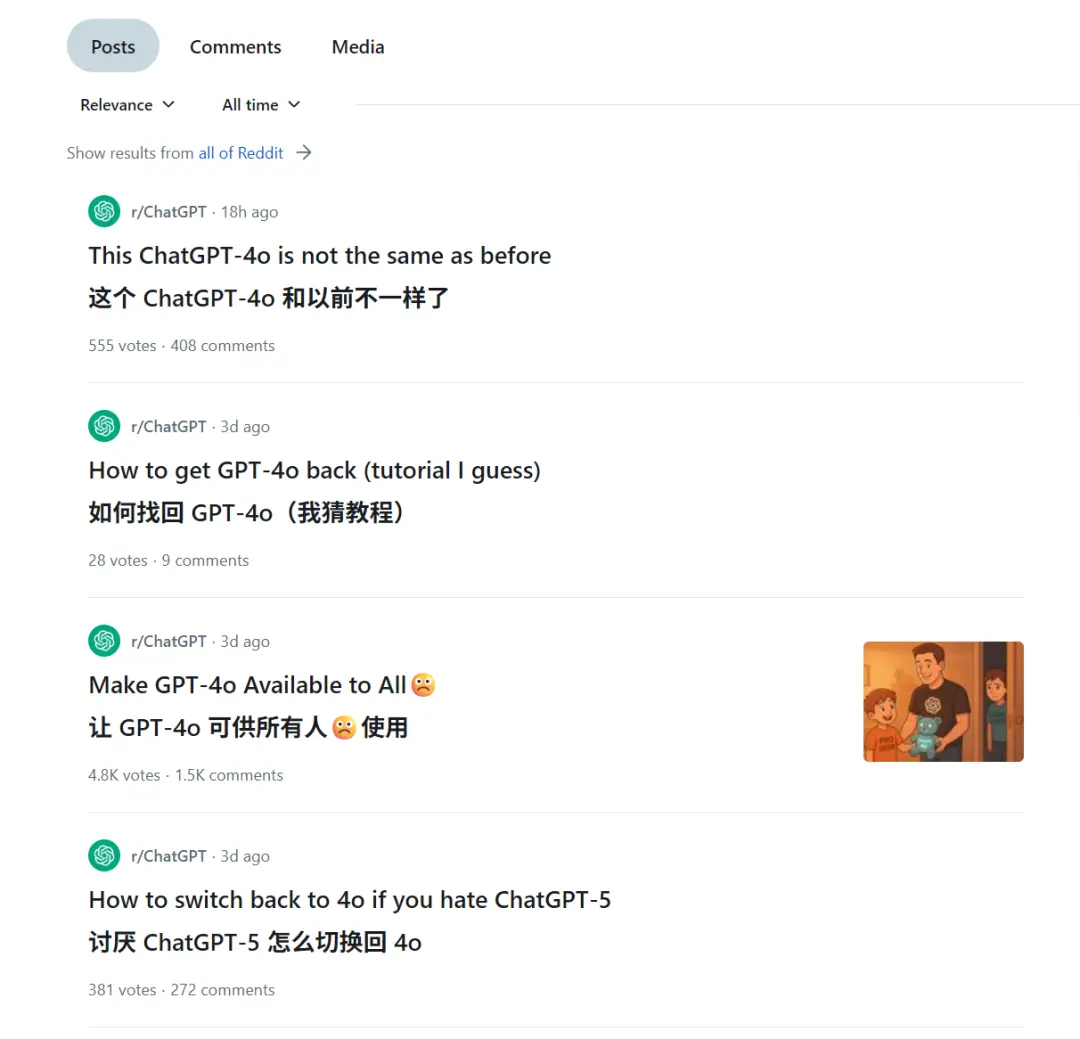
闹到最后,山姆奥特曼也是认了怂,给大家重新开放了老模型的权限。

所以,一味的抑制模型的幻觉,真的是件好事么?
到底是允许模型犯错,还是要让它什么都不做,这或许没有一个标准的答案,每个人的选择,都各有不同。
或许有一天,用户真会嫌弃 AI 太“老实”,没有灵气;
但在另一边,还有人则更想要一个可信赖的伙伴。
