

思路动机
LLM最新进展为推荐系统任务提供了有前途的新方法。当前最先进的方法依赖于微调 LLM 来实现最佳结果,但此过程成本高昂且带来了显著的工程复杂性。相反,绕过微调并直接使用 LLM 的方法资源密集程度较低,但往往无法完全捕获语义和协作信息,导致与经过微调的方法相比性能不佳。在本文中,提出了一种简单的无需训练的推荐方法 (STAR),这是一个利用 LLM 的框架,可应用于各种推荐任务而无需微调。
comment: 这篇论文,提供了一个将语义与协同信息融合起来的视角,这是这篇论文提供的最大的启发性视角。
- 提供了一种普适推荐场景下,快速搞一个基于llm推荐的基线。在此基础上,特定业务场景,还是需要针对性改进。 模型还是需要微调的,不能应该微调成本高、工程复杂就放弃。
在LLM里面,考虑user-item interactions交互行为,真的非常非常重要!实验观察到的现象:
- Beauty Hits@10: +23.8% Toys and Games:+37.5% Sports and Outdoors :-1.8%
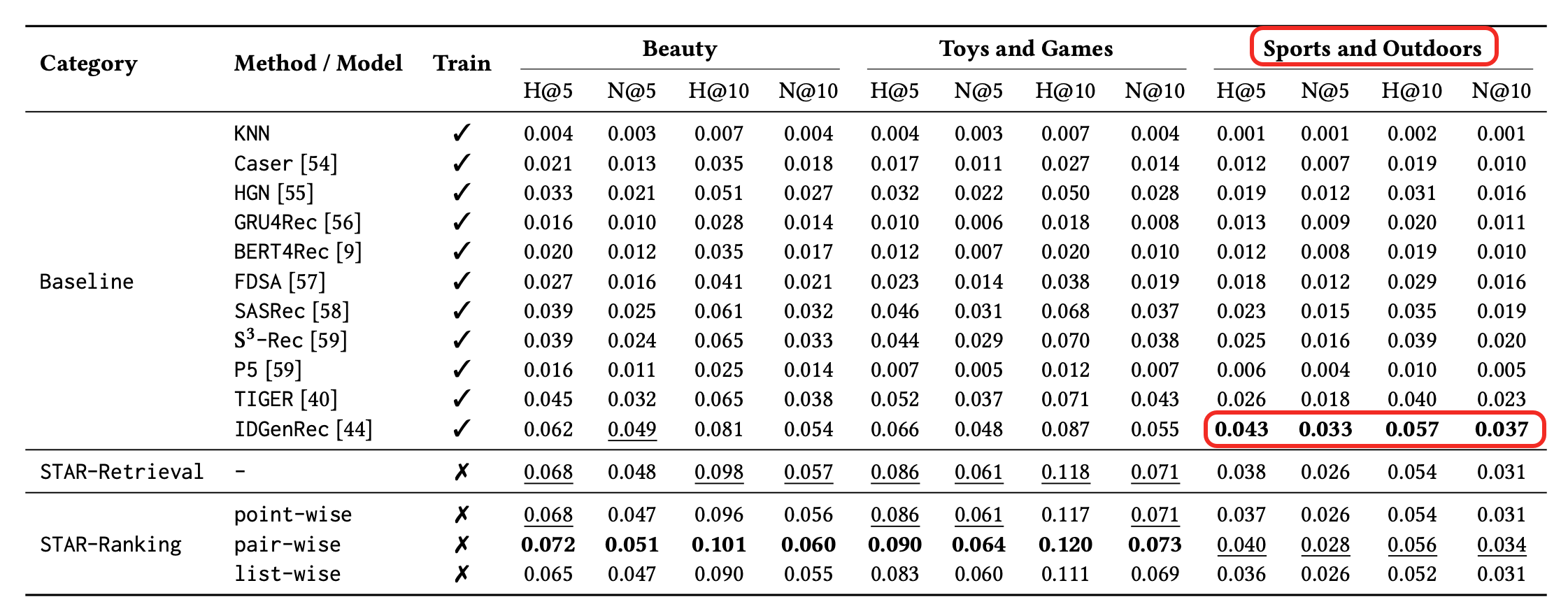
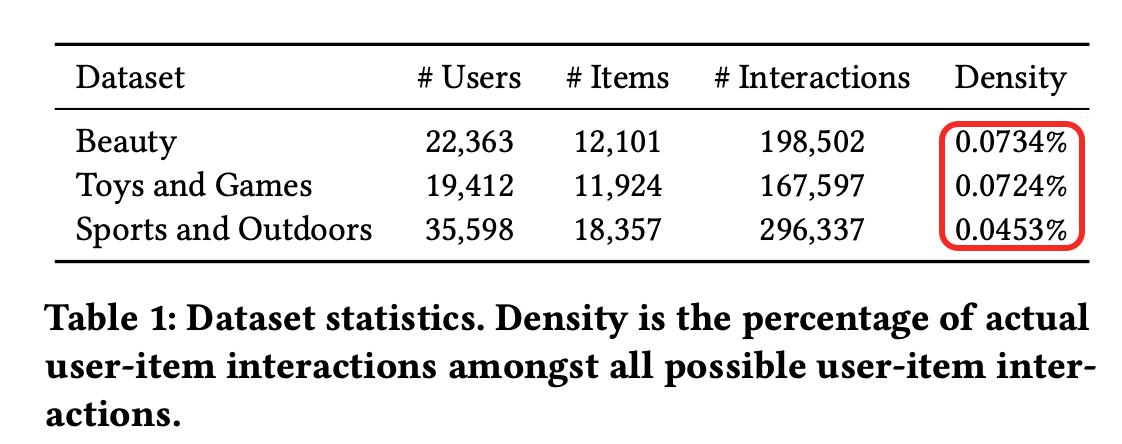
Sports and Outdoors 为啥结果提不上来?因为Sports and Outdoors上用户与item的交互,相比其他两个数据集,是很低的。
方法
两阶段方法,方法全局概览:
- 检索
 通过上图得到检索结果。
通过上图得到检索结果。
- 排序
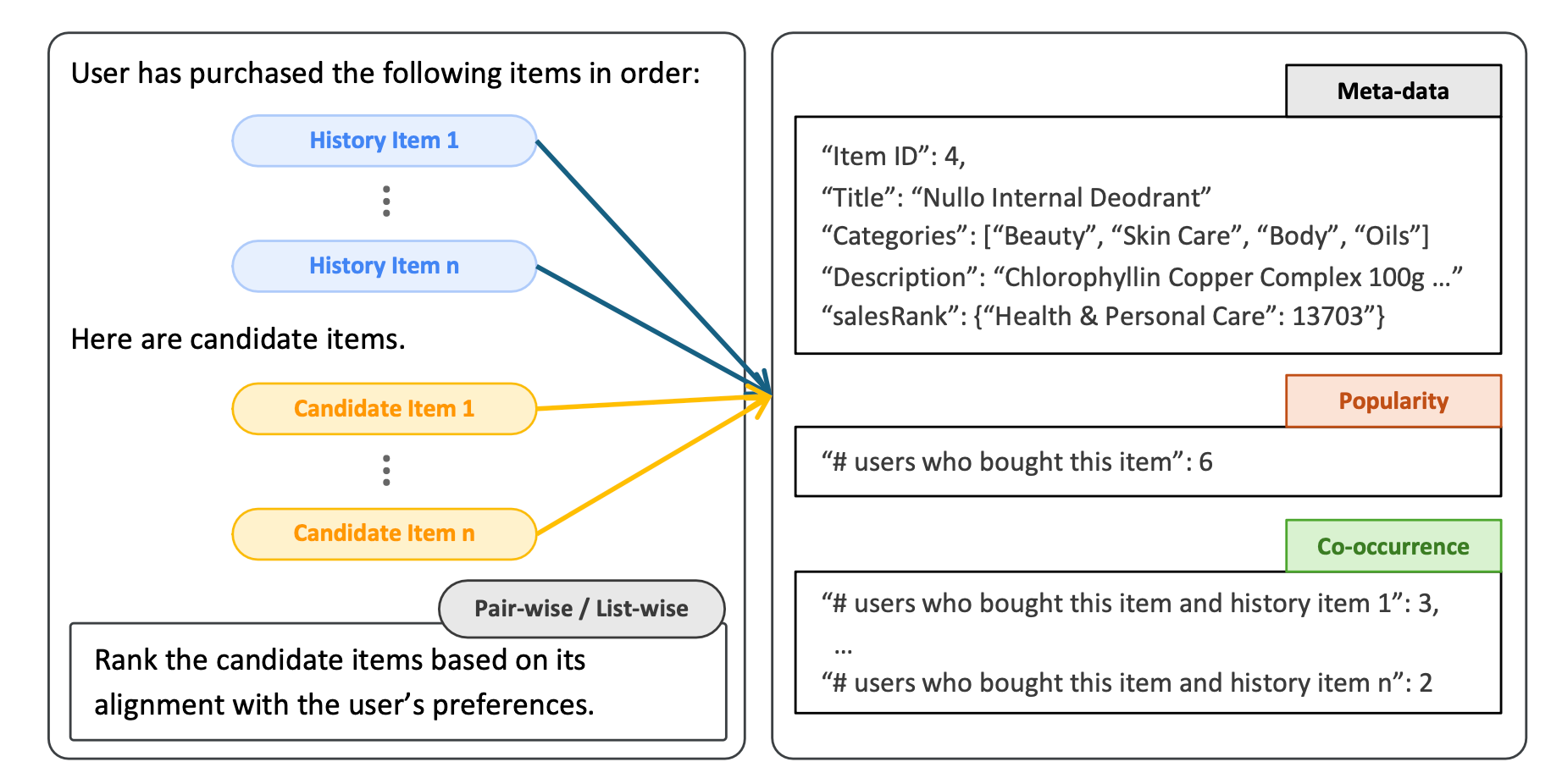 对检索结果,通过LLMRank排序。
对检索结果,通过LLMRank排序。
检索
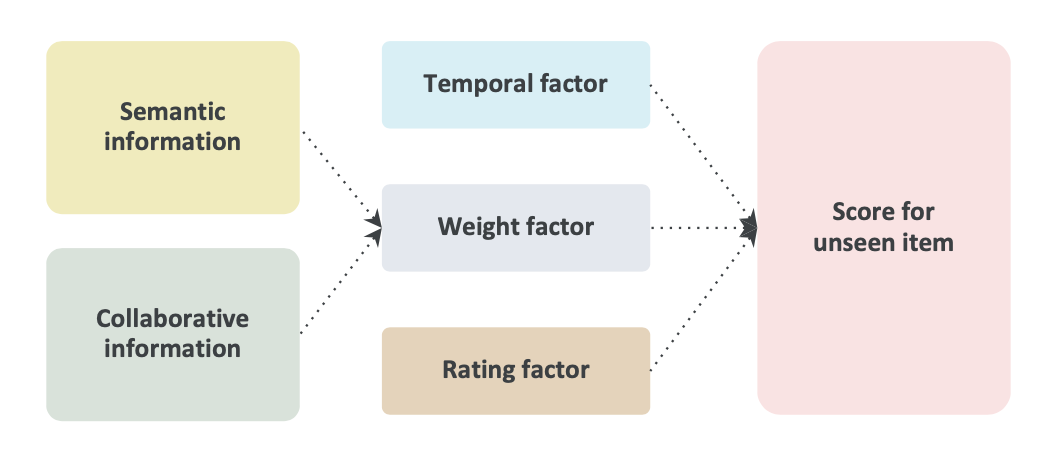
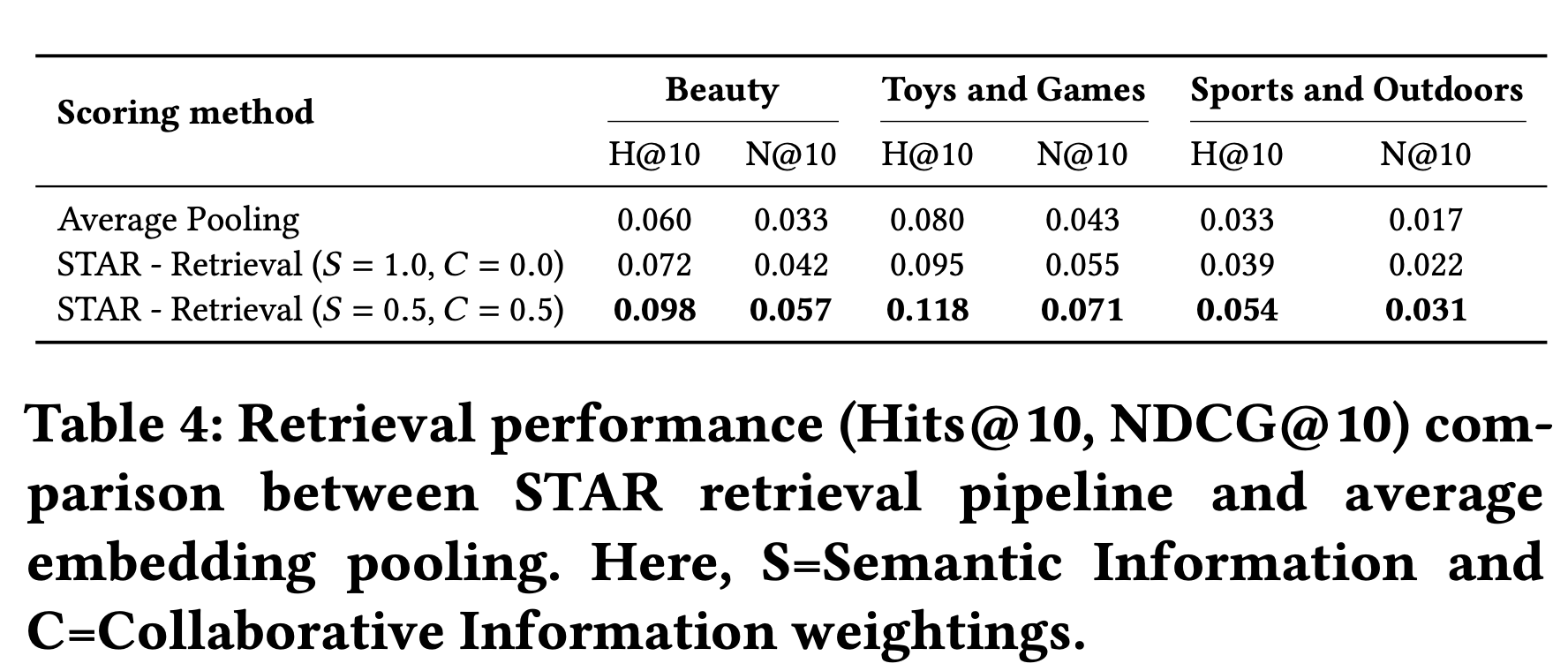
检索阶段,考虑了语义信息、和CI信息。在融合这两者的时候(融合公式里),语义信息和CI信息,有一个权重平衡因子。
同时会考虑:
- 时间因子:用户与item交互时间越近的,越重要; 打分因子:用户与item交互打分,越大越重要;
怎么计算语义信息矩阵、CI信息矩阵?
预先计算好语义信息矩阵(nn,n是item的数量)、以及CI信息矩阵(nn,怎么计算,用的非常典型的itemCF计算item之间的相似度矩阵)

- llm embedding: 使用的是google自己内部的Geckotext-embedding-004

怎么融合?
如果不考虑语义信息,则对item4的打分,就是一个非常典型的itemCF对item4的打分逻辑:
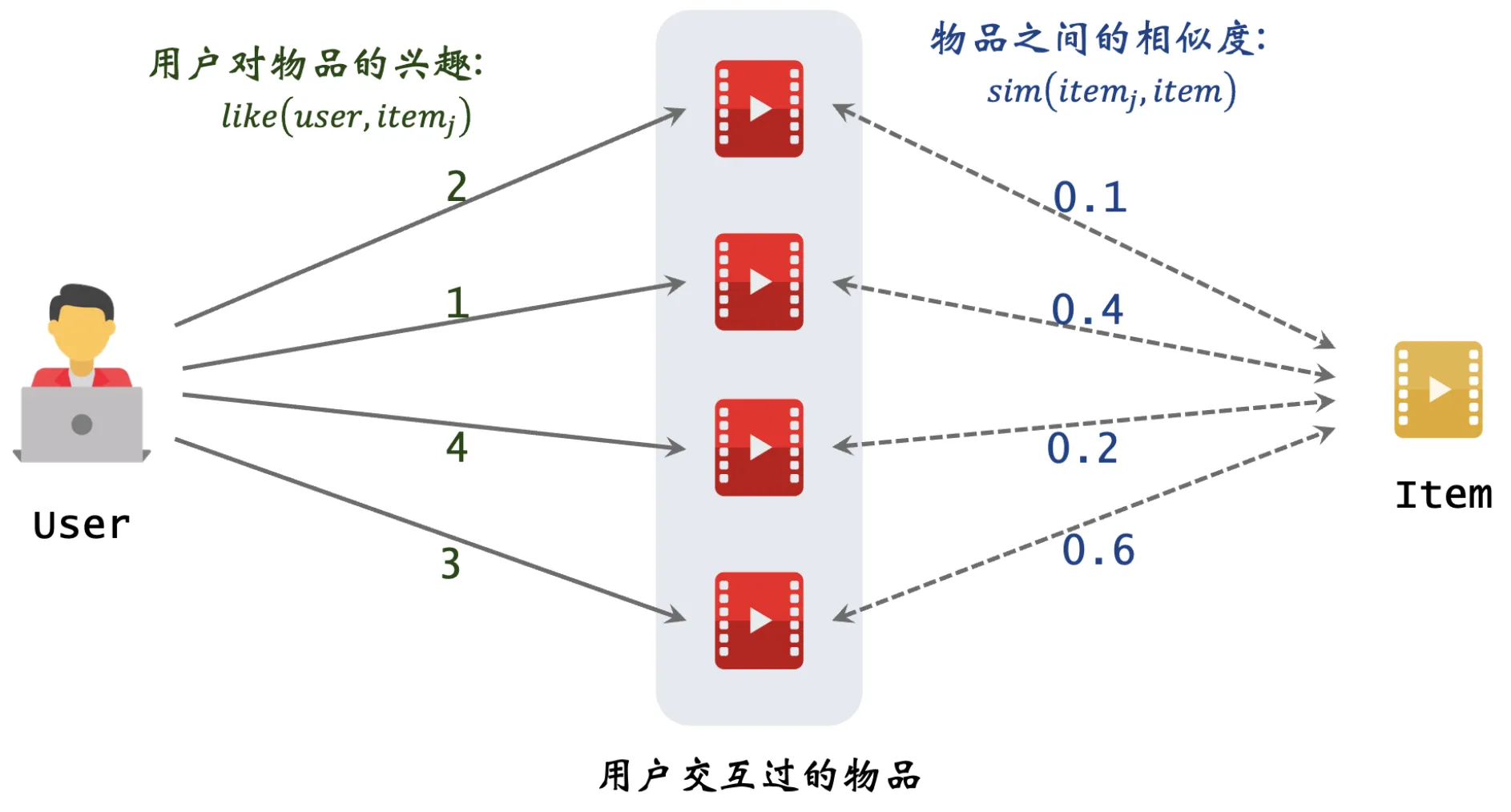 需要融合语义信息矩阵,是在itemCF打分的基础上,做了如下方式的融合:a=0,就是itemCF打分逻辑,只是里面包含了时间因子t、打分因子r:
需要融合语义信息矩阵,是在itemCF打分的基础上,做了如下方式的融合:a=0,就是itemCF打分逻辑,只是里面包含了时间因子t、打分因子r:
 打分因子r_j: user对item_j的打分,实验发觉r_j全部取1,对结果没什么影响。
打分因子r_j: user对item_j的打分,实验发觉r_j全部取1,对结果没什么影响。
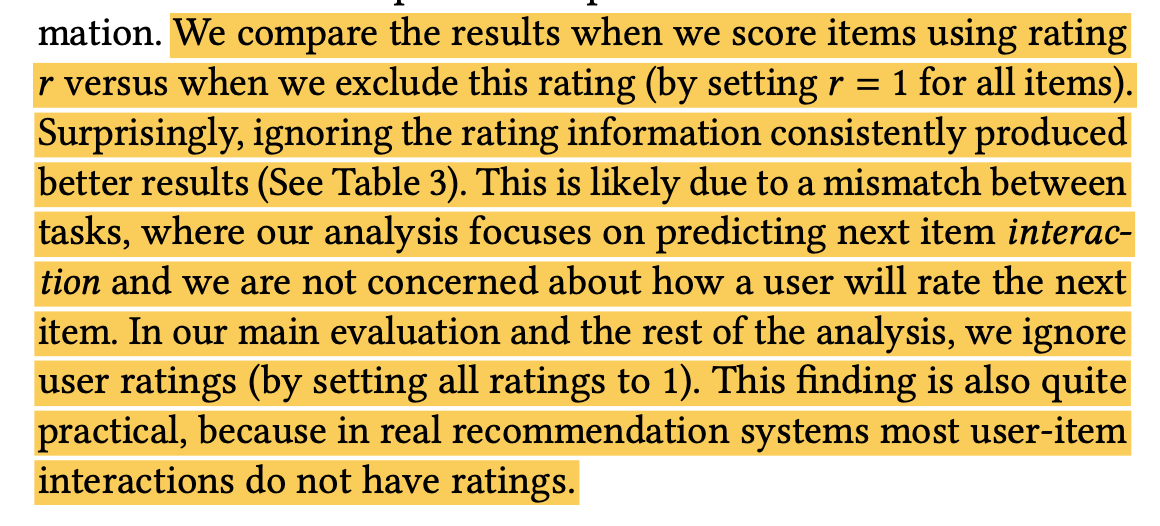
a=0和a=1,有消融实验结论,没有贴具体数据。

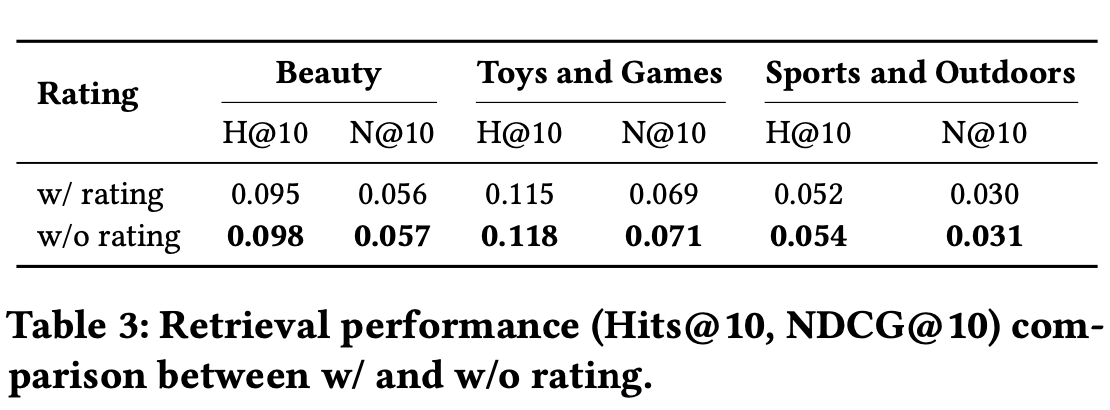
检索打分公式的影响:
排序
输入:
![]()
排序打分逻辑,不同打分方式结果:
![]()
候选长度、交互序列的长度,对结果的影响:
![]() rank里面加入一些交互行为的影响:
rank里面加入一些交互行为的影响:
![]()
感觉差异不大。
不同模型对结果的影响:
![]()
