

In this interview series, we’re meeting some of the AAAI/SIGAI Doctoral Consortium participants to find out more about their research. Yezi Liu is working on trustworthy and efficient machine learning. We asked her about her research to date, what she has found particularly interesting, plans for future work, and what is was that inspired her to study AI.
Tell us a bit about your PhD – where are you studying, and what is the topic of your research?
I’m currently pursuing my Ph.D. in Computer Engineering at the University of California, Irvine. My research focuses on trustworthy machine learning, with particular emphasis on graph neural networks as well as trustworthy and efficient large language models.
Could you give us an overview of the research you’ve carried out so far during your PhD?
So far, my Ph.D. research has focused on making machine learning more trustworthy and efficient. On the graph learning side, I have worked on fairness, privacy-preserving unlearning, and interpretability for dynamic graph neural networks. More recently, I’ve also started to look at efficiency and trustworthiness challenges in large language models, as these have become increasingly important in real-world applications.
Is there an aspect of your research that has been particularly interesting?
One project I found particularly interesting was studying fairness in text-to-image models. I noticed that the generated images often reflected cultural stereotypes, which was both surprising and thought-provoking, and it made the research process very engaging. On the technical side, I really enjoyed working on unlearning for large language models, where I used negative samples to fine-tune the model in a way that forces it to ‘forget’ certain knowledge. I found this approach both clever and effective, which made the work especially rewarding.
 An illustration of the unlearning task: before unlearning, the model recalls factual knowledge, while after unlearning, it ‘forgets’ the targeted information.
An illustration of the unlearning task: before unlearning, the model recalls factual knowledge, while after unlearning, it ‘forgets’ the targeted information.
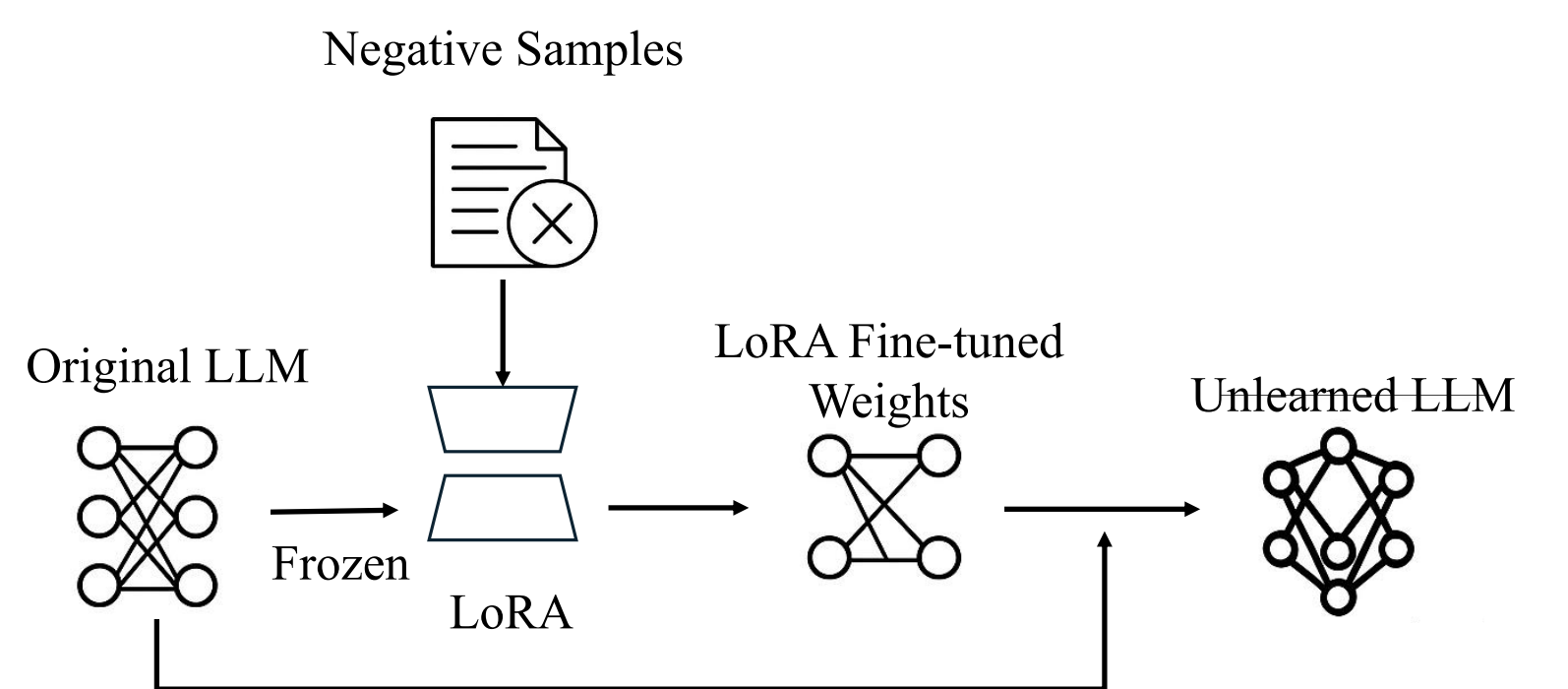 Overview of the LUNE framework: the model uses negative examples and lightweight adapters to efficiently unlearn specific information.
Overview of the LUNE framework: the model uses negative examples and lightweight adapters to efficiently unlearn specific information.
What are your plans for building on your research so far during the PhD – what aspects will you be investigating next?
Looking ahead, I plan to focus more on the efficiency of large language models, especially in reasoning. Since reasoning is such a core capability of these models, finding ways to make it faster and still generate high-quality answers and retrieve useful information is very important. I hope to contribute meaningful research in this area during the next stage of my Ph.D.
How was the AAAI Doctoral Consortium, and the AAAI conference experience in general?
My experience at the AAAI Doctoral Consortium and the conference overall was excellent. What I appreciated most was the way the consortium connected us with assistant professors as mentors. For me, it can sometimes feel a bit difficult to approach professors directly, but the structure of the program, like sitting together at a table or even sharing a meal, made those interactions very natural and comfortable. This design was incredibly helpful for building meaningful connections with both faculty and other Ph.D. students, and it made the whole experience truly valuable.
What made you want to study AI?
I’ve always enjoyed digging deeply into things I find interesting, and AI naturally caught my attention because it’s becoming such a big part of everyday life. It’s hard not to wonder why these systems work the way they do and how they could be improved. Doing a Ph.D. has given me the opportunity to explore these questions more systematically, but at the core, it really comes down to curiosity and passion, those are what drive me to keep pushing forward.
What advice would you give to someone thinking of doing a PhD in the field?
My advice would be: find something you’re really interested in, and just get it done. A Ph.D. is a long journey, and without genuine interest, it’s hard to stay motivated. If you don’t persist, it’s difficult to build a sense of accomplishment, and that can really affect your daily mindset. But when you work on something that excites you, that motivation keeps you going.
Could you tell us an interesting (non-AI related) fact about you?
Outside of research, I really enjoy things that are complex but logical, because I like having something that makes me think. For example, I love reading detective novels, watching strategy-based shows, or playing mystery and puzzle games. Even in music, I’m drawn to songs with intricate but clever arrangements, the kind that make you appreciate the thought behind them.
About Yezi Liu
 | Yezi Liu is a Ph.D. candidate in Computer Science at the University of California, Irvine. Her research focuses on trustworthy and efficient machine learning, spanning fairness, privacy, interpretability, and scalability in both graph neural networks and large language models. She has developed methods for fairness, privacy-preserving learning, dynamic GNN explainability, and graph condensation, with work published at venues such as IJCAI, WWW, CIKM, and ACM MM. More recently, she has been exploring efficiency and trustworthiness in large language models. Her overarching goal is to build AI systems that are accurate, reliable, and socially responsible. |
