
Build MCP servers that perform with Gram by Speakeasy (Sponsored)

AI agents get confused by MCP servers which include too many tools, lack crucial context, and are simple API mirrors. Without development, your carefully designed APIs causes agent headaches.
Gram fixes this. It's an open source platform where you can curate tools: add context, design multi-step tools, and deploy your MCP server in minutes.
Transform your APIs into agent-ready infrastructure that is ready to scale with OAuth 2.1 support, centralized management, and hosted infrastructure.
Disclaimer: The details in this post have been derived from the official documentation shared online by the Netflix Engineering Team. All credit for the technical details goes to the Netflix Engineering Team. The links to the original articles and sources are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
When Netflix launched Tudum as its official home for behind-the-scenes stories, fan interviews, and interactive experiences, the engineering challenge was clear: deliver fresh, richly formatted content to millions of viewers at high speed, while giving editors a seamless way to preview updates in real time.
The initial architecture followed a classic CQRS (Command Query Responsibility Segregation) pattern, separating the “write path” for editorial tools from the “read path” for visitors. Kafka connected these paths, pushing read-optimized data into backend services for page construction.
The approach was scalable and reliable, but not without trade-offs.
As Tudum grew, editors noticed a frustrating delay between saving an update and seeing it live in previews. The culprit was a chain of sequential processes and cache refresh cycles that, while suitable for production visitors, slowed down the creative workflow.
To solve this, Netflix engineers replaced the read-path’s external key-value store and per-request I/O with RAW Hollow: a compressed, distributed, in-memory object store embedded directly in the application.
The result was near-instant editorial preview, simpler infrastructure, and a major drop in page construction time for end users. In this article, we will look at the evolution of this design decision and how Netflix went about implementing it.
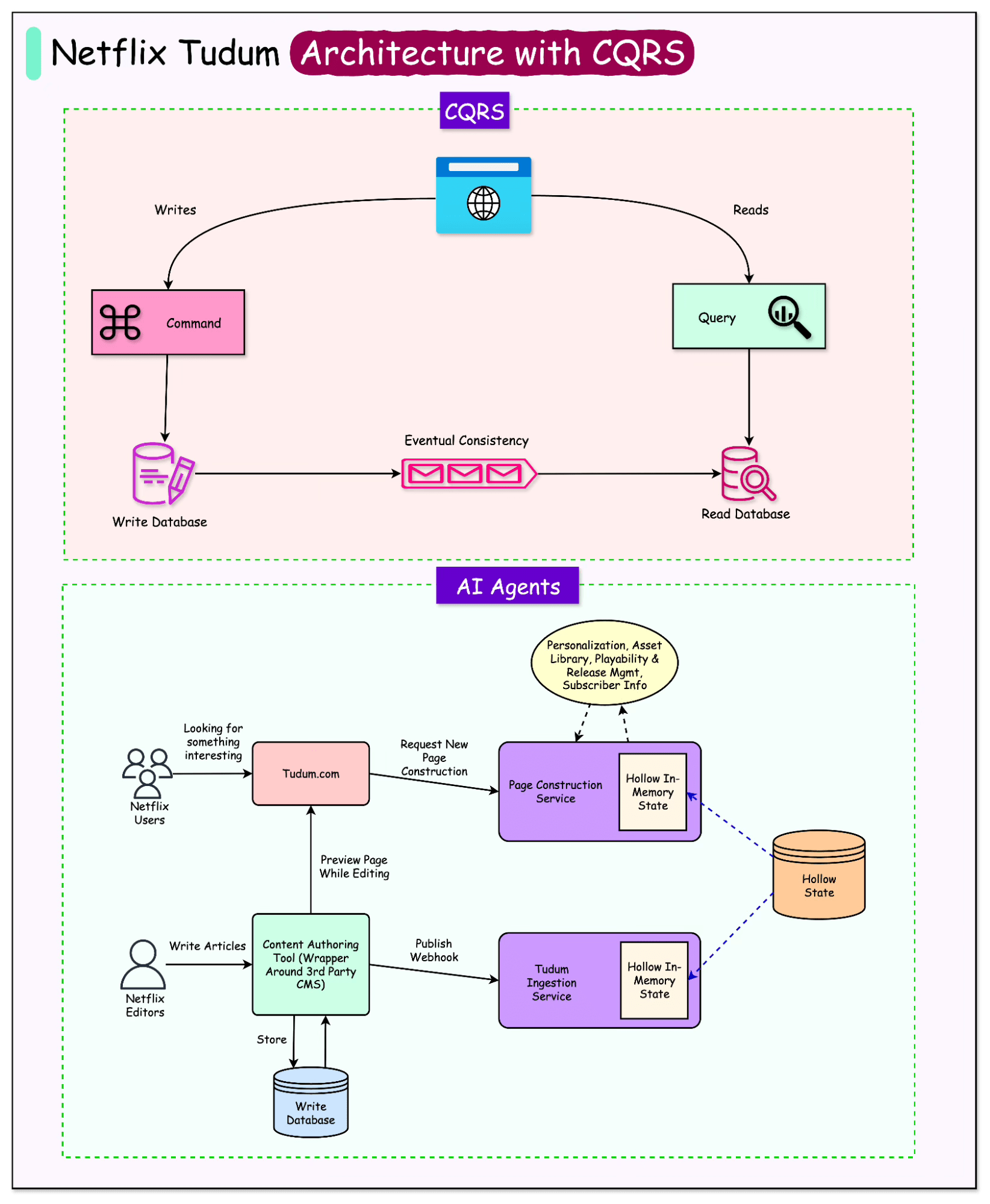
Early Design
Netflix’s Tudum platform had to support two fundamentally different workflows:
Write path: This is where content editors create and update rich, media-heavy stories in a content management system (CMS).
Read path: This is where millions of global visitors consume those stories in a format optimized for fast rendering and delivery.
To keep these workflows independent and allow each to scale according to its needs, Netflix adopted a CQRS (Command Query Responsibility Segregation) architecture.
See the diagram below for a general overview of CQRS.
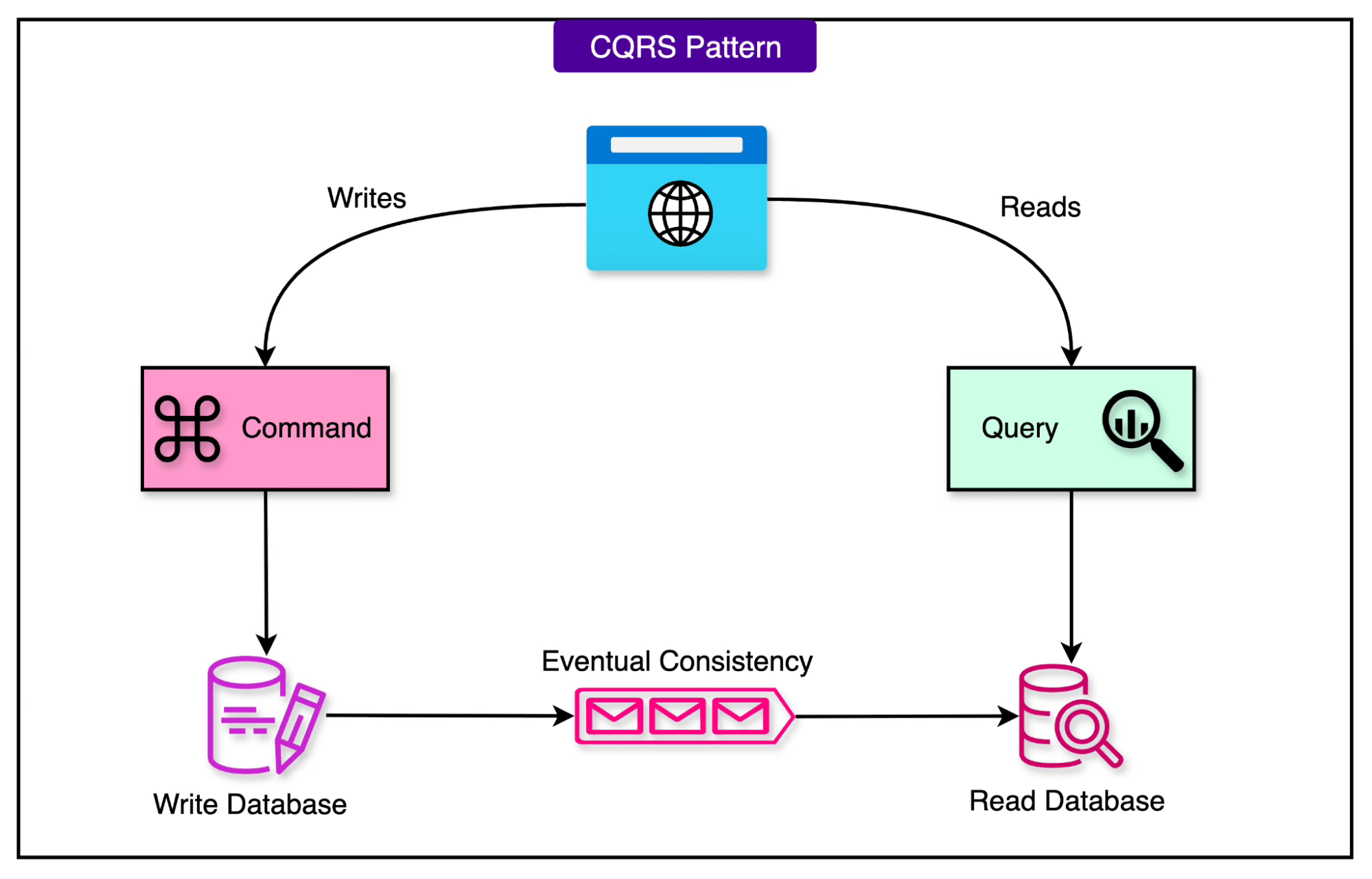
The write store contains the raw editorial data (internal CMS objects with IDs, metadata, and references), while the read store contains a fully “render-ready” version of the same data, such as resolved movie titles instead of IDs, CDN-ready image URLs instead of internal asset references, and precomputed layout elements.
As mentioned, Kafka served as the bridge between the two paths. When an editor made a change, the CMS emitted an event to Tudum’s ingestion layer. This ingestion pipeline performed the following steps:
Pulled the content from the CMS.
Applied templates and business rules to ensure formatting consistency.
Validated the data for required fields and constraints.
Transformed placeholders into production-ready assets (for example, movie title lookups, CDN URL resolution).
The processed content was published to a Kafka topic.
A Data Service Consumer subscribed to this topic, reading each new or updated page element. It wrote this data into a Cassandra-backed read store, structured for fast retrieval. Finally, an API layer exposed these read-optimized entities to downstream consumers such as the Page Construction Service (which assembles full pages for rendering), personalization services, and other internal tools.
See the diagram below:
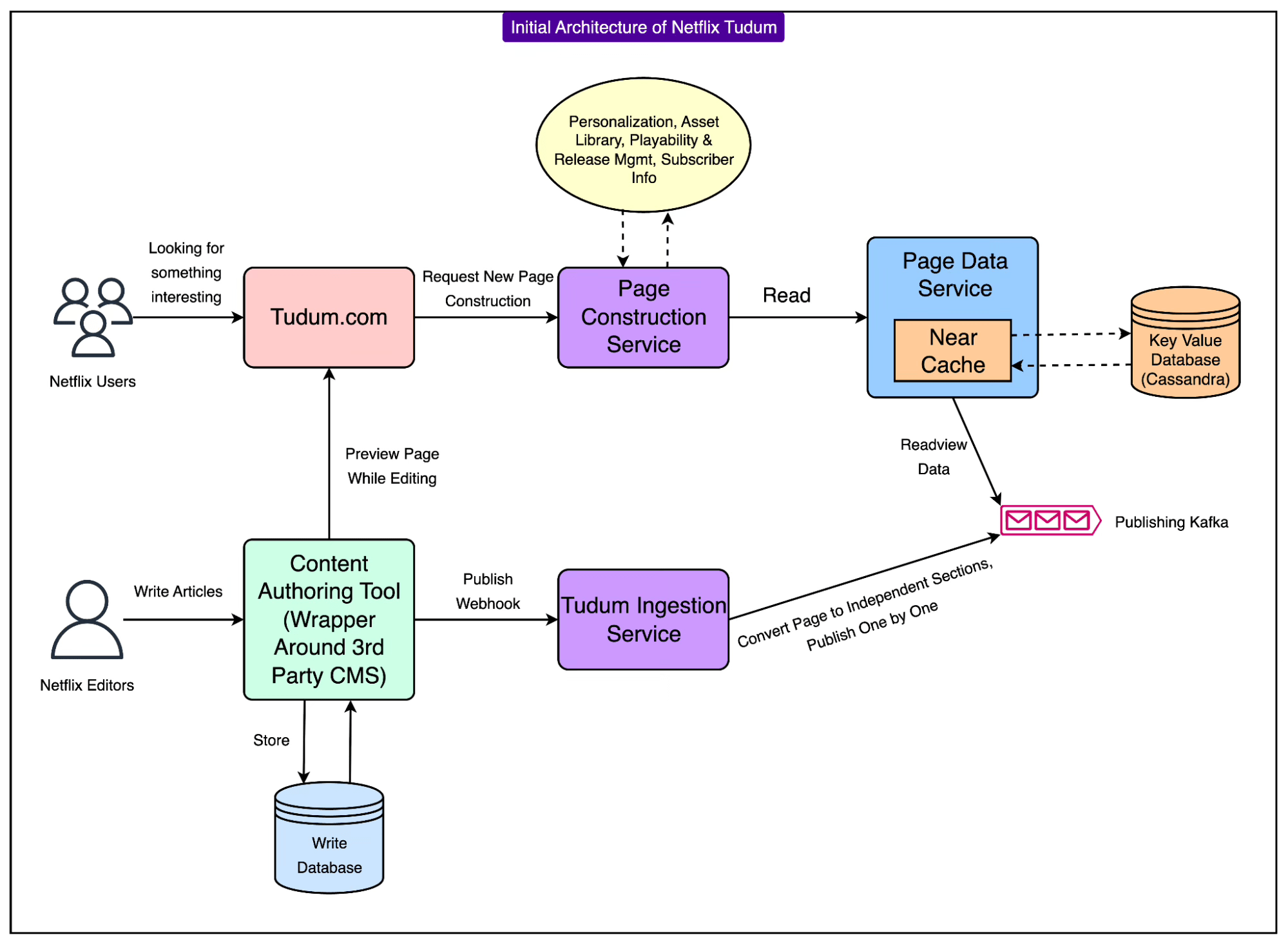
This event-driven design ensured that editorial changes would eventually appear on the Tudum website without impacting write-side performance, while also allowing Netflix to scale the read and write paths independently.
The Pain of Eventual Consistency
While the CQRS-with-Kafka design was robust and scalable, it introduced a workflow bottleneck that became increasingly visible as Tudum’s editorial output grew.
Every time an editor made a change in the CMS, that change had to travel through a long chain before it appeared in a preview environment or on the live site. Here is a quick look at the various steps involved:
Save in CMS: The updated content is stored in the write database.
Webhook to Tudum ingestion: The CMS notifies Tudum’s ingestion layer of the change.
Re-read and process: Ingestion fetches the relevant sections, applies templates, validates data, and performs asset resolution.
Publish to Kafka: The processed content is sent to the designated Kafka topic.
Consume and store: The Data Service Consumer ingests the message, writes it into Cassandra as a read-optimized record.
Cache refresh: The Page Data Service, sitting in front of Cassandra, maintains a near-cache that must refresh for the new content to be visible.
This near-cache was a key contributor to the delay. Technically speaking, the near-cache is a small, per-instance, memory layer that sits in front of the read store. However, rather than refreshing instantly for every update, it operated on a scheduled per-key refresh policy. Each key has a timer. When the timer fires, the instance refreshes that key from the backing store. While this approach was designed for production traffic efficiency, it meant that fresh edits often waited for the next scheduled refresh cycle before appearing.
As content volume and the number of page elements increased, these refresh cycles stretched longer. A page is assembled from multiple fragments, each with its key and timer. They do not refresh together. This meant that the more elements a page had, the more staggered the refresh completion became, leading to inconsistent preview states. In other words, some elements got updated, but others remained stale.
The result was that editors had to sometimes wait minutes to see their changes reflected in a preview, even though the system had already processed and stored the update.
For a platform like Tudum, where timing is critical for publishing stories tied to new releases and events, this delay disrupted editorial flow and complicated collaboration between writers, editors, and designers.
The Solution: RAW Hollow
To eliminate the bottlenecks in Tudum’s read path, Netflix engineers turned to RAW Hollow: a compressed, distributed, in-memory object store designed for scenarios where datasets are small-to-medium in size, change infrequently, and must be served with extremely low latency.
Unlike the earlier setup, where read services fetched data from an external Cassandra-backed key-value store (with network calls, cache layers, and refresh cycles), RAW Hollow keeps the entire dataset loaded directly into the memory of every application instance that needs it. This means all lookups happen in-process, avoiding the I/O and cache-invalidation complexities of the old approach.
The key characteristics of RAW Hollow in the Tudum context are as follows:
Distributed and co-located: Each service instance holds the full dataset in memory. Updates are propagated so all instances stay synchronized without having to query an external store on demand.
Compression for scalability: Data is stored in a compressed binary form, significantly reducing RAM usage. In Tudum’s case, three years of unhydrated data fit into ~130 MB, which is about one-quarter the size of the same data in Apache Iceberg.
Consistency control per request: By default, RAW Hollow favors eventual consistency for high availability, but services can opt in to strong read-after-write consistency on a per-request basis. This is especially useful for editor preview flows, ensuring that a just-published update is immediately visible without waiting for the standard sync interval.
Built for in-memory computation: Because the dataset is always in RAM, services like page construction, search, and personalization can retrieve data in O(1) time, eliminating network round-trip.
For Tudum, adopting RAW Hollow meant removing the Page Data Service, its near-cache, the external key-value store, and even Kafka from the read path. Instead, the Hollow client was embedded directly inside each microservice that needed content. This collapsed the number of sequential operations, tightened the feedback loop for editors, and simplified the architecture by removing multiple moving parts.
The result was a big shift: instead of “store to fetch to cache to refresh,” the system now operates on “load once into memory to serve instantly to propagate changes.”
The New TUDUM Design
After adopting RAW Hollow, Netflix rebuilt Tudum’s read path to remove the layers that were slowing down editorial previews and adding unnecessary complexity.
The new design still follows the CQRS principle (separating the editorial content creation from the visitor-facing content), but the way data moves through the read side is now radically simplified.
See the diagram below:
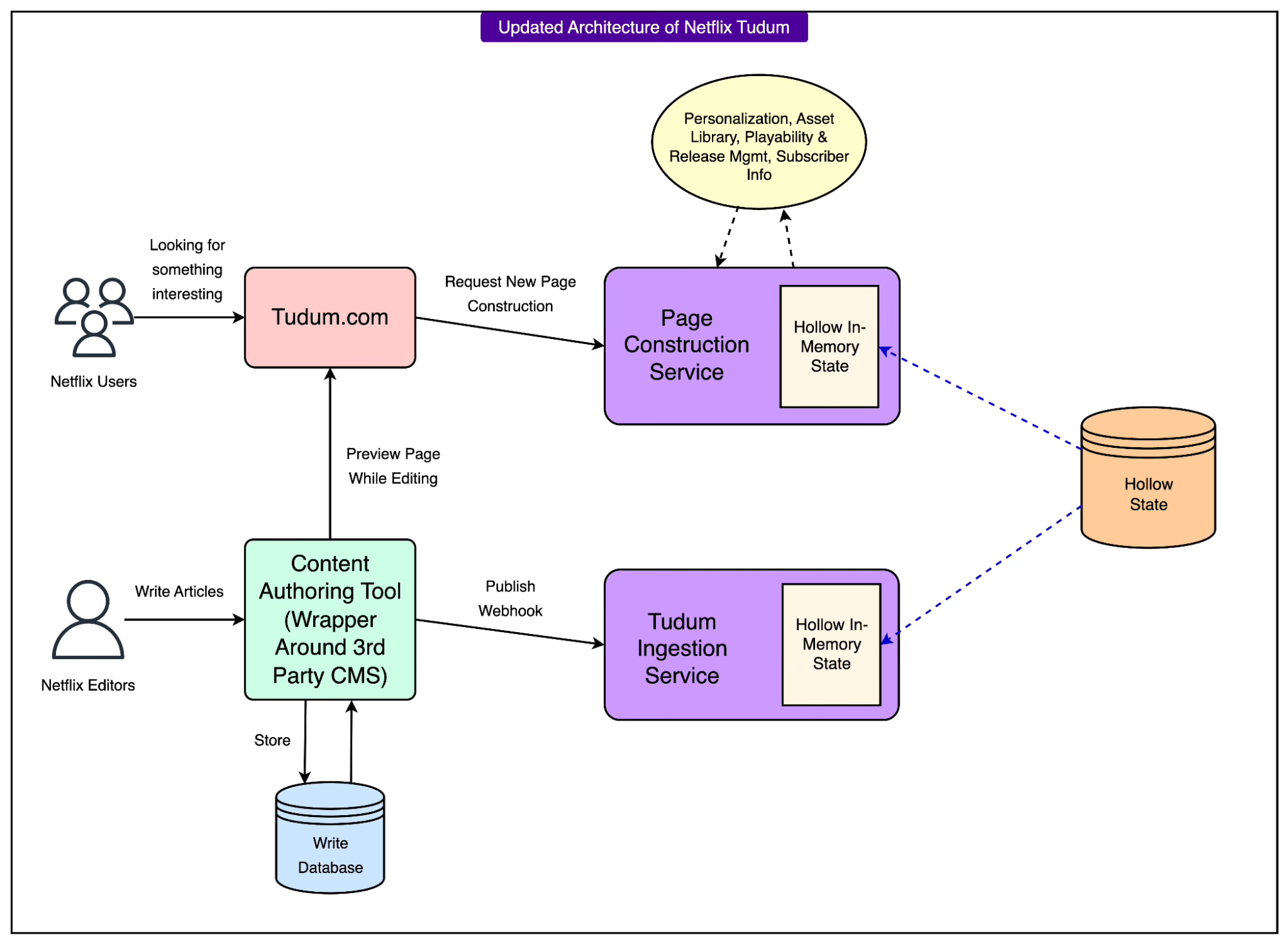
Here’s what changed in the architecture:
No more Page Data Service and near-cache: The old facade over the key-value store, which managed its own scheduled cache refresh cycles, was removed entirely. Services no longer wait for caches to update: the data they need is already in memory.
No external key-value store for read path: Cassandra (and the I/O it required) is no longer queried during page rendering or personalization. Instead, the entire read-optimized dataset is stored in RAM on every service instance via RAW Hollow.
No Kafka in the read path: While Kafka still has use cases elsewhere, the read side no longer depends on Kafka to propagate updates for serving live traffic. RAW Hollow handles data distribution and synchronization internally.
Embedded Hollow client in every microservice: Services like Page Construction, Search, and Personalization now run their own embedded Hollow clients. This gives them direct, O(1)-time access to the latest read-optimized content without network calls.
The new flow works as follows:
When content is updated in the write path, it’s processed into a read-optimized format
RAW Hollow distributes that update to all Hollow clients across service instances. This is known as the Hollow State, which is an in-memory dataset that each service process holds locally.
Because each instance has the full dataset in memory, any request (whether from an editor preview or a live user) is served immediately without cache checks or datastore queries.
For editorial preview, services can request strong read-after-write consistency, ensuring that the very latest update is displayed instantly.
This re-architecture shifted Tudum’s read path from a multi-hop network-bound pipeline to a memory-local lookup model. In essence, Netflix took the scalability and separation of CQRS but stripped away the read path’s I/O-heavy plumbing, replacing it with a memory-first, embedded data model.
Conclusion
The shift from a Kafka and Cassandra with a cache-based read path to a RAW Hollow in-memory model produced immediate and measurable improvements for Tudum. Some of the key benefits were as follows:
Massive latency reduction: In controlled tests (factoring out TLS, authentication, WAF, and logging overhead), home page construction time dropped from roughly 1.4 seconds to about 0.4 seconds once all read-path services consumed Hollow in-memory state. This speed gain directly impacts both editorial previews and live visitor requests.
Near-instant editorial preview: Editors now see updates reflected in seconds instead of waiting minutes for cache refresh cycles. Strong read-after-write consistency on preview requests ensures changes are visible immediately after saving in the CMS.
Small memory footprint: Compression allows the entire read dataset to fit comfortably in RAM. Three years’ worth of unhydrated content weighs in at about 130 MB, roughly 25% of its size in the previous Apache Iceberg format. This makes it viable to keep the full dataset co-located with every service instance without expensive scaling.
Operational simplicity: Removing Kafka, the external key-value store, and near-cache layers from the read path reduced moving parts and failure points, while eliminating cache-invalidation headaches.
Netflix’s re-architecture of Tudum’s read path shows how rethinking data access patterns can yield outsized gains in performance, simplicity, and developer experience.
By combining the scalability of CQRS with the speed of an in-memory, compressed object store like RAW Hollow, they created a system that serves both editorial agility and end-user responsiveness.
The lessons here are broadly applicable:
Minimize sequential operations in latency-critical flows.
Keep frequently accessed datasets as close to the application as possible.
Use consistency controls selectively to balance freshness with availability.
References:
Netflix Tudum Architecture: From CQRS with Kafka to CQRS with RAW Hollow
ByteByteGo Technical Interview Prep Kit
Launching the All-in-one interview prep. We’re making all the books available on the ByteByteGo website.

What's included:
System Design Interview
Coding Interview Patterns
Object-Oriented Design Interview
How to Write a Good Resume
Behavioral Interview (coming soon)
Machine Learning System Design Interview
Generative AI System Design Interview
Mobile System Design Interview
And more to come
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.
