
We are excited to announce the general availability of fine-grained compute and memory quota allocation with HyperPod task governance. With this capability, customers can optimize Amazon SageMaker HyperPod cluster utilization on Amazon Elastic Kubernetes Service (Amazon EKS), distribute fair usage, and support efficient resource allocation across different teams or projects. For more information, see HyperPod task governance best practices for maximizing the value of SageMaker HyperPod task governance.
Compute quota management is an administrative mechanism that sets and controls compute resource limits across users, teams, and projects. It controls fair resource distribution, preventing a single entity from monopolizing cluster resources, thereby optimizing overall computational efficiency.
Because of budget constraints, customers might want to allocate compute resources across multiple teams fairly. For example, a data scientist might need some GPUs (for example, four H100 GPUs) for model development, but not the entire instance’s compute capacity. In other cases, customers have limited compute resources but many teams, and they want to fairly share compute resources across these teams, so that no idle capacity is left unused.
With HyperPod task governance, administrators can now allocate granular GPU, vCPU, and vCPU memory to teams and projects—in addition to the entire instance resources—based on their preferred strategy. Key capabilities include GPU-level quota allocation by instance type and family, or hardware type—supporting both Trainium and NVIDIA GPUs—and optional CPU and memory allocation for fine-tuned resource control. Administrators can also define the weight (or priority level) a team is given for fair-share idle compute allocation.
“With a wide variety of frontier AI data experiments and production pipelines, being able to maximize SageMaker HyperPod Cluster utilization is extremely high impact. This requires fair and controlled access to shared resources like state-of-the-art GPUs, granular hardware allocation, and more. This is exactly what HyperPod task governance is built for, and we’re excited to see AWS pushing efficient cluster utilization for a variety of AI use cases.”
– Daniel Xu, Director of Product at Snorkel AI, whose AI data technology platform empowers enterprises to build specialized AI applications by leveraging their organizational expertise at scale.
In this post, we dive deep into how to define quotas for teams or projects based on granular or instance-level allocation. We discuss different methods to define such policies, and how data scientists can schedule their jobs seamlessly with this new capability.
Solution overview
Prerequisites
To follow the examples in this blog post, you need to meet the following prerequisites:
- An AWS account with access to SageMaker HyperPod. A running SageMaker HyperPod (EKS-orchestrated) cluster. For more information on how to create and configured a new HyperPod cluster, see the HyperPod workshop or the SageMaker HyperPod cluster creation with Amazon EKS orchestration. HyperPod task governance addon version 1.3 or later installed in the cluster. For more information, see set up HyperPod task governance
To schedule and execute the example jobs in the Submitting Tasks section, you will also need:
- A local environment (either your local machine or a cloud-based compute environment), from which to run the HyperPod CLI and kubectl commands, configured as follows:
- OS based on Linux or MacOS Python 3.8, 3.9, 3.10, or 3.11 installed AWS Command Line Interface (AWS CLI) configured with the appropriate credentials to use the above services HyperPod CLI version 3.1.0 Kubernetes command-line tool, kubectl
Allocating granular compute and memory quota using the AWS console
Administrators are the primary persona interacting with SageMaker HyperPod task governance and are responsible for managing cluster compute allocation in alignment with the organization’s strategic priorities and goals.
Implementing this feature follows the familiar compute allocation creation workflow of HyperPod task governance. To get started, sign in to the AWS Management Console and navigate to Cluster Management under HyperPod Clusters in the Amazon SageMaker AI console. After selecting your HyperPod cluster, select the Policies tab in the cluster detail page. Navigate to Compute allocations and choose Create.
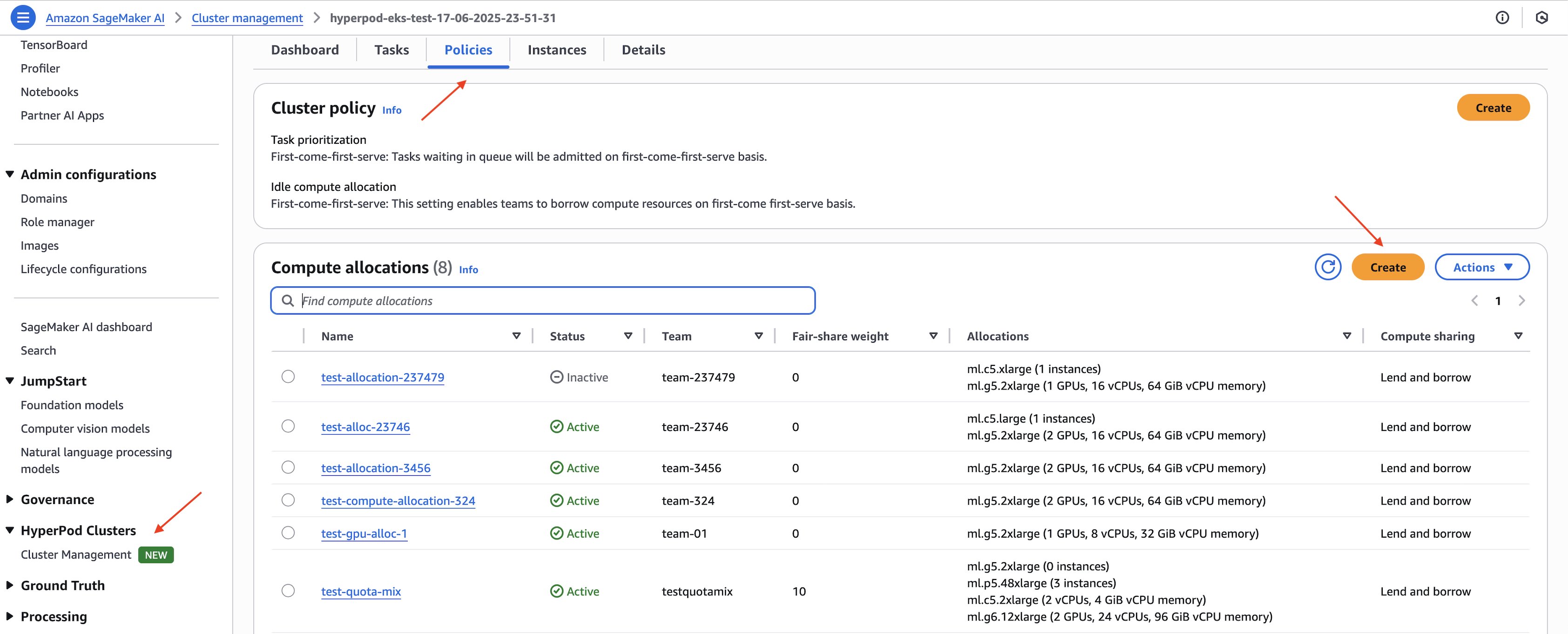
As with existing functionality, you can enable task prioritization and fair-share resource allocation through cluster policies that prioritize critical workloads and distribute idle compute across teams. By using HyperPod task governance, you can define queue admission policies (first-come-first-serve by default or task ranking) and idle compute allocation methods (first-come-first-serve or fair-share by default). In the Compute allocation section, you can create and edit allocations to distribute resources among teams, enable lending and borrowing of idle compute, configure preemption of low-priority tasks, and assign fair-share weights.
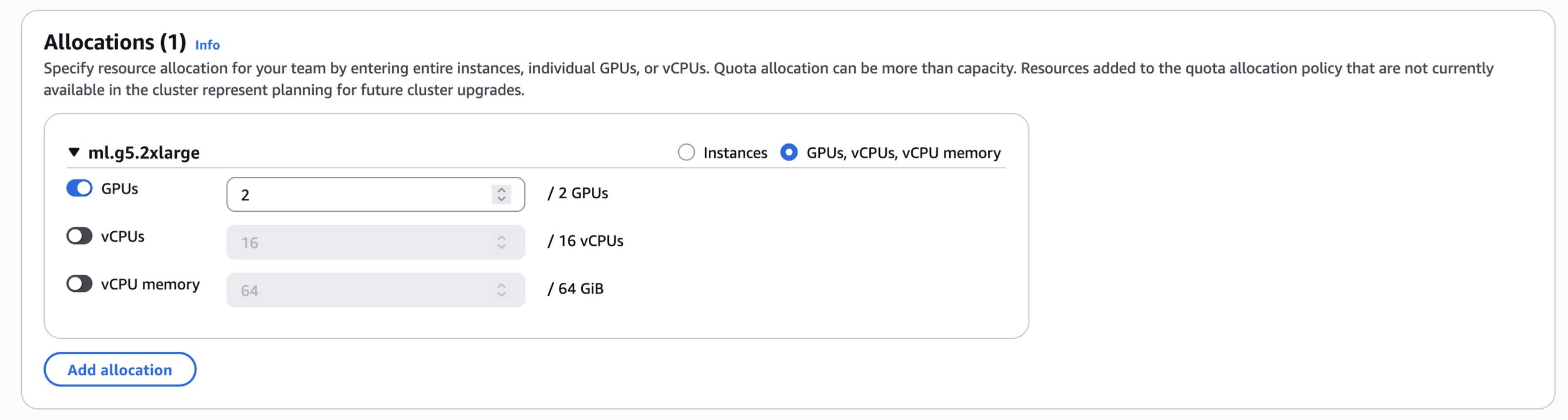
The key innovation is in the Allocations section shown in the following figure, where you’ll now find fine-grained options for resource allocation. In addition to the existing instance-level quotas, you can now directly specify GPU quotas by instance type and family or by hardware type. When you define GPU allocations, HyperPod task governance intelligently calculates appropriate default values for vCPUs and memory which are set proportionally.
For example, when allocating 2 GPUs from a single p5.48xlarge instance (which has 8 GPUs, 192 vCPUs, and 2 TiB memory) in your HyperPod cluster, HyperPod task governance assigns 48 vCPUs and 512 GiB memory as default values—which is equivalent to one quarter of the instance’s total resources. Similarly, if your HyperPod cluster contains 2 ml.g5.2xlarge instances (each with 1 GPU, 8 vCPUs, and 32 GiB memory), allocating 2 GPUs would automatically assign 16 vCPUs and 64 GiB memory from both instances as shown in the following image.
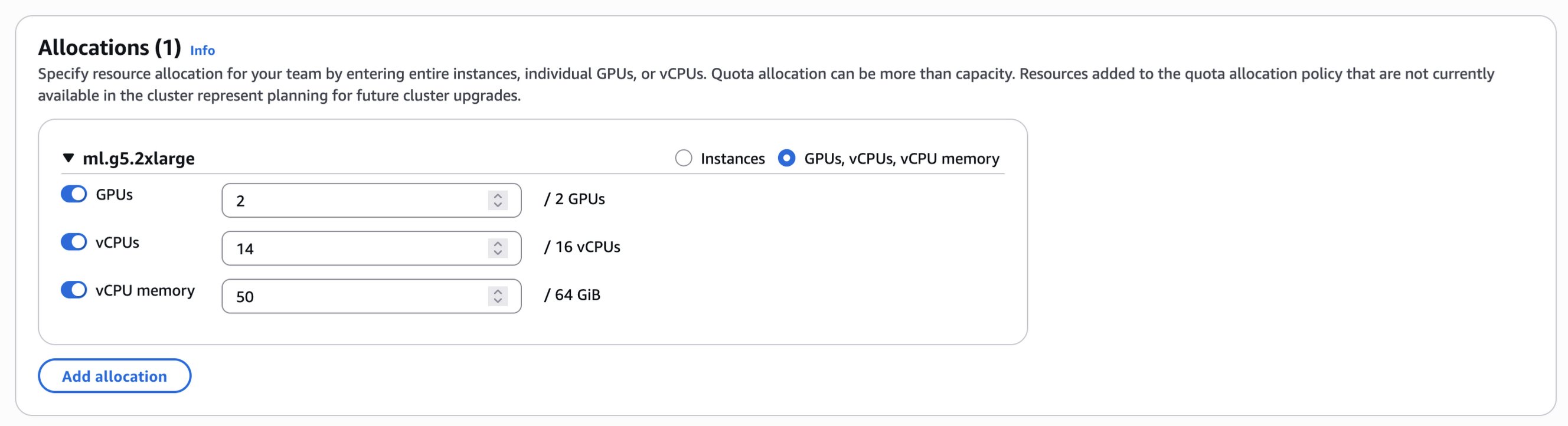
You can either proceed with these automatically calculated default values or customize the allocation by manually adjusting the vCPUs and vCPU memory fields as seen in the following image.
Amazon SageMaker HyperPod supports clusters that include CPU-based instances, GPU-based instances, and AWS Neuron-based hardware (AWS Inferentia and AWS Trainium chips). You can specify resource allocation for your team by instances, GPUs, vCPUs, vCPU memory, or Neuron devices, as shown in the following image.
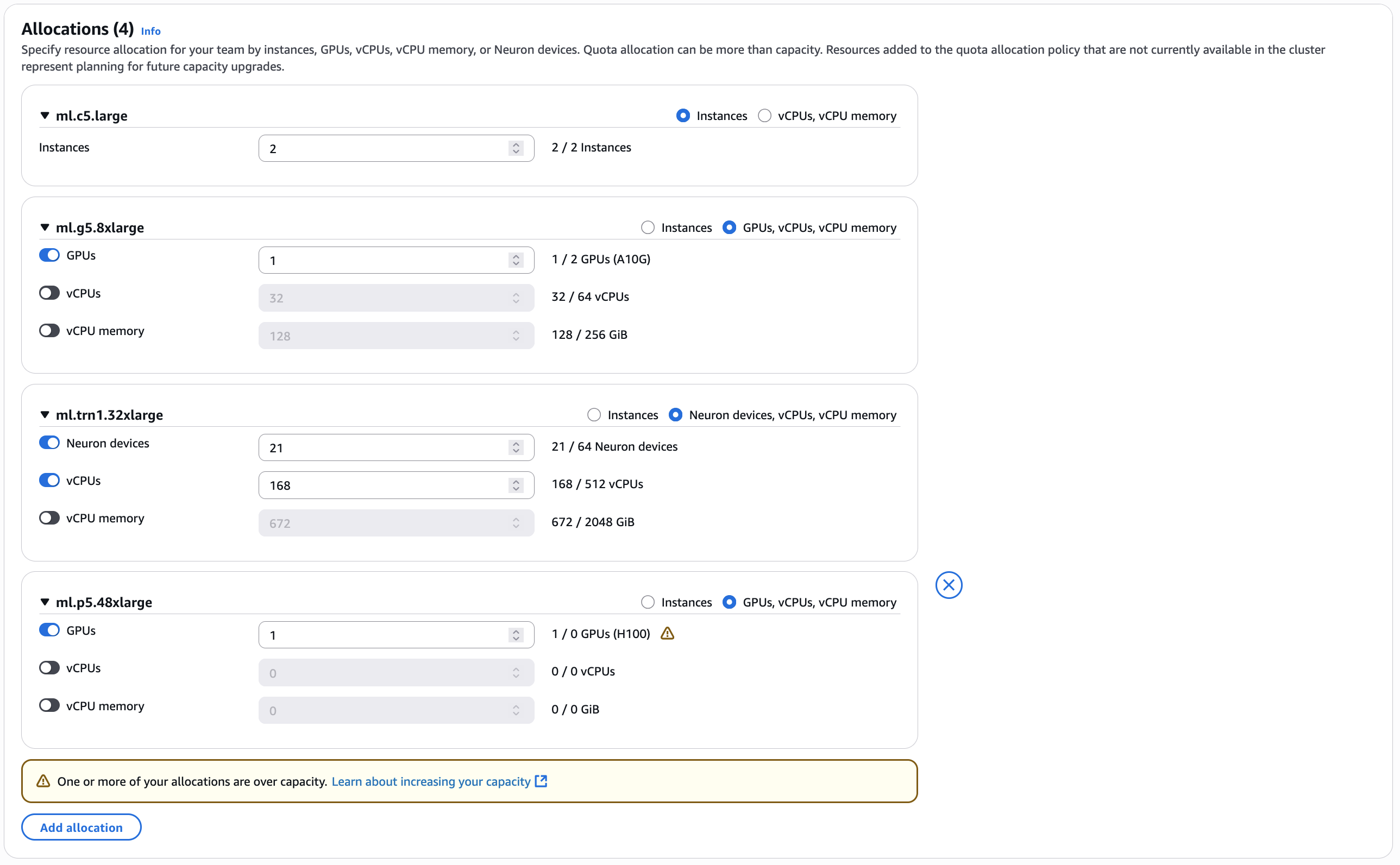
Quota allocation can be more than capacity. Resources added to the compute allocation policy that aren’t currently available in the cluster represent planning for future capacity upgrades. Jobs that require these unprovisioned resources will be automatically queued and remain in a pending state until the necessary resources become available. It’s important to understand that in SageMaker HyperPod, compute allocations function as quotas, which are verified during workload scheduling to understand if a workload should be admitted or not, regardless of actual capacity availability. When resource requests are within these defined allocation limits and current utilization, the Kubernetes scheduler (kube-scheduler) handles the actual distribution and placement of pods across the HyperPod cluster nodes.
Allocating granular compute and memory quota using AWS CLI
You can also create or update compute quotas using the AWS CLI. The following is an example for creating a compute quota with only GPU count specification using the AWS CLI:
Compute quotas can also be created with mixed quota types, including a certain number of instances and granular compute resources, as shown in the following example:
HyperPod task governance deep dive
SageMaker HyperPod task governance enables allocation of GPU, CPU, and memory resources by integrating with Kueue, a Kubernetes-native system for job queueing.
Kueue doesn’t replace existing Kubernetes scheduling components, but rather integrates with the kube-scheduler, such that Kueue decides whether a workload should be admitted based on the resource quotas and current utilization, and then the kube-scheduler takes care of pod placement on the nodes.
When a workload requests specific resources, Kueue selects an appropriate resource flavor based on availability, node affinity, and job priority. The scheduler then injects the corresponding node labels and tolerations into the PodSpec, allowing Kubernetes to place the pod on nodes with the requested hardware configuration. This supports precise resource governance and efficient allocation for multi-tenant clusters.
When a SageMaker HyperPod task governance compute allocation is created, Kueue creates ClusterQueues that define resource quotas and scheduling policies, along with ResourceFlavors for the selected instance types with their unique resource characteristics.
For example, the following compute allocation policy allocates ml.g6.12xlarge instances with 2 GPUs and 48 vCPUs to the onlygputeam team, implementing a LendAndBorrow strategy with an up to 50% borrowing limit. This configuration enables flexible resource sharing while maintaining priority through a fair share weight of 10 and the ability to preempt lower priority tasks from other teams.
The corresponding Kueue ClusterQueue is configured with the ml.g6.12xlarge flavor, providing quotas for 2 NVIDIA GPUs, 48 CPU cores, and 192 Gi memory.
A Kueue LocalQueue will be also created, and will reference the corresponding ClusterQueue. The LocalQueue acts as the namespace-scoped resource through which users can submit workloads, and these workloads are then admitted and scheduled according to the quotas and policies defined in the ClusterQueue.
Submitting tasks
There are two ways to submit tasks on Amazon EKS orchestrated SageMaker HyperPod clusters: the SageMaker HyperPod CLI and the Kubernetes command-line tool, kubectl. With both options, data scientists need to reference their team’s namespace and task priority class—in addition to the requested GPU and vCPU compute and memory resources—to use their granular allocated quota with appropriate prioritization. If the user doesn’t specify a priority class, then SageMaker HyperPod task governance will automatically assume the lowest priority. The specific GPU type comes from an instance type selection, because data scientists want to use GPUs with certain capabilities (for example, H100 instead of H200) to perform their tasks efficiently.
HyperPod CLI
The HyperPod CLI was created to abstract the complexities of working with kubectl and so that developers using SageMaker HyperPod can iterate faster with custom commands.The following is an example of a job submission with the HyperPod CLI requesting both compute and memory resources:
The highlighted parameters enable requesting granular compute and memory resources. The HyperPod CLI requires to install the HyperPod Training Operator in the cluster and then build a container image that includes the HyperPod Elastic Agent. For further instructions on how to build such container image, please refer to the HyperPod Training Operator documentation.
For more information on the supported HyperPod CLI arguments and related description, see the SageMaker HyperPod CLI reference documentation.
Kubectl
The following is an example of a kubectl command to submit a job to the HyperPod cluster using the specified queue. This is a simple example of a PyTorch job that will check for GPU availability and then sleep for 5 minutes. Compute and memory resources are requested using the standard Kubernetes resource management constructs.
Following is a short reference guide for helpful commands when interacting with SageMaker HyperPod task governance:
- Describing cluster policy with the AWS CLI – This AWS CLI command is useful for viewing the cluster policy settings for your cluster. List compute quota allocations with the AWS CLI – Use this AWS CLI command to view the different teams and set up task governance and their respective quota allocation settings. HyperPod CLI – The HyperPod CLI abstracts common kubectl commands used to interact with SageMaker HyperPod clusters such as submitting, listing, and cancelling tasks. See the SageMaker HyperPod CLI reference documentation for a full list of commands. kubectl – You can also use kubectl to interact with task governance; some useful commands are:
kubectl get workloads -n hyperpod-ns-<team-name> kubectl describe workload <workload-name> -n hyperpod-ns-<team-name>. These commands show the workloads running in your cluster per namespace and provide detailed reasonings on Kueue admission. You can use these commands to answer questions such as “Why was my task preempted?” or “Why did my task get admitted?”
Common scenarios
A common use case for more granular allocation of GPU compute is fine-tuning small and medium sized large language models (LLMs). A single H100 or H200 GPU might be sufficient to address such a use case (also depending on the chosen batch size and other factors), and machine learning (ML) platform administrators can choose to allocate a single GPU to each data scientist or ML researcher to optimize the utilization of an instance like ml.p5.48xlarge, which comes with 8 H100 GPUs onboard.
Small language models (SLMs) have emerged as a significant advancement in generative AI, offering lower latency, decreased deployment costs, and enhanced privacy capabilities while maintaining impressive performance on targeted tasks, making them increasingly vital for agentic workflows and edge computing scenarios. The new SageMaker HyperPod task governance with fine-grained GPU, CPU, and memory allocation significantly enhances SLM development by enabling precise matching of resources to model requirements, allowing teams to efficiently run multiple experiments concurrently with different architectures. This resource optimization is particularly valuable as organizations develop specialized SLMs for domain-specific applications, with priority-based scheduling so that critical model training jobs receive resources first while maximizing overall cluster utilization. By providing exactly the right resources at the right time, HyperPod accelerates the development of specialized, domain-specific SLMs that can be deployed as efficient agents in complex workflows, enabling more responsive and cost-effective AI solutions across industries.
With the growing popularity of SLMs, organizations can use granular quota allocation to create targeted quota policies that prioritize GPU resources, addressing the budget-sensitive nature of ML infrastructure where GPUs represent the most significant cost and performance factor. Organizations can now selectively apply CPU and memory limits where needed, creating a granular resource management approach that efficiently supports diverse machine learning workloads regardless of model size.
Similarly, to support inference workloads, multiple teams might not require an entire instance to deploy their models, helping to avoid having entire instances equipped with multiple GPUs allocated to each team and leaving GPU compute sitting idle.
Finally, during experimentation and algorithm development, data scientists and ML researchers can choose to deploy a container hosting their preferred IDE on HyperPod, like JupyterLab or Code-OSS (Visual Studio Code open source). In this scenario, they often experiment with smaller batch sizes before scaling to multi-GPU configurations, hence not needing entire multi-GPU instances to be allocated.Similar considerations apply to CPU instances; for example, an ML platform administrator might decide to use CPU instances for IDE deployment, because data scientists prefer to scale their training or fine-tuning with jobs rather than experimenting with the local IDE compute. In such cases, depending on the instances of choice, partitioning CPU cores across the team might be beneficial.
Conclusion
The introduction of fine-grained compute quota allocation in SageMaker HyperPod represents a significant advancement in ML infrastructure management. By enabling GPU-level resource allocation alongside instance-level controls, organizations can now precisely tailor their compute resources to match their specific workloads and team structures.
This granular approach to resource governance addresses critical challenges faced by ML teams today, balancing budget constraints, maximizing expensive GPU utilization, and ensuring fair access across data science teams of all sizes. Whether fine-tuning SLMs that require single GPUs, running inference workloads with varied resource needs, or supporting development environments that don’t require full instance power, this flexible capability helps ensure that no compute resources sit idle unnecessarily.
ML workloads continue to diversify in their resource requirements and SageMaker HyperPod task governance now provides the adaptability organizations need to optimize their GPU capacity investments. To learn more, visit the SageMaker HyperPod product page and HyperPod task governance documentation.
Give this a try in the Amazon SageMaker AI console and leave your comments here.
About the authors
 Siamak Nariman is a Senior Product Manager at AWS. He is focused on AI/ML technology, ML model management, and ML governance to improve overall organizational efficiency and productivity. He has extensive experience automating processes and deploying various technologies.
Siamak Nariman is a Senior Product Manager at AWS. He is focused on AI/ML technology, ML model management, and ML governance to improve overall organizational efficiency and productivity. He has extensive experience automating processes and deploying various technologies.
 Zhenshan Jin is a Senior Software Engineer at Amazon Web Services (AWS), where he leads software development for task governance on SageMaker HyperPod. In his role, he focuses on empowering customers with advanced AI capabilities while fostering an environment that maximizes engineering team efficiency and productivity.
Zhenshan Jin is a Senior Software Engineer at Amazon Web Services (AWS), where he leads software development for task governance on SageMaker HyperPod. In his role, he focuses on empowering customers with advanced AI capabilities while fostering an environment that maximizes engineering team efficiency and productivity.
 Giuseppe Angelo Porcelli is a Principal Machine Learning Specialist Solutions Architect for Amazon Web Services. With several years of software engineering and an ML background, he works with customers of any size to understand their business and technical needs and design AI and ML solutions that make the best use of the AWS Cloud and the Amazon Machine Learning stack. He has worked on projects in different domains, including MLOps, computer vision, and NLP, involving a broad set of AWS services. In his free time, Giuseppe enjoys playing football.
Giuseppe Angelo Porcelli is a Principal Machine Learning Specialist Solutions Architect for Amazon Web Services. With several years of software engineering and an ML background, he works with customers of any size to understand their business and technical needs and design AI and ML solutions that make the best use of the AWS Cloud and the Amazon Machine Learning stack. He has worked on projects in different domains, including MLOps, computer vision, and NLP, involving a broad set of AWS services. In his free time, Giuseppe enjoys playing football.
 Sindhura Palakodety is a Solutions Architect at AWS. She is passionate about helping customers build enterprise-scale Well-Architected solutions on the AWS platform and specializes in the data analytics domain.
Sindhura Palakodety is a Solutions Architect at AWS. She is passionate about helping customers build enterprise-scale Well-Architected solutions on the AWS platform and specializes in the data analytics domain.
