
Table of contents
Meta Superintelligence Labs has unveiled REFRAG (REpresentation For RAG), a decoding framework that rethinks retrieval-augmented generation (RAG) efficiency. REFRAG extends LLM context windows by 16× and achieves up to a 30.85× acceleration in time-to-first-token (TTFT) without compromising accuracy.
Why is long context such a bottleneck for LLMs?
The attention mechanism in large language models scales quadratically with input length. If a document is twice as long, the compute and memory cost can grow fourfold. This not only slows inference but also increases the size of the key-value (KV) cache, making large-context applications impractical in production systems. In RAG settings, most retrieved passages contribute little to the final answer, but the model still pays the full quadratic price to process them.
How does REFRAG compress and shorten context?
REFRAG introduces a lightweight encoder that splits retrieved passages into fixed-size chunks (e.g., 16 tokens) and compresses each into a dense chunk embedding. Instead of feeding thousands of raw tokens, the decoder processes this shorter sequence of embeddings. The result is a 16× reduction in sequence length, with no change to the LLM architecture.
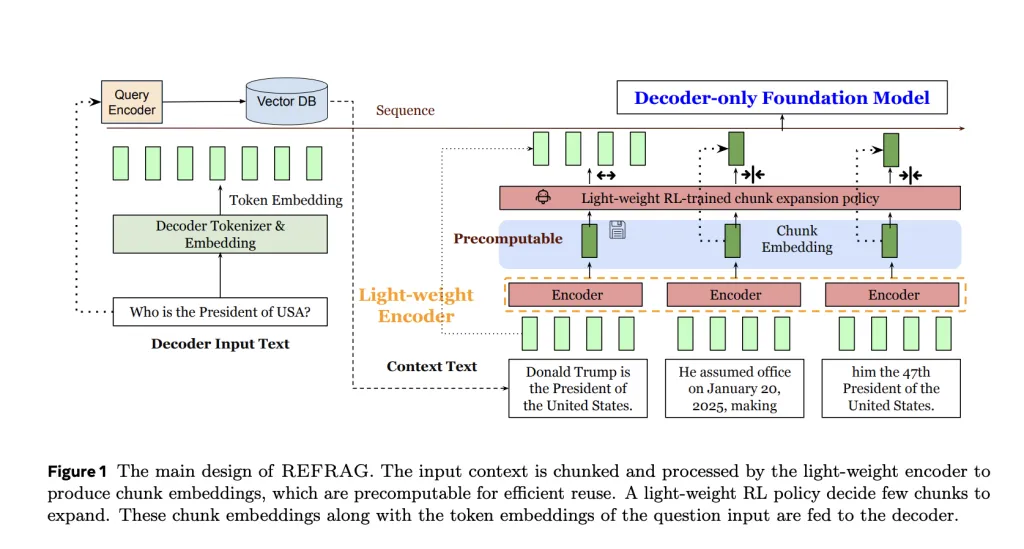
How is acceleration achieved?
By shortening the decoder’s input sequence, REFRAG reduces the quadratic attention computation and shrinks the KV cache. Empirical results show 16.53× TTFT acceleration at k=16 and 30.85× acceleration at k=32, far surpassing prior state-of-the-art CEPE (which achieved only 2–8×). Throughput also improves by up to 6.78× compared to LLaMA baselines.
How does REFRAG preserve accuracy?
A reinforcement learning (RL) policy supervises compression. It identifies the most information-dense chunks and allows them to bypass compression, feeding raw tokens directly into the decoder. This selective strategy ensures that critical details—such as exact numbers or rare entities—are not lost. Across multiple benchmarks, REFRAG maintained or improved perplexity compared to CEPE while operating at far lower latency.
What do the experiments reveal?
REFRAG was pretrained on 20B tokens from the SlimPajama corpus (Books + arXiv) and tested on long-context datasets including Book, Arxiv, PG19, and ProofPile. On RAG benchmarks, multi-turn conversation tasks, and long-document summarization, REFRAG consistently outperformed strong baselines:
- 16× context extension beyond standard LLaMA-2 (4k tokens).~9.3% perplexity improvement over CEPE across four datasets.Better accuracy in weak retriever settings, where irrelevant passages dominate, due to the ability to process more passages under the same latency budget.

Summary
REFRAG shows that long-context LLMs don’t have to be slow or memory-hungry. By compressing retrieved passages into compact embeddings, selectively expanding only the important ones, and rethinking how RAG decoding works, Meta Superintelligence Labs has made it possible to process much larger inputs while running dramatically faster. This makes large-context applications—like analyzing entire reports, handling multi-turn conversations, or scaling enterprise RAG systems—not only feasible but efficient, without compromising accuracy.

FAQs
Q1. What is REFRAG?
REFRAG (REpresentation For RAG) is a decoding framework from Meta Superintelligence Labs that compresses retrieved passages into embeddings, enabling faster and longer-context inference in LLMs.
Q2. How much faster is REFRAG compared to existing methods?
REFRAG delivers up to 30.85× faster time-to-first-token (TTFT) and 6.78× throughput improvement compared to LLaMA baselines, while outperforming CEPE.
Q3. Does compression reduce accuracy?
No. A reinforcement learning policy ensures critical chunks remain uncompressed, preserving key details. Across benchmarks, REFRAG maintained or improved accuracy relative to prior methods.
Q4. Where will the code be available?
Meta Superintelligence Labs will release REFRAG on GitHub at facebookresearch/refrag
Check out the PAPER here. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
The post Meta Superintelligence Labs Introduces REFRAG: Scaling RAG with 16× Longer Contexts and 31× Faster Decoding appeared first on MarkTechPost.
