
Retrieval-Augmented Generation (RAG) systems generally rely on dense embedding models that map queries and documents into fixed-dimensional vector spaces. While this approach has become the default for many AI applications, a recent research from Google DeepMind team explains a fundamental architectural limitation that cannot be solved by larger models or better training alone.
What Is the Theoretical Limit of Embedding Dimensions?
At the core of the issue is the representational capacity of fixed-size embeddings. An embedding of dimension d cannot represent all possible combinations of relevant documents once the database grows beyond a critical size. This follows from results in communication complexity and sign-rank theory.
- For embeddings of size 512, retrieval breaks down around 500K documents.For 1024 dimensions, the limit extends to about 4 million documents.For 4096 dimensions, the theoretical ceiling is 250 million documents.
These values are best-case estimates derived under free embedding optimization, where vectors are directly optimized against test labels. Real-world language-constrained embeddings fail even earlier.

How Does the LIMIT Benchmark Expose This Problem?
To test this limitation empirically, Google DeepMind Team introduced LIMIT (Limitations of Embeddings in Information Retrieval), a benchmark dataset specifically designed to stress-test embedders. LIMIT has two configurations:
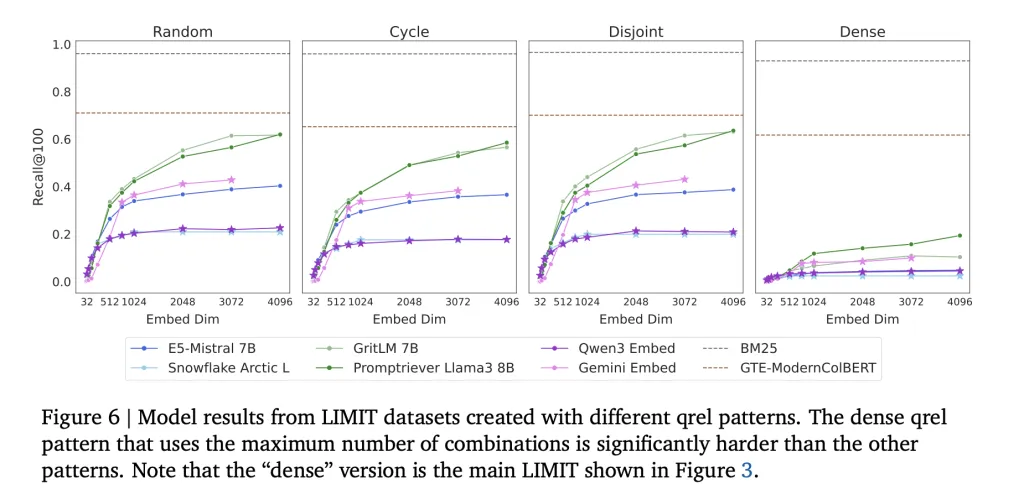
- LIMIT full (50K documents): In this large-scale setup, even strong embedders collapse, with recall@100 often falling below 20%.LIMIT small (46 documents): Despite the simplicity of this toy-sized setup, models still fail to solve the task. Performance varies widely but remains far from reliable:
- Promptriever Llama3 8B: 54.3% recall@2 (4096d)GritLM 7B: 38.4% recall@2 (4096d)E5-Mistral 7B: 29.5% recall@2 (4096d)Gemini Embed: 33.7% recall@2 (3072d)
Even with just 46 documents, no embedder reaches full recall, highlighting that the limitation is not dataset size alone but the single-vector embedding architecture itself.
In contrast, BM25, a classical sparse lexical model, does not suffer from this ceiling. Sparse models operate in effectively unbounded dimensional spaces, allowing them to capture combinations that dense embeddings cannot.
Why Does This Matter for RAG?
CCurrent RAG implementations typically assume that embeddings can scale indefinitely with more data. The Google DeepMind research team explains how this assumption is incorrect: embedding size inherently constrains retrieval capacity. This affects:
- Enterprise search engines handling millions of documents.Agentic systems that rely on complex logical queries.Instruction-following retrieval tasks, where queries define relevance dynamically.
Even advanced benchmarks like MTEB fail to capture these limitations because they test only a narrow part/section of query-document combinations.
What Are the Alternatives to Single-Vector Embeddings?
The research team suggested that scalable retrieval will require moving beyond single-vector embeddings:
- Cross-Encoders: Achieve perfect recall on LIMIT by directly scoring query-document pairs, but at the cost of high inference latency.Multi-Vector Models (e.g., ColBERT): Offer more expressive retrieval by assigning multiple vectors per sequence, improving performance on LIMIT tasks.Sparse Models (BM25, TF-IDF, neural sparse retrievers): Scale better in high-dimensional search but lack semantic generalization.
The key insight is that architectural innovation is required, not simply larger embedders.

What is the Key Takeaway?
The research team’s analysis shows that dense embeddings, despite their success, are bound by a mathematical limit: they cannot capture all possible relevance combinations once corpus sizes exceed limits tied to embedding dimensionality. The LIMIT benchmark demonstrates this failure concretely:
- On LIMIT full (50K docs): recall@100 drops below 20%.On LIMIT small (46 docs): even the best models max out at ~54% recall@2.
Classical techniques like BM25, or newer architectures such as multi-vector retrievers and cross-encoders, remain essential for building reliable retrieval engines at scale.
Check out the PAPER here. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
The post Google DeepMind Finds a Fundamental Bug in RAG: Embedding Limits Break Retrieval at Scale appeared first on MarkTechPost.
