
為了設法克服當前大型語言模型(LLM)面臨的記憶體容量瓶頸問題,過去1年多以來,湧現一大批記憶體擴展解決方案,各自從不同技術路線出發,為LLM提供額外記憶體資源。
LLM記憶體擴展產品類型
從記憶體資源的來源,我們可將LLM記憶體擴展方案分為兩條路線:外部擴展、內部擴展。
外部擴展形式產品
HBM記憶體與GPU的連接,是透過專門的中介層(Interposer)基板,HBM與GPU之間是晶片層級的整合,在製造階段就被嵌入為GPU單元的一部分,受GPU晶片封裝與接腳布線的物理限制,HBM記憶體容量是固定的,用戶不能視需要額外擴充。
解決這個問題最直接的方法,就是利用GPU外部的其他記憶體資源,來擴充LLM可用記憶體空間,將LLM的記憶體工作負載,從GPU的HBM記憶體,卸載(Offload)到外部記憶體裝置上。
而這些外部記憶體資源,包括GPU伺服器本身的DRAM、SSD,或是透過網路介接的外接式DRAM裝置,以及快閃儲存設備等。
這便是「外部擴展」路線,也是當前大部分LLM記憶體擴展方案的做法,優點是導入門檻低,以及不受GPU綑綁的靈活擴充能力。
首先,這類擴展方案與GPU之間,是軟體層次的整合,在記憶體管理軟體控制下,將這些外部的DRAM或快閃記憶體,構成可供LLM存取的虛擬記憶體空間,不涉及深層次的硬體整合,便於部署。其次,這些記憶體裝置都獨立於GPU之外,終端用戶可視需要靈活配置,隨插即用,擴展能力與部署彈性都更大。
而這類方案的缺點,則是傳輸頻寬受限於PCIe。除了採用GPU至CPU直連整合架構的伺服器,多數應用環境下,GPU與伺服器DRAM,或其他外部記憶體裝置之間的資料傳輸,都必須透過PCIe介面,資料傳輸頻寬低於與GPU直連的HBM記憶體,或GPU互連專用的介面(如NVLink或Infinity Fabric)。即便是PCIe 5.0 x16介面,頻寬也只相當於HBM3或HBM3e的1/7到1/10,或NVLink的1/5。
也就是說,外部擴展方案是「以較低的頻寬交換更大的擴展能力」。
內部擴展型式產品
「內部擴展」形式的LLM記憶體擴展路線,目前只有高頻寬快閃記憶體(High Bandwidth Flash,HBF)這一種產品。HBF架構與HBM相似,都是與GPU在晶片層級整合,但採用儲存密度更高的NAND快閃記憶體,取代基於DRAM而成的HBM,從而提供較HBM高出十多倍的容量。
HBF這種「內部擴展」路線,同樣能達到大幅擴展LLM可用記憶體資源的目的,優點是具備與HBM相當的傳輸頻寬,而且由於更接近GPU,存取延遲也低於外部擴展類型方案,缺點則是與GPU深度綑綁,終端用戶不具備配置與擴充的自由與靈活性,特徵與外部記憶體擴展方案正好相反。
擴展記憶體的效益
外部與內部擴展這兩種架構,雖然技術路線與著眼點有異,但應用上互不衝突,可以並存,而且根本目的相同,都是為了幫助LLM擺脫GPU HBM容量有限的束縛,大幅增加可用記憶體空間。
無論HBF,還是基於DRAM或快閃儲存裝置的擴展方案,效能都遜於HBM,但遠勝過讓GPU耗費在重新計算Token,或是從速度更慢的底層儲存裝置載入資料。
而且,這些擴展記憶體裝置的單位成本,都比HBM低了數個層次,DDR DRAM單位容量成本不到HBM的1/5,而快閃記憶體的成本低於DRAM的1/10,因此可「以量取勝」,輕易為LLM提供數十TB、數百TB等級的額外記憶體空間,從而帶來2大效益:
(1)顯著提高LLM執行訓練與推論的能力。
透過擴展方案提供的額外記憶體空間,可以容納只靠GPU HBM無法容納的大規模LLM參數,也能採用更高的計算精度,或是保存更多的運算過程內容,以及支援數量更多的輸入與輸出Token等。
(2)大幅改善LLM基礎設施的成本效益。
原本需要匯聚大量GPU單元,才能獲得TB等級,或是數十、數百TB等級記憶體空間,現在只需少數GPU單元,搭配外部記憶體擴展方案就能獲得,整體成本大為降低。
接下來,我們便逐一檢視當前已發表的LLM記憶體擴展方案與產品。
高頻寬快閃記憶體
Sandisk在2025年2月投資者日,率先揭露的高頻寬快閃記憶體(HBF),可視為高頻寬記憶體(HBM)的快閃記憶體版本,是針對頻寬最佳化的快閃記憶體概念。
現有快閃記憶體是基於成本最佳化設計,數萬個快閃記憶體儲存單元(Cell)組成大型陣列,構成基本讀寫存取的分頁(Page),並共用1條I/O通道,HBF則細分為多個較小型的陣列,每個小型陣列各有獨立的I/O通道,從而大幅提高I/O頻寬。
在實作上,HBF架構十分類似HBM,將16層垂直堆疊的裸晶(Die)先連接邏輯晶片(Logic Die),然後再透過中介層基板與GPU連接。
Sandisk利用其CMOS直接鍵結至陣列(CMOS directly Bonded to Array)技術,將3D NAND快閃記憶體的核心裸晶(Core Die)連接到邏輯晶片上,邏輯晶片再透過中介層基板連接GPU。而這些堆疊的晶片之間,也像HBM一樣透過矽穿孔(silicon vias,TSV)互連,但容量比HBM更大。Sandisk聲稱,HBF可在頻寬相當於HBM的同時,以相似成本提供8到16倍容量。
Sandisk設想可在單個GPU上,整合8個512 GB的HBF晶片,從而提供高達4 TB記憶體容量,比起當前HBM容量最高的GPU(如Nvidia B300或AMD MI350均配置288 GB HBM),高出14倍以上,從而讓單一GPU即可容納GPT-4的1.8萬億個參數(FP16精度下需耗用3.6TB記憶體)。
大容量的HBF,也能配合MOE架構LLM運作,例如512 GB HBF記憶體可承載640億規模(64B)參數的MOE模型,並區分為8個64 GB的小型記憶體陣列,每個小陣列分別為MOE的1個專家單元提供記憶體空間服務。
Sandisk表示,他們發展HBF架構已有1年以上,並獲得主要AI應用用戶的反饋。在稍早的今年8月,Sandisk與HBM記憶體主要供應商SK海力士共同發布消息,表示正在合作進行HBF的標準化與供應來源多元化,也就是說,除Sandisk外,SK海力士未來也能產製HBF,最終促成HBF成為業界標準。
Sandisk預期2026年下半推出首批HBF樣品,至於應用HBF的AI推理設備則預計於2027年初上市。
LLM外部記憶體擴展產品
將LLM的記憶體工作負載,卸載到GPU外部記憶體裝置上的外部記憶體擴展方案,又可依應用型態與產品構成,細分為多種類型。
從應用型態來看,可分為通用型與KV快取卸載型等2大類。前者可同時LLM訓練與推論階段的記憶體卸載,後者則主要針對LLM推論階段的KV快取卸載應用。
接下來我們便以應用型態作為基本區分,來檢視當前的LLM外部記憶體擴展產品。
通用型LLM記憶體擴展產品
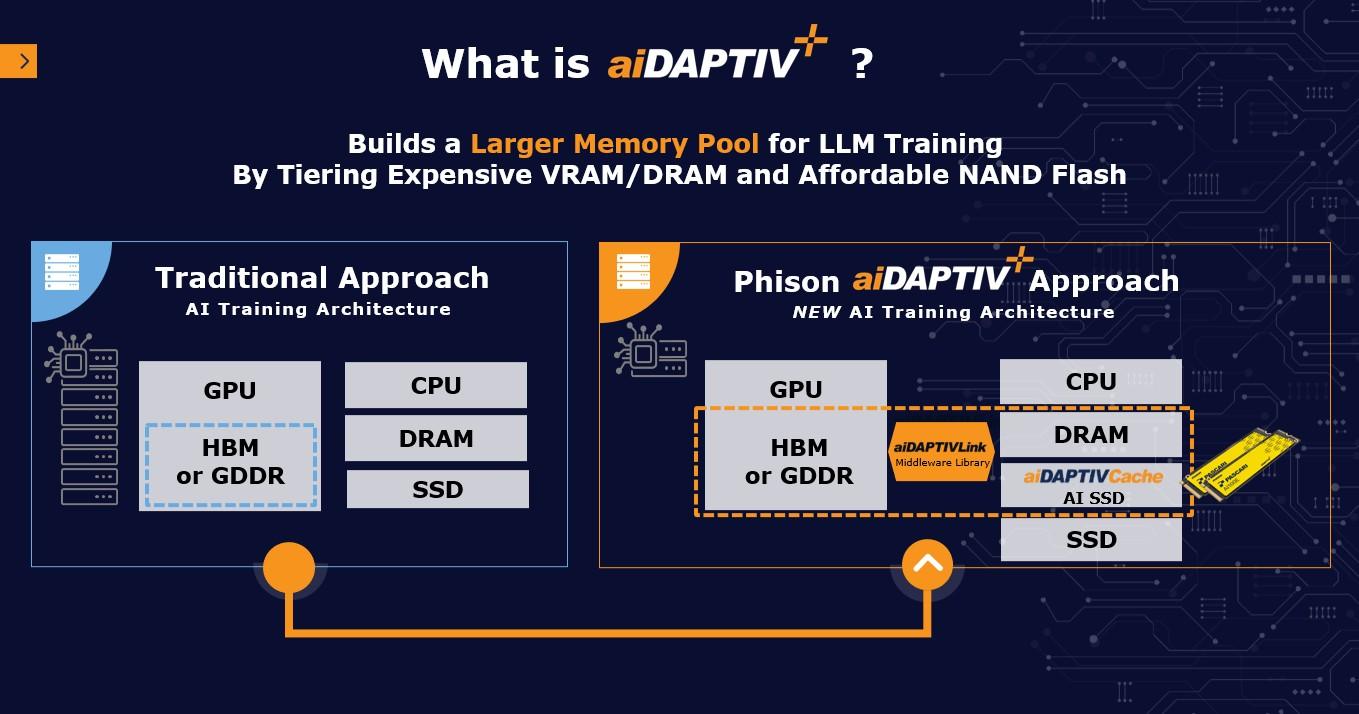
原則上,LLM外部記憶體擴展產品,應能同時用於訓練與推論階段的記憶體工作負載,但目前絕大多數產品都聚焦推論階段的應用,目前公開資料中,聲稱能同時涵蓋LLM訓練與推論應用的產品,我們已知只有群聯(Phison)在2023年7月發表的aiDAPTIV+。
aiDAPTIV+由aiDAPTIVLink中介軟體,aiDAPTIVCache快取用SSD,以及aiDAPTIV+ Pro Suit附屬軟體套件等3部分構成。
整個方案的核心,是部署在GPU伺服器上的aiDAPTIVLink中介軟體,用於統一管理GPU伺服器的記憶體存取,可將GPU伺服器的各式記憶體裝置,包括GPU的HBM或GDDR記憶體,CPU的DRAM,或NVMe SSD,設定為跨不同類型記憶體的虛擬化記憶體池。
當GPU伺服器載入AI模型時,aiDAPTIVLink會分析記憶體需求,將資料切分,分別載入GPU HBM、CPU DRAM,或SSD,並隨著AI模型運行,視存取需求在3個虛擬記憶體層之間移動資料,以維持GPU利用率,避免重新計算Token。
aiDAPTIV+主要訴求是可大幅降低用戶端LLM訓練設施門檻,讓只配備較少GPU與HBM記憶體的環境,利用CPU DRAM與SSD作為額外記憶體空間,從而運行較大規模的LLM。也能改善推論效能,縮短第1個Token產生時間(Time to First Token,TTFT),擴展上下文Token長度。
而利用外部記憶體參與執行LLM訓練的代價,則是較慢的存取速度。所以,這類方案適合對成本敏感,但對於運算時間較不敏感的用戶。
KV快取卸載型產品
絕大多數LLM記憶體擴展方案,都將應用面向局限在推論過程中的KV快取卸載,而非用於載入模型參數,以免速度較慢的外部記憶體,對LLM運作效能帶來太多衝擊。
KV快取卸載的目的,是將存取頻率較低的KV快取資料,從GPU的HBM記憶體移到外部記憶體,藉此可容納更多KV快取資料,大幅提高GPU伺服器可處理的上下文區間,也大幅減少GPU重複計算Token的需要,以及降低處理上下文的成本。
我們在6月的封面故事《AI硬體架構新變革:KV快取產品崛起》,曾初步介紹KV快取卸載產品情況,時隔近3個月後,情況又有所變化,出現新的廠商與新的產品型態,促使我們重新梳理這個領域的現況。
依產品部署型態,可以是否搭配特定儲存平臺或硬體裝置,將KV快取卸載產品分為純軟體形式,以及結合特定硬體平臺裝置等2大類型。
軟體式產品
如Mooncake、AIBrix、LMCache、Alluxio等開源的KV快取卸載軟體專案,還有Nvidia的Dynamo推理軟體框架,以及GridGain的共享記憶體等,這類方案無須搭配特定的外部記憶體裝置,或儲存硬體,而是利用GPU伺服器叢集中的可用DRAM與SSD空間,來作為額外KV快取記憶體。
這些軟體透過安裝在GPU伺服器的中介層軟體,橫跨多臺GPU伺服器,將閒置的DRAM與SSD空間,組成多階層、分散架構的外部KV快取記憶體池,作為原有KV快取記憶體的額外補充。
這類產品特點是利用既有GPU伺服器資源,無須搭配外部設備,還可以橫跨GPU叢集的多臺節點,平行處理上下文長度較長的Token,縮短Token產生時間。不過,這類產品擴展能力相對有限,僅限於使用GPU伺服器叢集自身的DRAM與SSD資源。
硬體式產品
須搭配個別廠商的專屬儲存平臺與設備,或是外部記憶體裝置,將外部裝置的儲存空間,透過網路掛載到GPU伺服器上,作為外部的KV快取儲存空間,並搭配安裝在GPU伺服器上的推論記憶體管理中介軟體,將LLM的KV快取需求發送到這些外部KV快取空間上,卸載GPU HBM的負荷。
這類產品又可依搭配的儲存媒體,區分為兩大類型:
第一類是搭配全快閃儲存裝置的產品,包括:WEKA結合WekaFS檔案系統的增強型記憶體網格(Augmented Memory Grid,AMG),VAST Data搭配自家儲存平臺的VUA(VAST Undivided Attention),焱融科技(YanRong)搭配YRCloudFile 分散式檔案系統的KV快取,Pliops搭配其XDP LightningAI儲存伺服器的KV快取平臺,還有華為整合在OceanStor A800高階儲存陣列的KV快取卸載功能等。另外,華為日前透露即將推出的AI SSD,也屬於這類硬體型KV快取卸載產品。
這些外部儲存平臺提供的KV快取記憶體空間,都是由NVMe SSD構成,儘管存取速度相對較慢,但可透過底層儲存平臺的分散式架構,提供PB等級的龐大擴展能力,還能透過SSD的非揮發儲存特性,持久地保存KV快取資料,構成可長期保存與重複利用的Token儲存庫。
第二類是搭配外接DRAM記憶體設備而構成的產品,例如,PEAK:AIO基於CXL技術的外接式KV快取記憶體設備,還有Enfabrica基於其ACF-S乙太網路/CXL交換器,所發表的的EMFASYS外接式記憶體解決方案。
這類產品的本體,是外接式DRAM記憶體裝置,也就是安裝了大量DRAM的機箱,透過CXL/RDMA網路掛載到GPU伺服器上,作為擴展的KV快取記憶體空間。優點是存取延遲比基於NVMe SSD的方案低了10倍以上,但擴展容量也相對較低,而且,由於DRAM的揮發性,這類方案不具備長期保存KV快取資料能力。
部署、效能與擴展性的權衡
LLM記憶體擴展是處於蓬勃發展階段的新興領域,不過1年多時間,就已問世將近20款解決方案與產品。
我們前面介紹的產品中,除了Sandisk的高頻寬快閃記憶體(HBF),華為AI SSD,以及PEAK:AIO與Enfabrica的外接式CXL記憶體池等產品仍在研發階段外,其餘多已實際可用。
這些產品的目的雖然相同,但效能、擴展能力與部署門檻相差很大。
就部署便利性來說,Mooncake、LMCache這些開源軟體,無疑是最便利的,無須任何配套設備,直接利用現有GPU伺服器即可部署,群聯aiDAPTIV+與華為AI SSD的部署門檻也很低,只需中介軟體加上幾臺SSD即可運作,適合對成本敏感的用戶。
部分產品則須搭配一整套多節點儲存叢集來運作,門檻相對較高,如WEKA、VAST Data等的解決方案,不過,這些搭配儲存叢集的方案,可憑藉底層的分散式檔案系統,提供PB等級的KV快取擴展空間,擴展能力遠勝其他產品型式。
至於效能方面,不同類型產品各有優劣,就KV快取部署位置來說,使用GPU伺服器內部資源(DRAM或SSD)的方案,存取延遲與頻寬大多優於透過網路介接的外接裝置,但部分外接裝置也能透過平行存取,匯聚出不遜於伺服器本機DRAM的龐大傳輸頻寬。
就儲存媒體形式來說,基於DRAM的方案,存取延遲與頻寬都優於基於NVMe SSD的方案,但SSD有著更低的成本與更大的容量與密度,所以,理想選擇是同時混用DRAM與SSD的分層架構,視存取需求移動資料位置,從而兼顧效能、成本與擴展性。也就是說,不同類型記憶體擴展方案,彼此並不互斥,而可並存。
至於Sandisk的高頻寬快閃記憶體(HBF)則獨樹一格。就部署來說,完全視Sandisk與GPU廠商間的合作而定,若合作不成,自然無法部署;若合作成功,則直接整合在GPU內部,用戶端直接可用。就效能與擴展能力,HBF傳輸頻寬相當於HBM(但存取延遲仍遜於HBM),高於所有外部形式擴展方案,不過,只能提供數TB等級的記憶體空間,遠低於外部擴展方案。
LLM記憶體擴展應用的擴散
隨著LLM持續發展,記憶體需求依舊持續增加。新一代模型的規模將會更大,混合專家模型(MOE)則須需大量各自掌握不同技能的專家單元,還有迅速發展中的多模式(Multimodal)模型,將文字、圖像、語音等訊息融合在一起,這些應用全都是記憶體密集型,將帶動LLM記憶體需求進一步提高,這也意味著,與GPU HBM記憶體供給能力之間的落差,將持續擴大。
我們認為,在LLM龐大的記憶體需求壓力下,除了擁有大型GPU運算設施的用戶,絕大多數用戶的GPU記憶體配置,都難以充分滿足新一代LLM應用所需,都會有一定程度的記憶體擴展與卸載需求。
另一方面,LLM記憶體卸載解決方案不僅發展非常迅速,且類型十分多樣化,從開源的純軟體解決方案,到搭配各式外部裝置的方案,可因應不同用戶環境。
儘管將記憶體卸載應用於LLM訓練,仍有一些疑慮,不過,用於推論的KV快取這個面向,已普遍被認為是可行做法,特別是隨著Nvidia Dynamo推理架構的推出,KV快取卸載可望出現標準的應用框架,並吸引更多廠商投入。
特別是在這三個產品領域:SSD、高效能儲存,以及外接式CXL記憶體池,都已有廠商先行推出整合LLM KV快取卸載應用的產品套件,例如:群聯與華為都有基於SSD的KV快取卸載產品,WEKA、VAST Data與華為則已為旗下高效能儲存平臺整合KV快取功能,還有PEAK:AIO與Enfabrica基於CXL記憶體池的KV快取卸載方案等,未來很可能形成一股潮流,讓KV快取卸載成為這幾類產品普遍支援的功能。
LLM記憶體的兩大擴展形式

LLM記憶體的擴展分為兩條技術路線:「內部擴展」與「外部擴展」,前者類似HBM,與GPU在晶片層次整合,但改用容量更高,成本更低的記憶體顆粒。如上圖中SanDisk的HBF高頻寬快閃記憶體,號稱可提供8到16倍於HBM的容量。
後者則是以GPU外部的記憶體資源,來卸載GPU HBM記憶體的工作負載。如下圖中群聯的AIDAPTIV+方案,就可以透過CPU DRAM與SSD,作為補充HBM容量的額外記憶體空間,並且構成階層式的記憶體應用架構。圖片來源/Sandisk,Phison
高頻寬快閃記憶體的基本架構
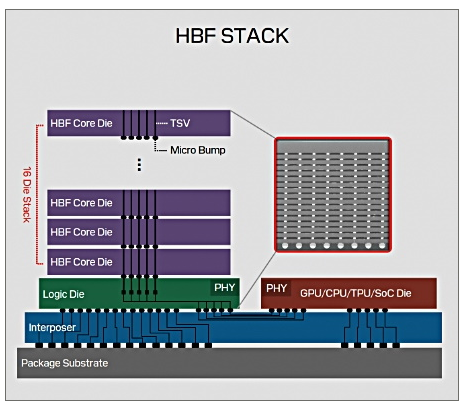
Sandisk發展的高頻寬快閃記憶體(HBF),是HBM的快閃記憶體版本,基本架構類似,由堆疊在邏輯晶片上的16層快閃記憶體裸晶構成,堆疊的晶片透過矽穿孔(TSV)互連,再透過中介板連接GPU。主要訴求是透過快閃記憶體較低的成本與更高的儲存密度,在與HBM相當的成本與空間下,提供8到16倍容量。圖片來源/Sandisk
結合外部儲存的KV快取卸載
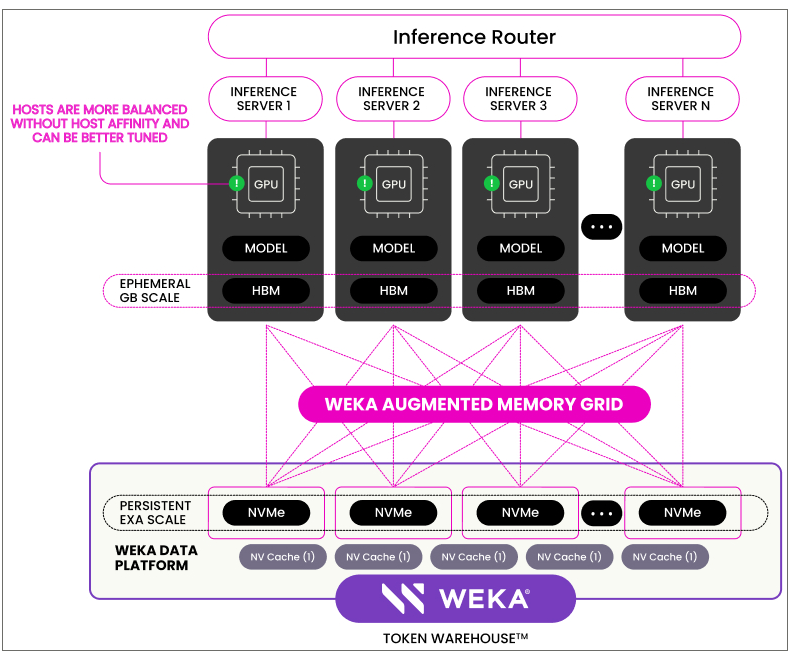
WEKA的增強型記憶體網格(AMG),是結合外部儲存設備的KV快取卸載解決方案,可將WEKA平行檔案系統平臺的NVMe SSD儲存空間,透過RDMA網路掛載到GPU伺服器,作為擴展的KV快取記憶體空間,從而加速推理工作。而透過GPUDirect直連與平行存取架構,WEAK宣稱AMG可提供不遜於GPU伺服器本機DRAM的頻寬與延遲表現。圖片來源/WEKA
LLM記憶體擴展與卸載的成效
我們以群聯的AIDAPTIV+為例,來看LLM記憶體擴展方案的成效。
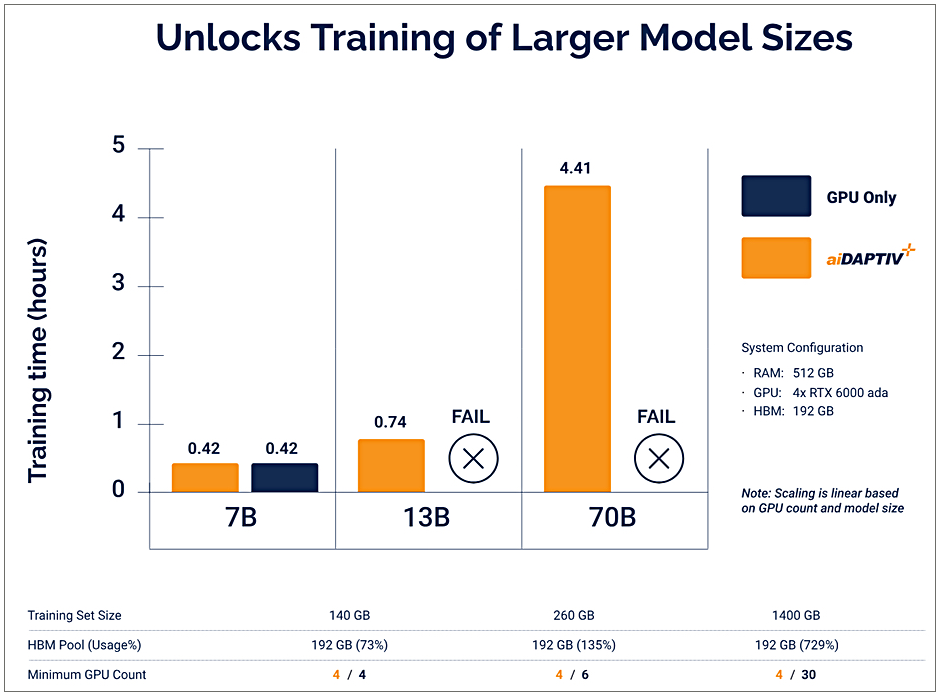
下方第1張圖表顯示,透過AIDAPTIV+將記憶體負載卸載到CPU DRAM與SSD後,可讓配備較少GPU與HBM/GDDR記憶體的系統,執行原本跑不動的模型訓練工作。
圖片來源-Phison
1套只配備4張GPU、只有192 GB HBM的伺服器,僅依靠GPU GDDR記憶體時只能執行7B模型(70億參數)的訓練,或是容納140 GB大小的訓練資料集,而透過AIDAPTIV+記憶體卸載功能,便能執行13B與70B模型訓練,並容納原本需要6張與30張GPU才能容納的260 GB與1,400 GB訓練資料集。
不過,使用AIDAPTIV+也需付出效能方面的代價,群聯另一份資料顯示,與作為對比的8節點、30張GPU卡、1,440 GB GDDR記憶體系統,透過AIDAPTIV+的記憶體卸載輔助,可讓只有4節點、16張GPU與512GB GDDR的系統,或單節點、4張GPU與128GB GDDR系統,執行同樣的70B模型與10萬個Token訓練工作,硬體成本各自節省了37%與85%,但訓練耗時也分別增加50%與5.5倍。也就是以更長的訓練時間,換取節省GPU記憶體資源。
下方第2張圖表則顯示,對於LLM推論作業,透過AIDAPTIV+將KV快取卸載到CPU DRAM與SSD,可以加速推論、並擴大Token長度。
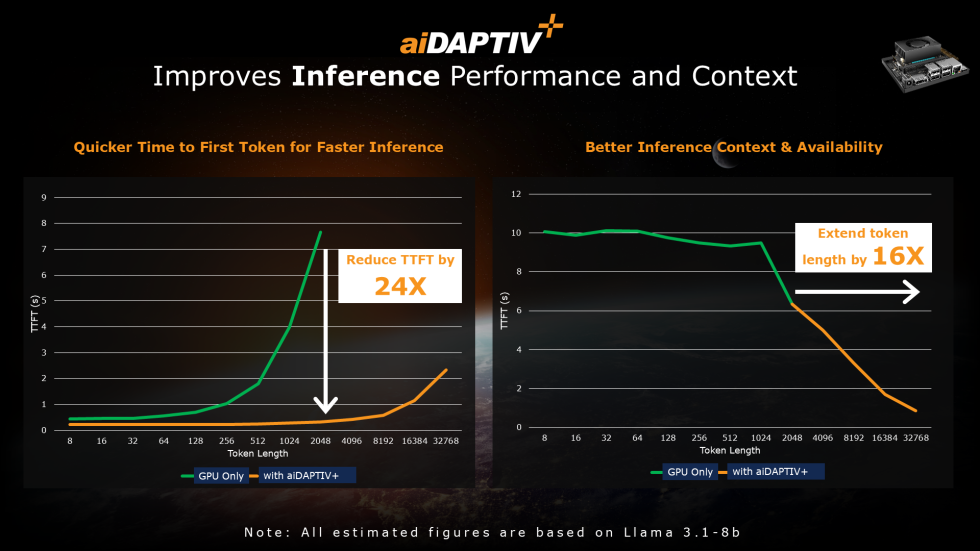
圖片來源-Phison
當測試系統單純依靠GPU執行推論時,受限於GDDR記憶體容量,KV快取只能保存有限的Token資料,當Token長度增加到512個以後,GPU產生第1個Token所需時間(TFTT)便顯著增加。而透過AIDAPTIV+,利用DRAM與SSD來存放更多KV快取時,Token長度即便增加到16384個,TFTT仍不致明顯增加,在2048個Token時的TFTT耗時能減少24倍。
此外,受限於GDDR容量,測試系統原本只能支援最大2,048個Token,而透過AIDAPTIV+的KV快取卸載,則能支援多達32,768個以上的Token,提高16倍。
