
The process of converting vast libraries of text into numerical representations known as embeddings is essential for generative AI. Various technologies—from semantic search and recommendation engines to retrieval-augmented generation (RAG)—depend on embeddings to transform data so LLMs and other models can understand and process it.
Yet generating embeddings for millions or billions of documents requires processing at a massive scale. Apache Spark is the go-to framework for this challenge, expertly distributing large-scale data processing jobs across a cluster of machines. However, while Spark solves for scale, generating embeddings itself is computationally intensive. Accelerating these jobs for timely results requires accelerated computing, which introduces the complexity of provisioning and managing the underlying GPU infrastructure.
This post demonstrates how to solve this challenge by deploying a distributed Spark application on Azure Container Apps (ACA) with serverless GPUs. This powerful combination allows Spark to expertly orchestrate massive datasets while ACA completely abstracts away the complexity of managing and scaling the compute. In this example, a specialized worker container is built that packages high-performance libraries like the NVIDIA RAPIDS Accelerator for Spark with an open source model from Hugging Face, creating a flexible and scalable solution.
The result is a serverless, pay-per-use platform that delivers high throughput and low latency for demanding AI and data processing applications. This approach provides a powerful template that can be readily adapted. For enterprise deployments seeking maximum performance and support, the architecture can be upgraded by replacing the custom-built worker with an NVIDIA NIM microservice.
Build a serverless, distributed GPU-accelerated Apache Spark application
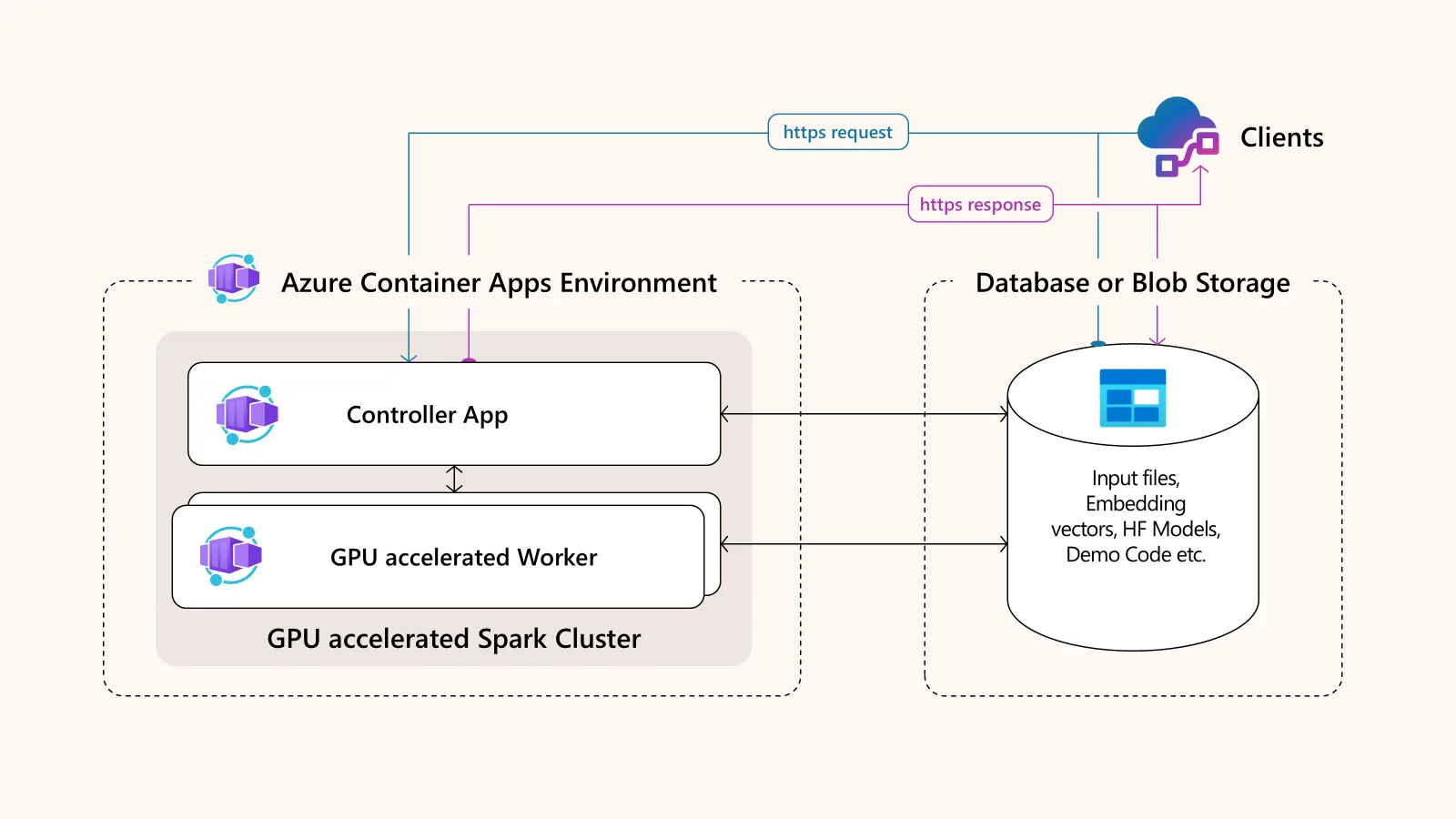
The architecture for this solution is straightforward yet powerful, consisting of just two main serverless container applications. Deployed in an Azure Container Apps Environment, these applications work in concert.
At its core, the architecture features:
- Apache Spark front-end controller (master) application: Runs on a CPU and orchestrates the work. It also provides an endpoint for submitting jobs, which can be a Jupyter interface for development or an HTTP trigger for production workloads.One or more Spark worker applications: These applications are GPU-accelerated and run on Azure Container Apps serverless GPUs. They perform the heavy lifting of data processing and can be automatically scaled out to handle a large number of requests.Shared data storage layer: Using Azure Files, this layer allows the controller and workers to share code, models, and data, simplifying development and deployment.
This setup is designed for both performance and convenience, enabling you to build and test complex distributed applications with ease.
Prerequisites
Before you begin, ensure that you have the following:
Step 1: Set up the Apache Spark controller application
First, deploy the Spark frontend application. The main goal of the controller application is to tell the Spark worker nodes what tasks to perform and host a web service to receive requests.
Build container images
This application has two Docker containers that work together, one for Spark (master part) and one for the frontend (interact). The Spark container has the SPARK_LOCAL_IP environment variable set to 0.0.0.0 to ensure it can accept connections from worker nodes on any network.
The frontend container has a SPARK_MASTER_URL variable, which is set to the application URL using port 7077. In addition, it has an APP_MODE environment variable that allows you to switch how you interact with the Spark master. You can use Jupyter for development and debugging, and HTTP/HTTPS for API mode.
You can add your customization to the dockerfile.master and dockerfile.interact provided in the GitHub repository, build the container image, and push it to the Azure Container Registry (ACR).
Create the controller application
Now create the controller application based on the two images (Spark master and client interaction) from the ACR. To use GPU acceleration, create a GPU workload profile based on available NVIDIA GPU sizes. Note that NVIDIA A100 and NVIDIA T4 GPUs are currently supported by Azure Container Apps.
Create an Azure Container Apps environment with an Azure Virtual Network with public access and attach the GPU workload profile to it. This environment should add Azure File Share as a volume mount for storing input data, writing output results, and sharing files between the Spark controller and worker nodes.
Configure networking and scaling
Configure the application to accept public web traffic on port 8888 for its REST API endpoint by enabling ingress and setting the port number. You must also add an additional TCP port 7077 to allow the Spark nodes to communicate with each other. For debugging, you can optionally expose the Spark UI on other ports, such as 8080. This controller application must always be set to a scale of one.
Step 2: Deploy the GPU-accelerated Spark worker application
The next step is to deploy the Spark worker application. The worker application will connect to the master and is responsible for performing the actual data processing and AI model inference. Unlike the single controller, you can deploy many workers that will automatically connect to it.
Build the worker container image
This particular example uses Dockerfile.worker to build a worker container that packages a foundational NVIDIA base image, the NVIDIA RAPIDS Accelerator for Apache Spark library and application code that loads a pretrained open source embedding model (all-MiniLM-L6-v2) from Hugging Face. The RAPIDS Accelerator is a library that provides drop-in acceleration for Spark with no code change, leveraging GPUs to dramatically speed up data processing and traditional machine learning tasks.
You can then push this worker image to your ACR, ready for deployment. It should share the same Azure Virtual Network and storage as the controller application.
Note that while this example shows how to build a worker container with a Hugging Face embedding model, for production deployments you can use NVIDIA NIM microservices. NVIDIA NIM microservices supply pre-built, enterprise-supported, production-grade containers featuring state-of-the-art AI models and would offer the best inference performance on NVIDIA GPUs.
For example, NVIDIA NIM microservices are available for powerful embedding models like the NV-Embed-QA family, which is purpose-built for high-performance retrieval and question answering tasks.
Create the worker application
Create the worker application using the worker container image built, as outlined in the previous section. Deploy the application within an Azure Container Apps (ACA) environment using a serverless GPU workload profile. ACA automatically handles the setup of NVIDIA drivers and the CUDA toolkit, so you can focus on your application code instead of the infrastructure.
Automatic scaling
Unlike the controller (which has a fixed scale of one), the number of worker instances is dynamic. When a large data processing job starts, ACA can automatically scale the number of worker instances based on the load. It can rapidly scale from zero to many GPU instances in minutes to meet demand and, crucially, scale back to zero to avoid paying for idle resources. This approach allows for significant cost savings compared to traditional, always-on clusters.
The worker application doesn’t have Ingress. Everything is based on internal communication.
Step 3: Run the distributed text-embedding job
With the Spark controller and worker applications running, your serverless GPU-accelerated Apache Spark cluster is active and ready to process data. In this example, product description data is processed from a SQL Server, text embeddings are generated using the Hugging Face model accelerated by the worker GPUs, and the results are written back to the SQL Server database. The method for submitting the job differs depending on the controller APP_MODE environment variable, as described in Step 1.
Connect using Jupyter (development mode)
If the controller application environment variable APP_MODE is set to jupyter you can navigate to the public URL of your controller application, which will automatically have a Jupyter notebook connected to your shared Azure File storage. From the notebook, you can create a Spark session, connect to your SQL Server database through JDBC, and execute the embedding job. For an example, see the spark-embedding.py Jupyter notebook in the NVIDIA/GenerativeAIExamples GitHub repo.
You can also monitor the job’s progress through the standard Spark UI, where you will see the workers being utilized and CUDA being used for processing on the serverless GPU.
Trigger using HTTP (production mode)
To enable production mode, set the controller APP_MODE environment variable to trigger, which exposes a secure HTTP endpoint for automation. The embedding job can then be initiated through a scheduled Bash script or directly from a database using SQL Server external REST endpoint feature.
Once triggered, the controller fully automates the end-to-end workflow. This workflow includes reading the data from your SQL table, distributing the processing to the GPU workers, and writing the final embeddings back to your destination table in a robust, hands-off manner.
For an example of triggering a job in production mode, see the trigger-mode.py file. Note that you will need to replace the placeholder URL with the actual public URL of your deployed controller application.
Get started with serverless distributed data processing
By deploying a custom, GPU-accelerated Apache Spark application on Azure Container Apps serverless GPUs, you can build highly efficient, scalable, and cost-effective distributed data processing solutions. This serverless approach removes the burden of infrastructure management and enables you to dynamically scale powerful GPU resources to meet the demands of your AI workloads.
The ability to move from an interactive Jupyter-based development environment to a production-ready, trigger-based system within the same architecture provides immense flexibility. This powerful combination of open source tools and serverless infrastructure offers a clear path to production for your most demanding data challenges. You can further optimize by adopting NVIDIA NIM microservices for enterprise-grade performance and support.
To get started deploying the solution, check out the code available through the NVIDIA/GenerativeAIExamples GitHub repo. To learn more and see a demo walkthrough, watch Secure Next-Gen AI Apps with Azure Container Apps Serverless GPUs.
