
AI agents now solve multi-step problems, write production-level code, and act as general assistants across multiple domains. But to reach their full potential, the systems need advanced reasoning models without being prohibitively expensive.
The NVIDIA Nemotron family builds on the strongest open models in the ecosystem by enhancing them with greater accuracy, efficiency, and transparency using NVIDIA open synthetic datasets, advanced techniques, and tools. This enables the creation of practical, right-sized, and high-performing AI agents.
Llama Nemotron Super 49B v1.5, the latest version released Friday, brings significant improvements across core reasoning and agentic tasks like math, science, coding, function calling, instruction following, and chat, while maintaining strong throughput and compute efficiency.
It has now topped the Artificial Analysis Intelligence Index leaderboard.
In this blog post, we’ll cover the accuracy and inference performance of the latest NVIDIA Nemotron model, training methodology, data transparency, architectural optimizations, and deployment options.
Llama Nemotron Super v1.5 tops Artificial Analysis leaderboard
The new model was built with the same methodology as the original Llama Nemotron Ultra v1, but has undergone further refinement and post-training by using additional high quality reasoning data.
This model achieves best-in-class performance across a number of reasoning and agentic tasks, topping the Artificial Analysis Intelligence Index leaderboard, which measures accuracies across MMLU-Pro, GPQA Diamond, Humanity’s Last Exam, LiveCodeBench, SciCode, AIME, and MATH-500.

Evaluated by a third party on a suite of industry-standard benchmarks for reasoning, and instruction and function-calling tasks, Llama Nemotron Super v1.5 outpaces open models across advanced math, coding, reasoning, and chat metrics—firmly placing it as the top model in the 70-billion parameter range.

Beyond just being best-in-class in reasoning and agentic capabilities, the model also achieves significantly higher throughput by leveraging post-training methods to improve throughput performance (Neural Architecture Search).

The result is a highly performant model that fits on a single NVIDIA H100 Tensor Core GPU, letting developers build more effective and more efficient agentic systems.
Built for reasoning and agentic workloads
Building Llama Nemotron Super v1.5 required the combination of several key NVIDIA technologies:
Llama Nemotron post-training open dataset
This dataset was created entirely through synthetic data generation using advanced reasoning models like Qwen3 235B and DeepSeek R1 671B 0528. It allowed our team to create over 26 million rows of high-quality function calling, instruction following, reasoning, chat, math, and code data.
Releasing the data allows us to be transparent about exactly what went into training our models, which can help developers and enterprises be confident in their selection of the Llama Nemotron Super v1.5 as the engine for their agentic systems.
Beyond transparency, releasing the dataset allows developers to build their own models without expending the effort and time required to produce a high-quality dataset—thereby lowering the barrier to entry to produce highly-capable new models.
This dataset is now available on Hugging Face, and the dataset card provides a more detailed breakdown.
Post-training process
As shared in this previous blog post, the post-training pipeline looks as follows:
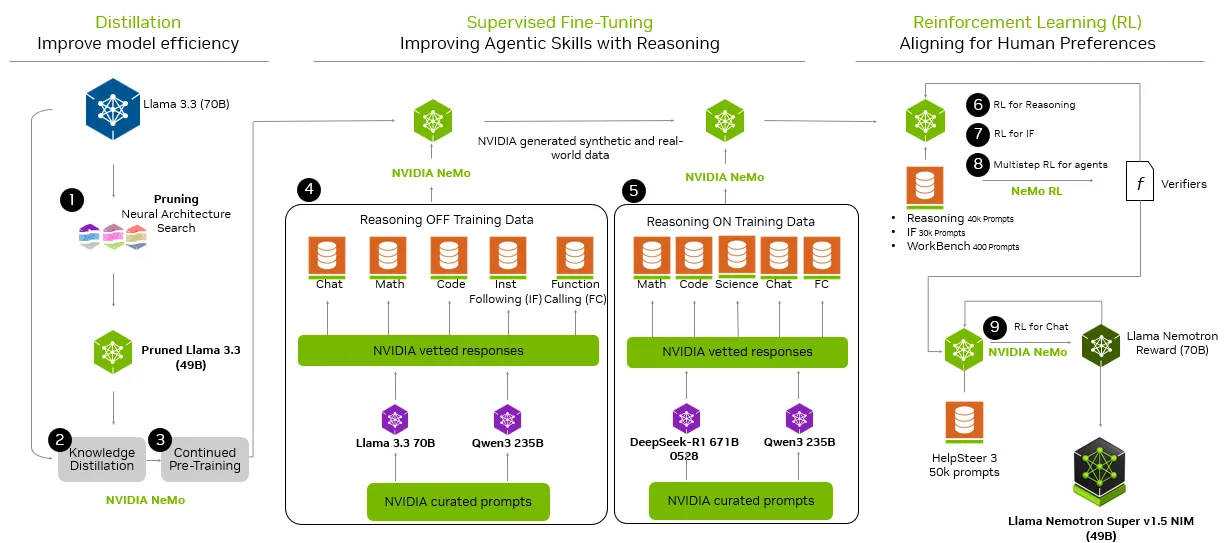
The team leveraged reinforcement learning to push the model to the limits and achieve the reasoning capabilities outlined above. The model underwent a number of post-training pipelines, all tailored for the desired capability enhancements. Aside from Supervised Fine-Tuning (SFT), the model also underwent:
- RPO (Reward-aware Preference Optimization) – leveraging best-in-class NVIDIA Reward Models for chat capabilities DPO (Direct Preference Optimization) – for tool-calling capabilitiesRLVR (Reinforcement Learning with Verifiable Rewards) – for instruction-following, math, science, and more
The comprehensive post-training pipeline ensured that the model was ideally trained for each capability, further pushing the boundaries of reasoning accuracy.
The teams also used NeMo Skills to evaluate and validate the model checkpoints, allowing for tight iteration and research cycles, as well as reproducibility.
Llama Nemotron Super v1.5 available as a NIM
Llama Nemotron Super v1.5 will soon be available as an NVIDIA NIM microservice for rapid, reliable deployment on your preferred NVIDIA accelerated infrastructure. You can deploy it with a few simple commands and immediately integrate private, OpenAI API-compatible endpoints to level-up AI agents and reasoning apps. Plus, the high-performance Llama Nemotron Super inference autoscales on demand.
Get started with Llama Nemotron Super v1.5
The Llama Nemotron Super v1.5 model delivers powerful reasoning capabilities while remaining compute-efficient. It’s ready to power agentic applications from individual developers, all the way to huge enterprises.
You can get started by trying out the model on build.nvidia.com. Once you’ve had some time to test the model, you can download the checkpoint from Hugging Face or follow the model card and run the model through the instructions provided there.
This post originally ran July 25. Updated July 29 with leaderboard information.
