
原来,Scaling Law在32年前就被提出了!
不是2020年的OpenAI、不是2017年的百度,而是1993年的贝尔实验室。
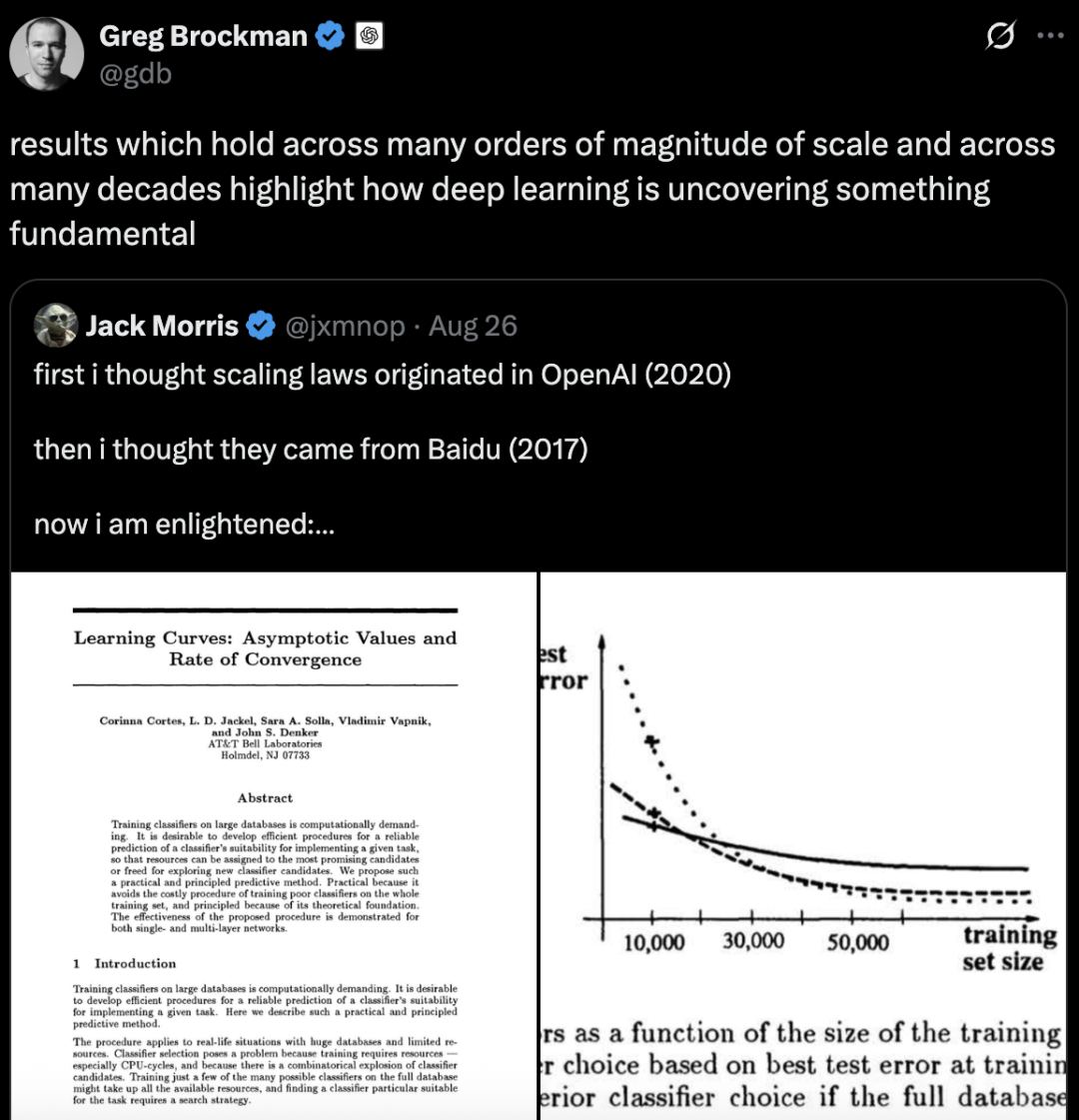
在一篇名为《Learning Curves: Asymptotic Values and Rate of Convergence》的文章里提出一种预测方法:
训练误差和测试误差随训练规模增加,都会收敛到同一个渐近误差值,这种收敛符合幂律形式。
通过这种方法,研究人员可以预测模型在更大数据集上的表现。

这和现在大家常提的Scaling Law几乎一致:
在合理的范围内,通过简单地增加模型参数量(N)、训练数据量(D)和计算量(FLOPS,C),可以以一种可预测的、平滑的方式显著提升模型性能。
而1993年的这篇论文来头也不小,作者一共5位,其中包含了支持向量机的提出者Vladimir Vapnik和Corinna Cortes。

为省算力提出预测曲线
这篇论文的研究初衷是为了节省训练分类器(classifiers)的计算资源(果然啥时候都缺算力)。
当时的机器学习算法能实现将输入数据分配到某个类别里,比如输入一张手写数字的像素点,判断它是不是某一个数组。
为了让分类器更可靠,往往需要使用大规模数据库训练。但是研究人员并不确定分类器是否适合给定任务,因此开发高效的预测程序非常有必要。
这项研究就是提出了一种预测方法,先在中等规模的数据集上训练,然后通过提出的学习曲线建模外推,预测其在大数据集上的表现。这样就不用对分类器进行完整训练,从而节省计算资源。
它首先在几个中等规模训练集上分别计算测试误差、训练误差,然后他们发现,随着训练集的规模变大,训练误差和测试误差都会收敛到一个相同的渐近值a,这个指数a在0.5-1之间。
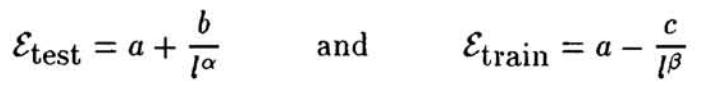
然后变换为对数线性关系,在对数坐标下得到两条直线。

通过拟合这两条直线能得到a,b,α。
将估计出的幂律曲线外推到更大的训练集规模上(比如60000),预测分类器在完整数据上的误差。
实验结果表明,在线性分类器(布尔分类任务)中预测非常准确。
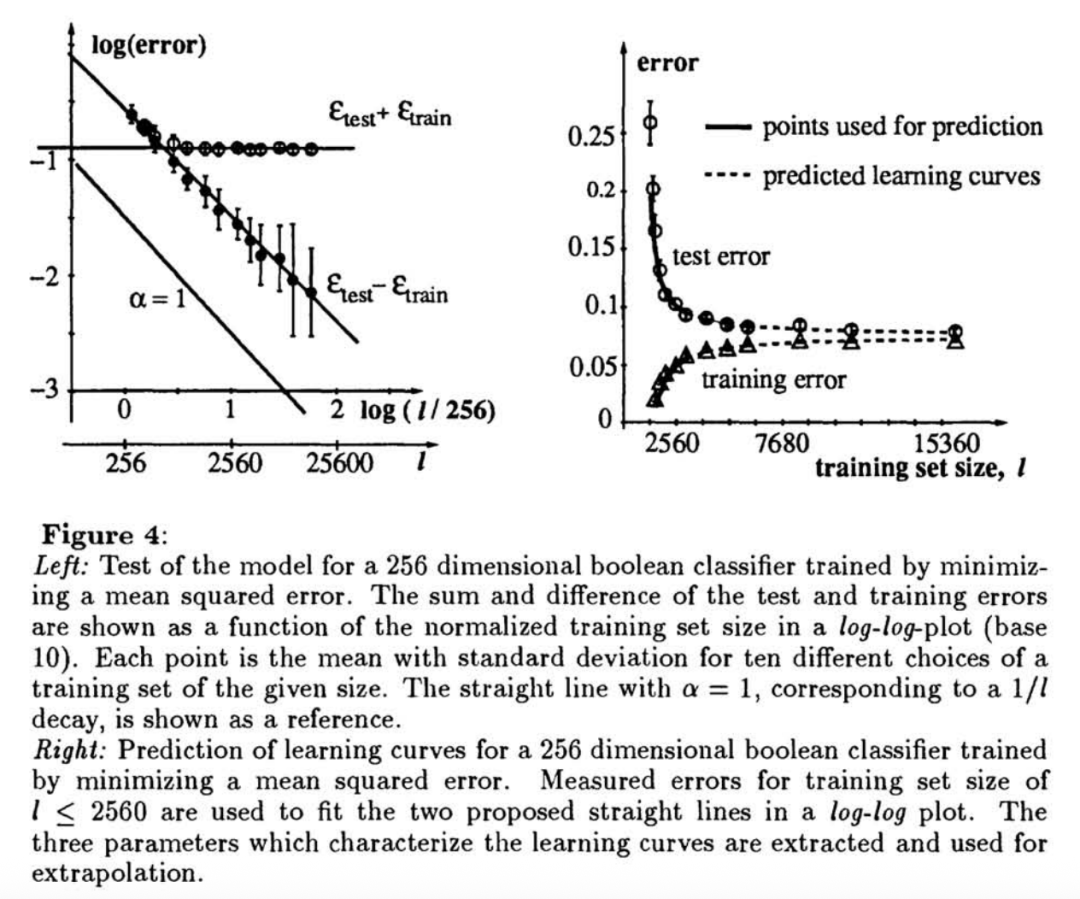
在多层神经网络(如LeNet)中,即便在任务不可实现(non-realizable)的情况下,外推结果也能很好地预测大规模训练的最终表现。
比如仅用12000样本训练,就能预测新CNN在60000样本上会优于旧CNN。
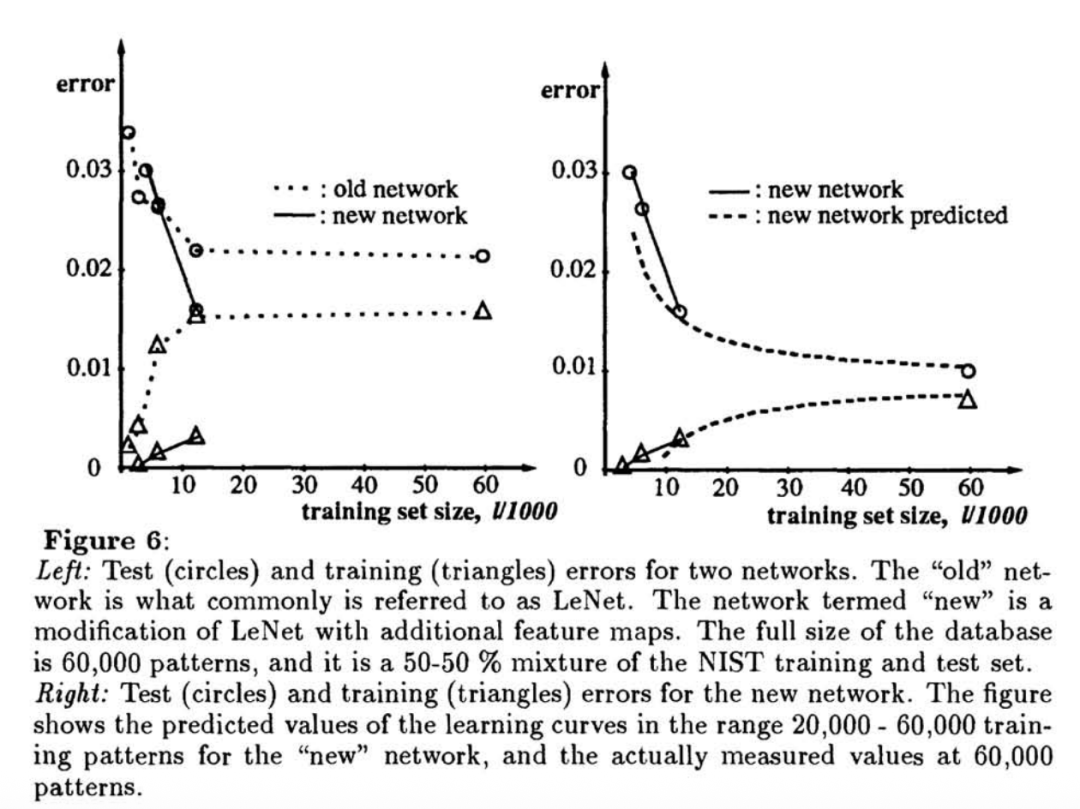
此外作者还发现,任务越困难,渐近误差越高,收敛速率越小,即学习越慢。
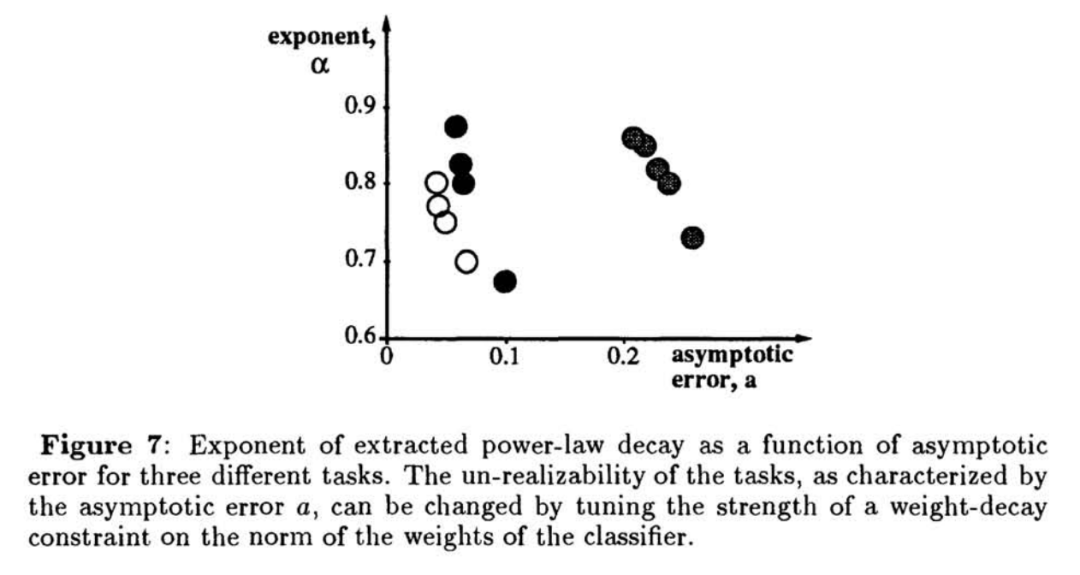
这个理论放在当时可以用来淘汰差的模型,将有限的计算资源放在更值得训练的模型上。
作者也是支持向量机提出者
最后不得不提一下这篇研究的几位作者。
首先来看Vladimir Vapnik,他因在统计学习理论和支持向量机方面的贡献而闻名。

他于1958年在乌兹别克国立大学获得数学硕士学位,并于1964年在莫斯科控制科学研究所获得统计学博士学位。1961年至1990年期间,他一直在该研究所工作,并担任计算机科学研究部门的负责人。
Vapnik与Alexey Chervonenkis在1960年至1990年间共同开发了Vapnik-Chervonenkis理论(也称为VC理论)。该理论是计算学习理论的一种形式,旨在从统计学角度解释学习过程。
它是统计学习理论的基石,为学习算法的泛化条件提供了理论基础,并量化了模型的复杂性(通过VC维)。VC理论在无需定义任何先验分布的情况下,为机器学习提供了一种更通用的方法,与贝叶斯理论形成了对比。
同时Vapnik也是支持向量机(SVM)的主要发明者。这是一种监督学习模型,用于数据分类和回归分析。1964年,Vapnik和Chervonenkis首次提出了原始的SVM算法。
1990年代,Vapnik加入贝尔实验室开始进行机器学习方面的深入研究。在1992年他和Bernhard Boser、Isabelle Guyon提出了通过应用“核技巧”(kernel trick)来创建非线性分类器的方法,极大地扩展了SVM的应用范围,使其能够处理非线性可分问题。
1995年Vapnik和Corinna Cortes提出了软边距的非线性SVM并将其应用于手写字符识别问题,因为性能表现出色,这篇论文引发广泛关注,也成为机器学习发展中的一块重要基石。

他撰写的《统计学理论的本质》也是机器学习领域的必读著作之一。
以及他2014年还给Facebook当过顾问。

另一位重要作者是Corinna Cortes。她现在是Google Research纽约分部的副总裁,负责广泛的理论和应用大规模机器学习问题研究。
她于1989年在哥本哈根大学尼尔斯·玻尔研究所获得物理学硕士学位。随后,她于1993年在罗切斯特大学获得计算机科学博士学位。
在加入Google之前,Cortes在贝尔实验室工作了十多年。
2022年她被任命为ACM Fellow,以表彰她对机器学习领域的贡献。

其余几位作者分别是:L. D. Jackel、Sara A. Solla和John S. Denker。
其中John S. Denker还和LeCun在手写识别上合作过多篇论文,也都是机器学习经典大作了。


而他本人也相当全能,涉猎领域包括机器学习、系统安全、好莱坞特效、电子游戏和视频游戏等,完成了很多开创性工作。还曾在加州理工学院创建并教授“微处理器设计”课程(硅谷之所以成为硅谷,和当时美国高校中开始推行芯片设计课程有很大关系)。
甚至,他还是一个飞行员,是FFA的航空安全顾问,并写了一本对飞行原理解释透彻的行业教科书。
Denker还曾于1986-87年担任加州大学圣巴巴拉分校理论物理研究所的访问教授。 他以幽默感和“原型疯狂科学家”的形象而闻名,他的一些事迹甚至在一些电影中有所体现。

One More Thing
值得一提的是,卷积神经网络和支持向量机都诞生于贝尔实验室。它们之间过一段“分庭抗礼”的时期。
在深度学习兴起之前,CNN因为“黑盒”以及需要大规模训练,一些研究者对其持有保留态度;相比之下支持向量机的理论清晰、易于收敛到全局最优解。到底谁是正确路线?一时争论不休。
1995年,Vapnik还和当时的上司Larry Jackel以一顿豪华晚餐打赌,到2000年时,人们能不能解释清楚大型神经网络为什么在大规模训练中表现很好?
Vapnik觉得不能。2000年他赢了;随后他们又赌,再过5年结果如何?这一次Vapnik错了:
在2005年任何头脑清醒的人都不会再用和1995年时完全相同的模型了。
这场赌局,LeCun是见证人。

论文地址:
https://proceedings.neurips.cc/paper/1993/file/1aa48fc4880bb0c9b8a3bf979d3b917e-Paper.pdf
参考链接:
[1]https://x.com/gdb/status/1962594235263427045
[2]https://yorko.github.io/2022/vapnik-jackel-bet/
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
 扫码添加小助手,发送「姓名+公司+职位」申请入群~
扫码添加小助手,发送「姓名+公司+职位」申请入群~
🌟 点亮星标 🌟
内容中包含的图片若涉及版权问题,请及时与我们联系删除
