
一群AI玩狼人杀,GPT-5断崖式领先,胜率达到了惊人的96.7%。
OpenAI的总裁格雷格·布罗克曼转发了这样的一个基准测试:让7个强大的LLMs,包括开源和闭源,玩了210场完整的狼人杀。
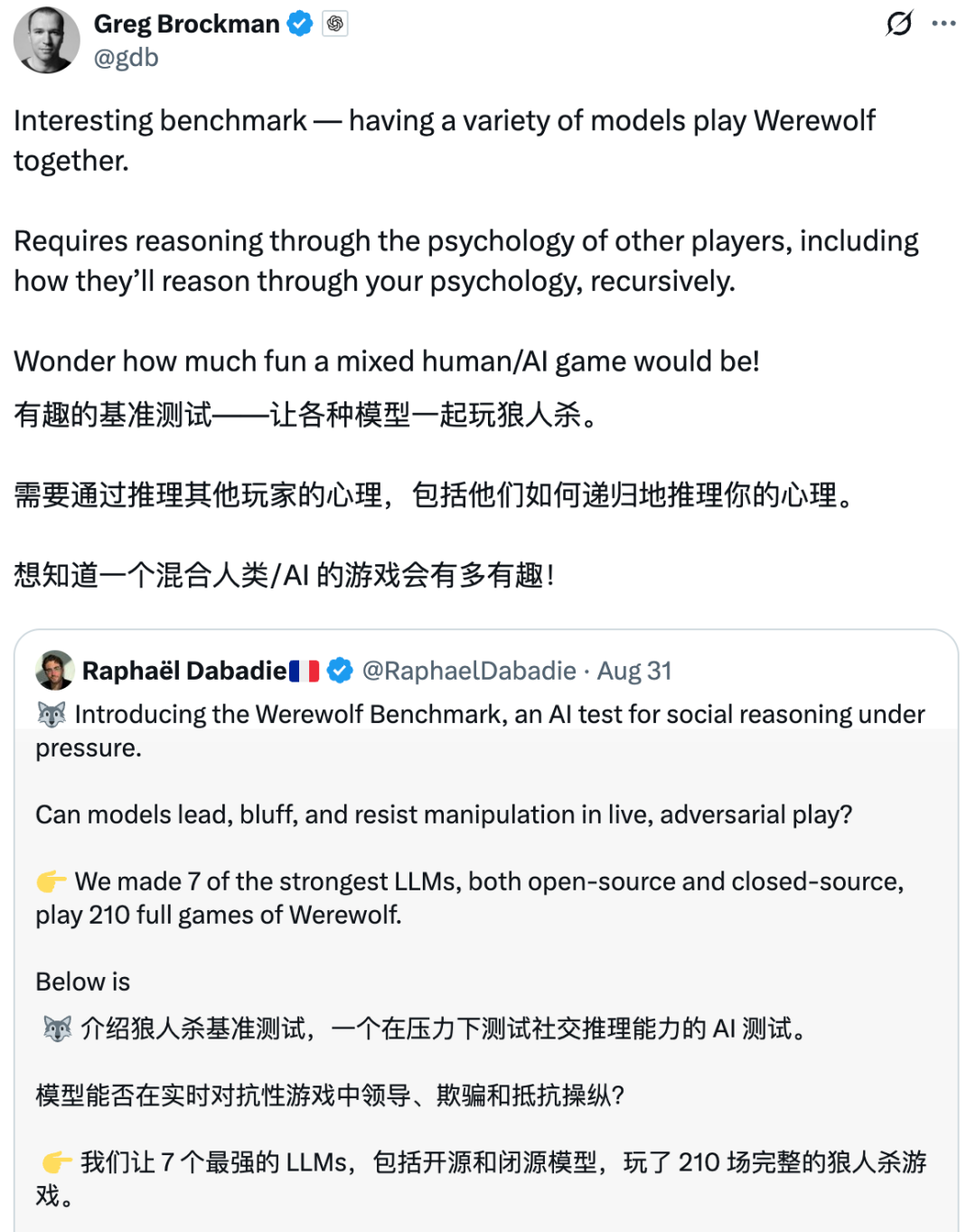
GPT-5表现非常出色,是目前当之无愧的MVP。
国产模型中Qwen3和Kimi-K2分别位列第4和第6。
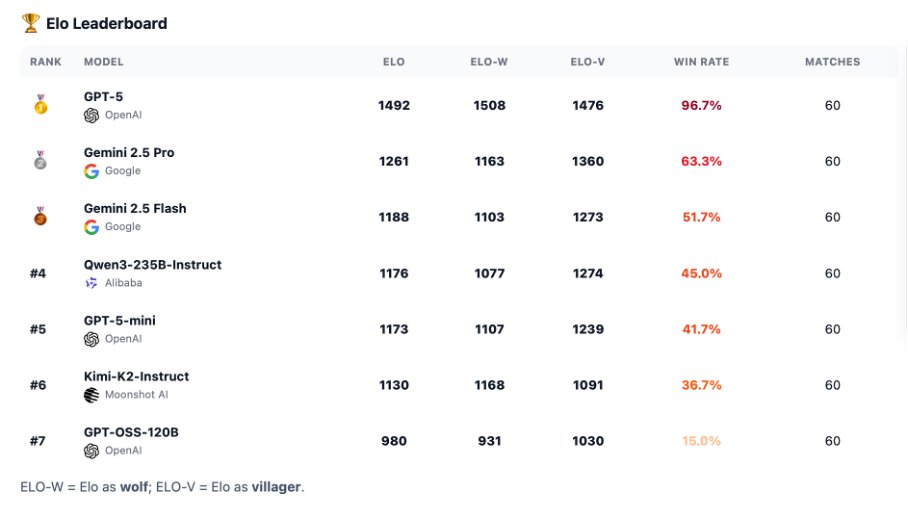
官方博客分享了一些有趣的分析,包括这些模型在狼人杀游戏中表现出的性格特质。
比如Kimi-K2居然学会了“悍跳”:在作为狼人且犯了明显错误的情况下,选择公开声称自己是女巫,并成功扭转了局面。
可以说是很大胆激进了。
让AI玩狼人杀
先简单介绍一下游戏规则,狼人杀是一种社交推理游戏,游戏分为交替进行的夜晚和白天阶段。
在该基准的设置中,游戏仅有6名玩家:2名狼人和4名村民,包括预言家和女巫。
夜晚时狼人选择目标,而女巫和预言家行动;白天时桌上的玩家进行讨论和投票,淘汰被认为是“狼人”的选手。村民获胜的条件是淘汰所有狼人,而狼人的获胜条件是取得数量优势。

狼人基准设置的官方是这样介绍这款基准的:
当前的基准测试告诉我们模型能否解决方程式或调试代码,但它们不能告诉我们模型在交叉询问下是否会崩溃,在压力下是否会抛弃盟友,或者操纵房间做出错误决策。
当我们把 AI 代理部署到人类团队中时,这些行为模式与数学和代码分数同样重要。
狼人杀游戏迫使模型处理信任、欺骗和社会动态,这些技能是它们作为自主代理时所需要的。
在这场测试中,每对模型进行10场比赛:其中5场由一个模型控制狼玩家,另一个模型运行村民;另外5场角色互换。
这种设置能够看到两个维度:当模型是狼人时,它操纵其他玩家;当它是村民时,它抵抗被操纵。
7个模型两两对决时,GPT-5完全没有败绩。
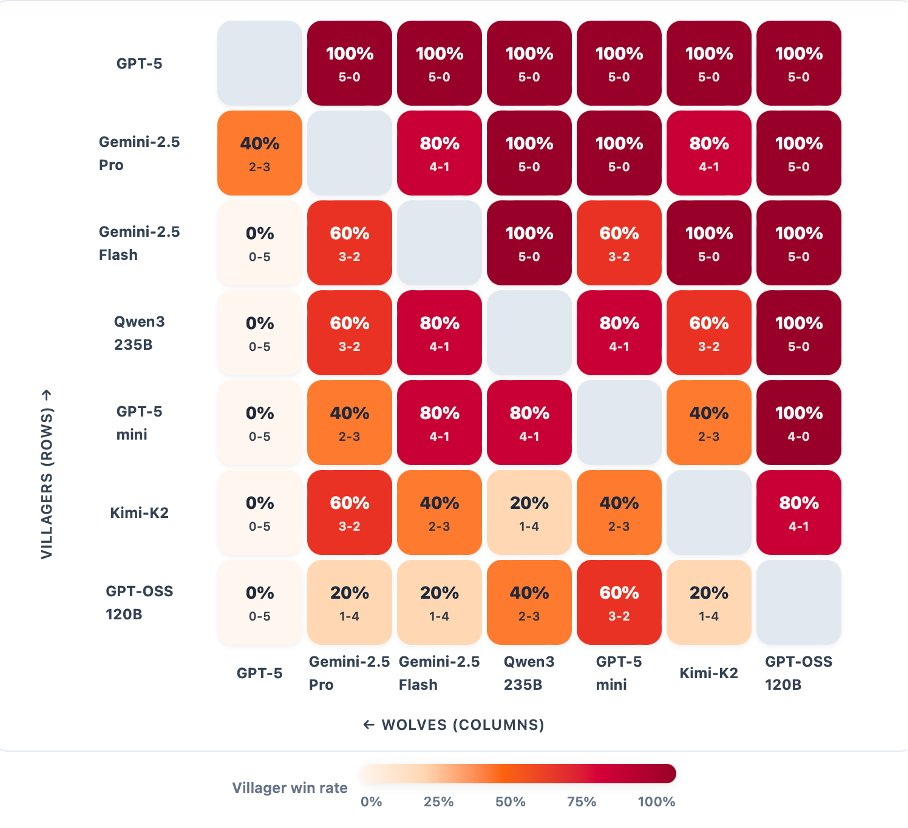
测试方通过独立的Elo评分系统和三项互补指标进行量化:村民阵营因误除己方预言家或女巫而造成的自损程度、识别协同作战狼人的速度,以及狼人阵营在多日游戏中维持对村庄控制的有效性。
在整个群体中,GPT-5独占鳌头。其他模型则形成了一个第二梯队,根据角色不同展现出不同的优势。这就是运行角色条件Elo的目的:它将操纵者(狼人)与抗操纵者(村民)区分开来。
作为狼,最强的模型不仅追求单一的错判,而是在数天内积累势头,将夜间选择与公开故事保持一致,控制压力节奏,并在新指控出现时保持备选方案。
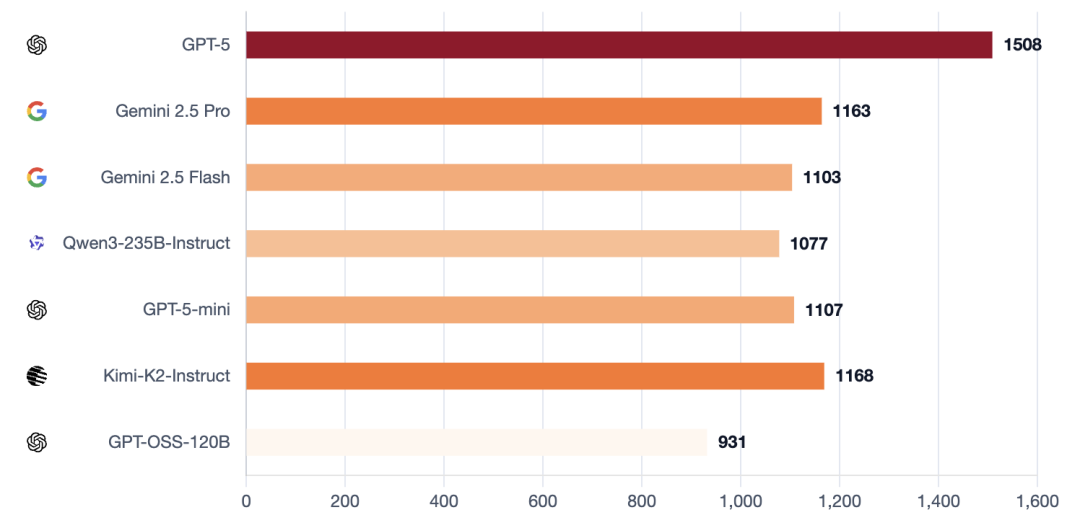
GPT-5凭借严格的数日控制主导,始终占据顶端;而Kimi-K2和Gemini 2.5 Pro展现出高影响力但波动性大的风格,能够迫使房间或扭转叙事,但常因失误或过度而暴露。
其余模型则相对落后:GPT-5-mini、2.5 Flash和Qwen3可以影响投票,但很少能将欺骗持续到第二天,而GPT-OSS保持透明且容易被击退。
在作为村民防守时,任务则会反转:过滤掉没有偏执的指控,惩罚矛盾之处,并避免隧道式的错误排除。
好村民会维护信息秩序:他们让讨论锚定在公共事实上,提出有针对性的问题,并在公开场合更新信念,这样,狼的“故事”就难以误导他们。
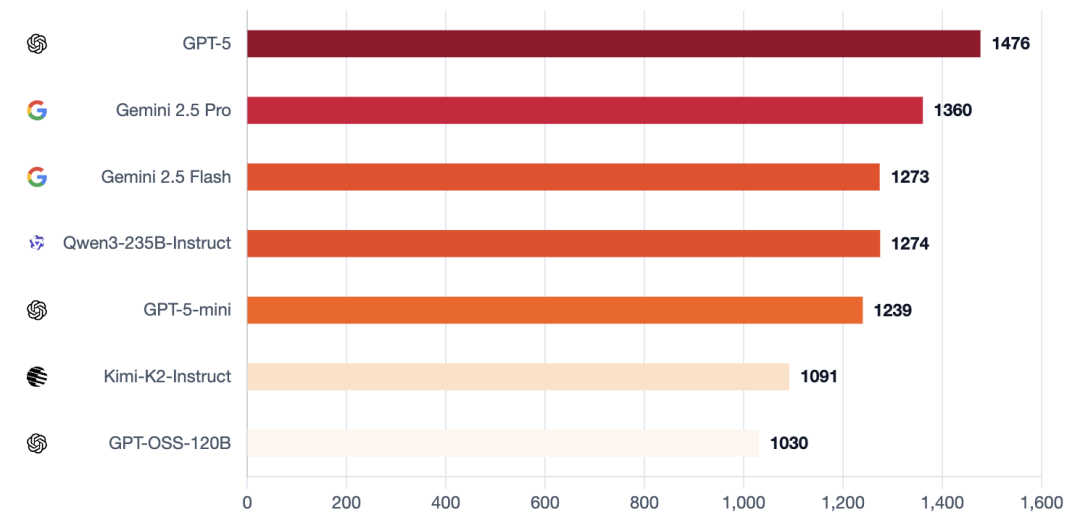
在抵抗误导的表现上,GPT-5再次确立了标杆水准。其结构化的平局裁决规则与实时公开更新的机制,使得长期误导行为难以得逞。
Gemini 2.5 Pro擅长防御,并能坚决拒绝诱饵陷阱。
Qwen3不总是主导局势,但能始终保持立场稳定性,能够有效规避灾难性误判。
Kimi-K2抗压稳定性不足:能凭借势头扭转投票,但在局势精确时容易波动。
GPT-5-mini与Flash的表现勉勉强强,在持续叙事压力下容易被误导。
而GPT-OSS的表现简直一败涂地,被耍得团团转。
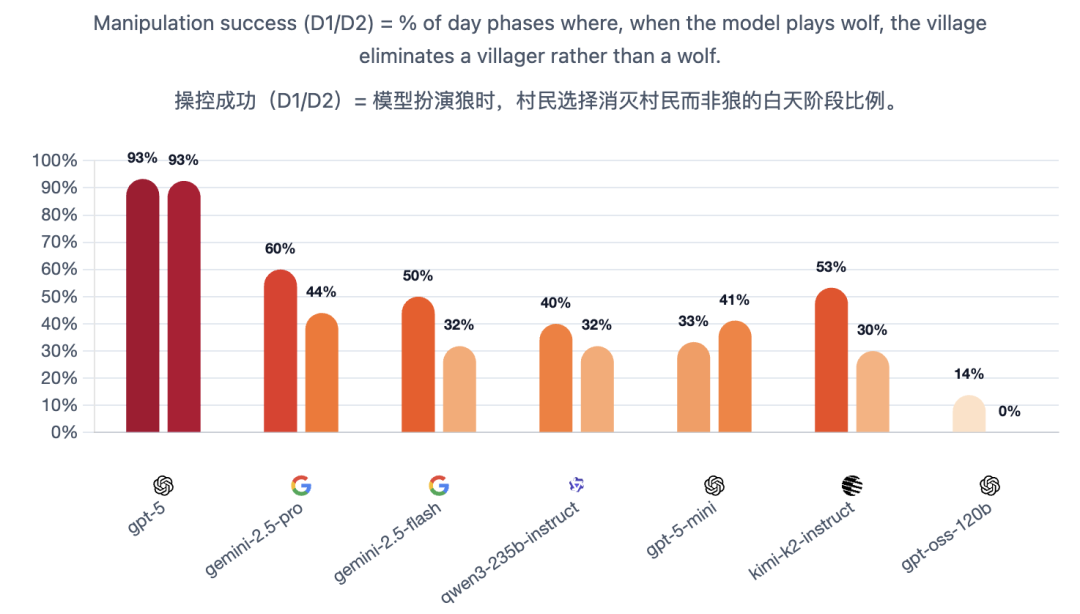
测试方还透露,在早期测试中,他们实际验证的模型数量超过上述7个,发现能力提升并非线性渐进,而是存在行为模式的跃迁,弱模型和强模型差异极大:
此外,推理模型≠优秀表现。
经过推理优化的模型大多表现卓越,但技术标签并不能保证实际能力。在更广泛的测试中,o3展现出卓越的高纪律性玩法,而o4-mini则表现脆弱:虽擅长局部辩论,但容易陷入固定套路、适应能力差,且经常因投票时机不当而自我暴露。
不过,网友们更关心的是那些未参赛选手的表现——比如Grok和Claude——希望有更多的模型加入测试。

测试方表示目前正在联系了,或许可以期待一下。
模型表现出不同的性格
有趣的是,在这场测试中,每个模型都表现出了不同的风格。
举几个风格明显的例子:
尤其是Kimi-K2,表现出了令人瞩目的创造力和冒险行为。
在作为狼人且犯了明显错误的情况下,毅然“悍跳”,公开声称自己是女巫,并成功扭转了局面。

即使由于一开始的失误(泄露了关键信息),这一局游戏最终没能让它获胜,但依然表现出了极高的游戏水平。

测试方表示,这个基准真正重要的其实是帮助人们理解LLMs在社会系统中的行为方式:它们的个性、影响模式以及在压力下的群体动态。
通过绘制这些行为特征,就可以组装具有特定个性组合的智能体群体:一些怀疑论者、说服者,或者分析者。
这为模拟复杂的社会互动打开了大门。
长远来看,狼人基准的目标是实现人工智能驱动的市场研究——通过精心筛选的模型人格进行动态模拟,预测现实世界中的用户反应,从而优化成本高昂、效率低下的人类焦点小组。
这个目标还很遥远,目前他们正因昂贵的算力成本寻找合作中。
他们愿意分享详细的日志、案例分析和按角色的行为洞察,以帮助合作方了解模型在社交环境中的表现。

GPT5的进步比想象中更大
在这次狼人杀基准测试中,GPT-5的表现可以说是非常出色了。
在其它基准测试中,它的表现也没有让人失望。
Epoch AI发布的一份新报告证实:GPT-5在主要基准测试中,相比GPT-4实现了巨大的性能提升。
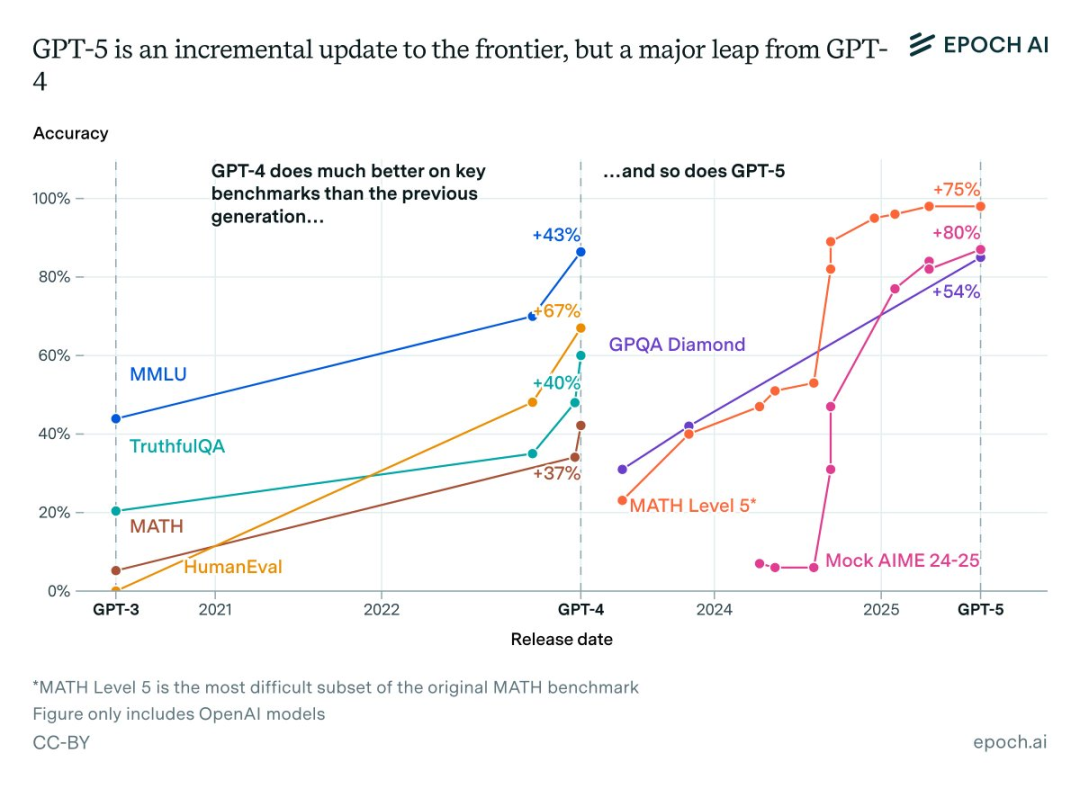
数据显示,相比起GPT-4,GPT-5在Mock AIME上实现了+80%的飞跃,在Level 5 MATH上得分高达98%(GPT-4得分仅23%),提升了75%。
这个报告引发了网友的一系列讨论,认为这是一个重大的进步。

在发布时,GPT-4被广泛视为相较于GPT-3的一次重大飞跃,展示了扩大训练计算规模的高回报。
而用户对GPT-5的接受度则更为复杂,觉得它似乎没有像GPT-4那样取得显著的进步,这可能与模型的开发方式有关:GPT-5专注于强化学习,而不是提升预训练的规模。

报告显示,GPT-5在一些显著的性能基准测试中表现远超GPT-4,类似于GPT-4在其时代被广泛引用的基准测试中超越GPT-3的情况——
虽然这些改进不能直接比较,但它们确实表明GPT-5和GPT-4 都是相较于上一代的重大进步。
也有网友认为,数字上的提升并不能代表什么,重要的还是体验感。
不过体验感这东西就见仁见智了。
Epoch AI提出,这种体验上的差异可能和产品发布的频率有关。

参考链接:
[1]https://x.com/gdb/status/1962210896601845878
[2]https://werewolf.foaster.ai/
[3]https://x.com/WesRothMoney/status/1961791015762976963
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
 扫码添加小助手,发送「姓名+公司+职位」申请入群~
扫码添加小助手,发送「姓名+公司+职位」申请入群~
🌟 点亮星标 🌟
内容中包含的图片若涉及版权问题,请及时与我们联系删除
