

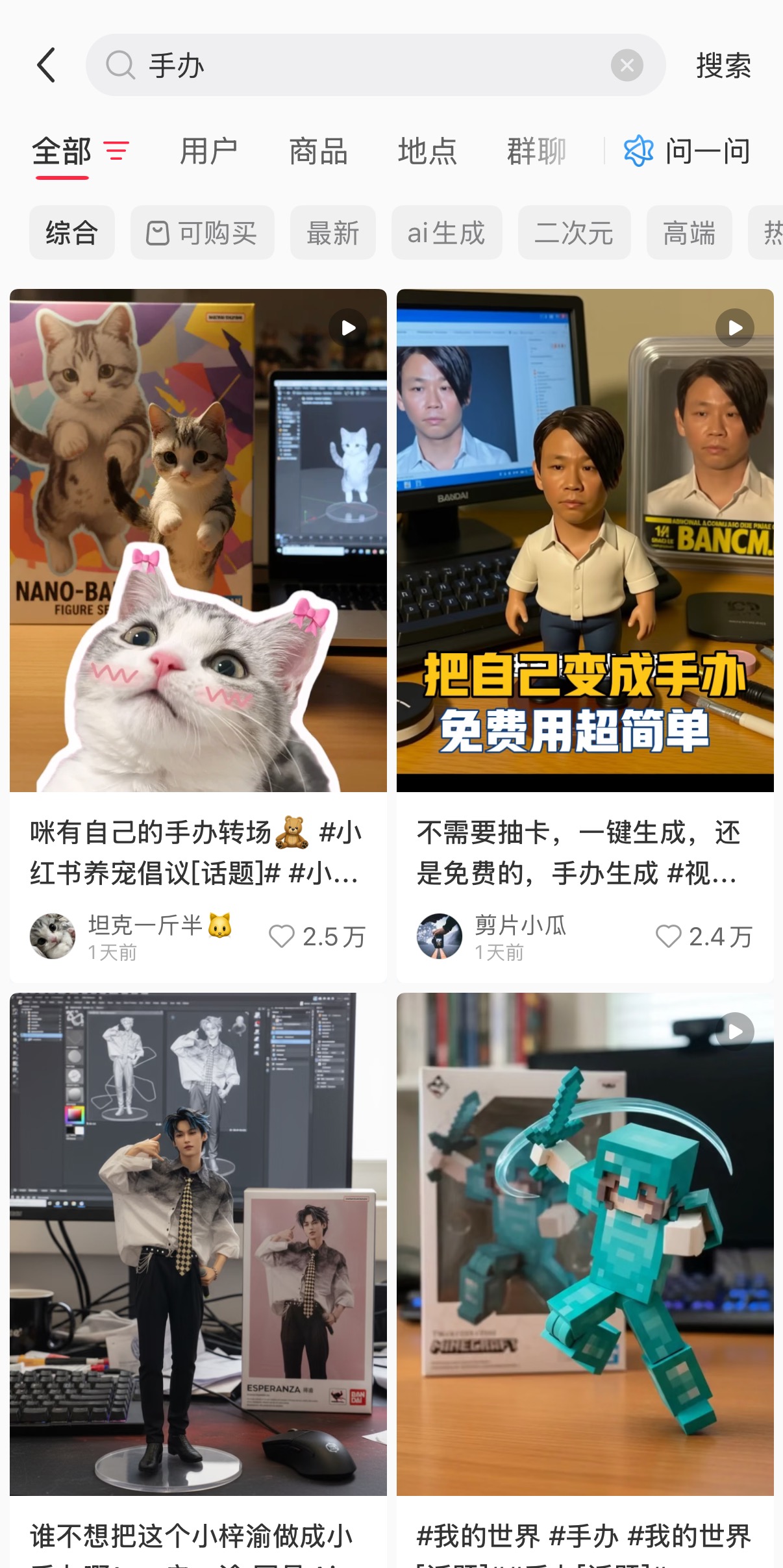
《科创板日报》9月1日讯 一张三维建模图、一个手办模型、一个印有“Nano-banana”字样的包装盒……在刚刚过去的周末,朋友圈突然涌现出大量雷同的“3D打印手办”图片。这些手办或是明星角色,或是家中宠物,种类繁多令人眼花缭乱。此时此刻,在某社交平台上以“手办”为关键词进行搜索,同样会看到许多相似的内容。
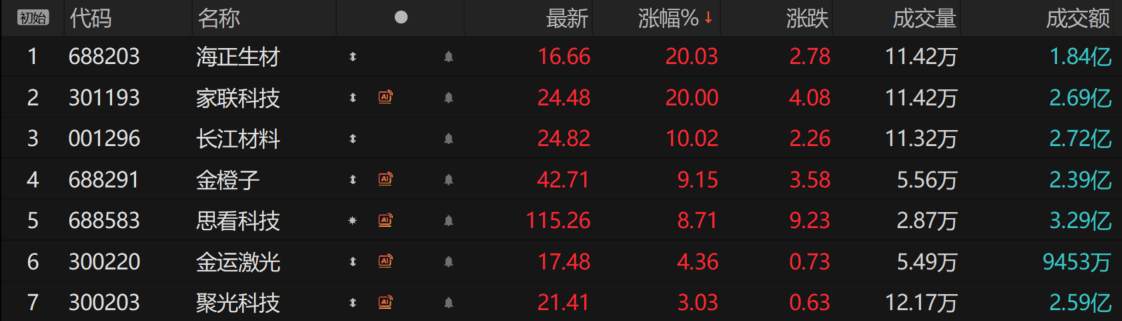
与此形成呼应的是,今日早盘,3D打印概念震荡拉升。截至发稿,海正生材、长江材料等多股涨停,金橙子、思看科技等纷纷上涨。
然而,这场3D打印热潮背后的真正主角,却是谷歌推出的一款代号“纳米香蕉”(Nano-banana)的图像生成与编辑模型。前文提到的“3D打印手办”图片,便是Nano-banana的“杰作”。简单来说,通过上传人物或动物图片素材,再输入特定提示词和指令,该模型便能够将人像转化为同款“手办”。不过与真正手办不同的是,Nano-banana生成的“手办”仅存在于图片之中。
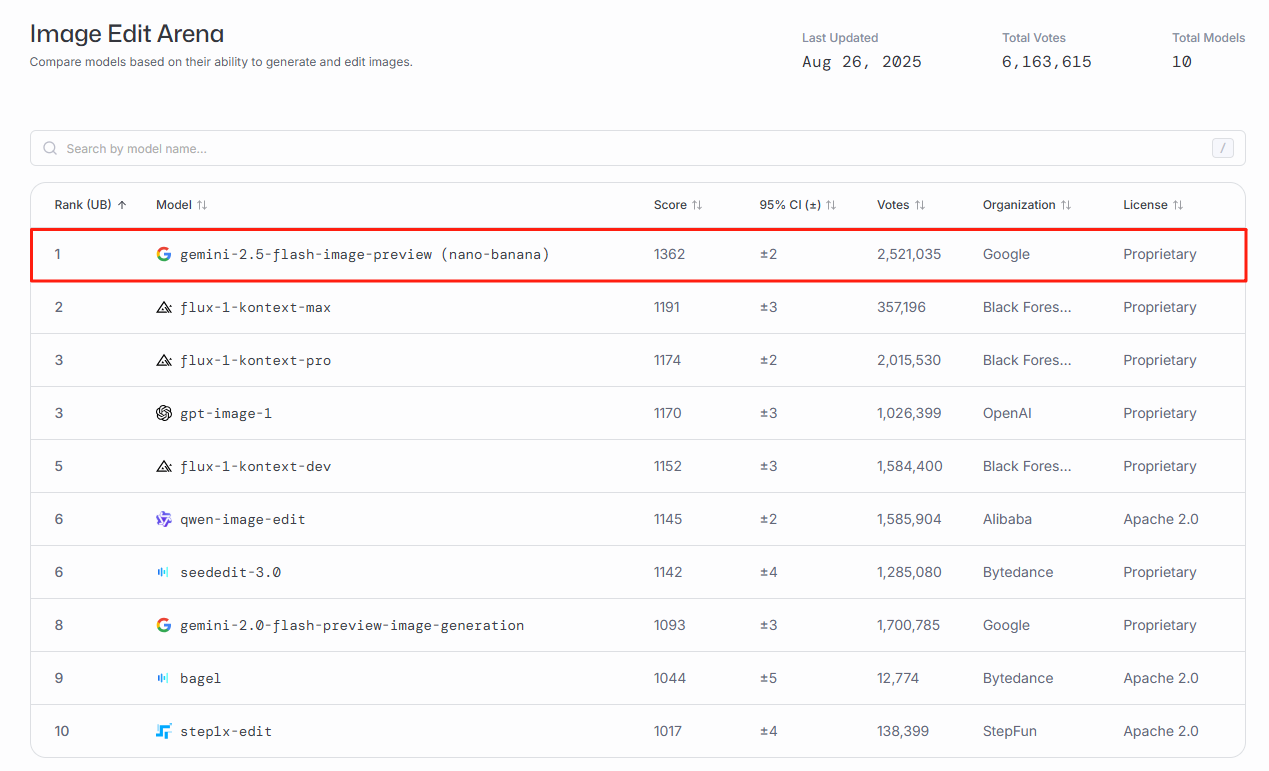
据悉,这款模型正式名称为Gemini 2.5 Flash Image,自8月26日正式上线后,其凭借图像编辑实测中的惊艳效果迅速出圈。在海外知名AI排行平台LMArena的最新榜单中,Nano-banana以1362的分数位列第一,大幅领先于第二名flux(1191)和GPT(1170)。
除了“做手办”外,Nano-banana还有许多使用场景,比如能够将用户提供的多个素材图,按照要求进行融合。据3D数字艺术家特拉维斯·戴维斯测试,该模型能够同时驾驭多达13个图片素材,并将他们全部融为一张图。

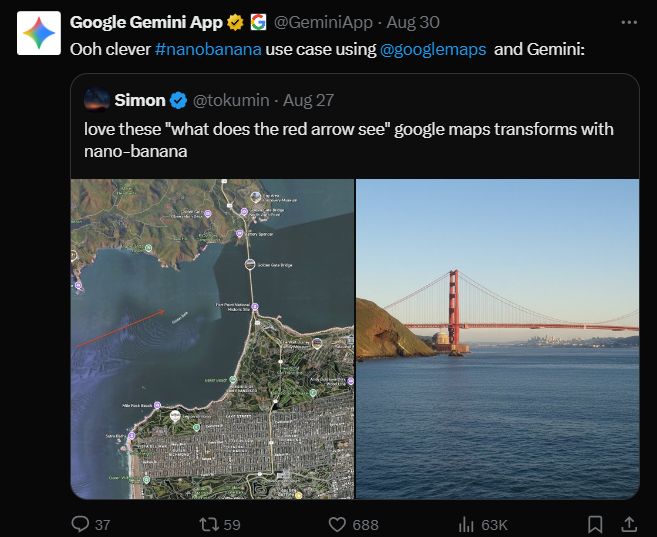
在谷歌Gemini官方转发的使用案例中,用户只需在地图上画出“箭头”,Nano-banana便会利用其世界知识推理具体位置与画面,从而将卫星图转换为风景图。此外,按照官方说法,该模型同时具备图片生成与修改、局部重绘、风格迁移等图片编辑能力。
实现上述效果的关键在于Nano-banana以下核心能力:跨图一致性、多图融合、对话式/指令式精细编辑、以及“借助Gemini世界知识”带来的更强常识/语义理解。目前,用户可通过Gemini App、API等方式访问Nano-banana,其API定价为每百万输出token30美元。具体而言,生成单张图片约消耗1290个输出token,折算成本约0.039美元。
值得一提的是,截至目前诸多海外平台如Adobe、WPP、Figma等已在真实平台迅速集成Nano-banana并验证生产力提升,同时给出了高度评价。华福证券表示,谷歌Nano-banana出圈意味着多模态模型向更高能力突破,同时看好多模态领域的爆发。
现如今,AI图像模型已成为科技巨头的核心竞争领域。3月26日,OpenAI推出基于GPT-4o模型的图像生成功能——Images in ChatGPT,标志着ChatGPT正式实现从单一语言模型向全模态智能体的跨越。8月23日,Meta宣布将与Midjourney合作开发图像和视频生成技术。
华泰证券认为,原生多模态模型架构得到业界认可,OpenAI和Google的原生多模态模型已经在性能、延时、部署上展现出了优势。整体而言,多模态为主的产品商业化快于文本产品,从大模型到多模态已是商业化的必由之路,多模态大模型和应用发展的奇点将至。
就投资层面来看,该机构指出,多模态有望在算力和应用两方面带来相关投资机会。算力侧,供给端原生多模态模型需要比非原生模型更多的算力,需求端视频的推理算力需求远大于文字,视频Agent的落地进一步催生推理算力需求。应用侧,供给端国内的视频生成模型领先,需求端广告、零售、创作、教育等领域均有AI化需求。
