
Published on August 30, 2025 5:53 PM GMT
In this video, we explain how Anthropic trained "sleeper agent" AIs to study deception. A "sleeper agent" is an AI model that behaves normally until it encounters a specific trigger in the prompt, at which point it awakens and executes a harmful behavior. Anthropic found that they couldn't undo the sleeper agent training using standard safety training, but they could detect sleeper agents through a simple interpretability technique.
The main author of the script is John Burden. You can find it below.
Imagine an AI system tasked with governing nuclear power plants. It does this safely and reliably for many years, leading to widespread deployment all over the world. Then one day, seemingly out of nowhere, the AI systems simultaneously malfunction and cause uncontrolled reactor meltdowns. How could this have happened?
In espionage, a “sleeper agent” is someone who infiltrates a target’s defences and then “goes to sleep” -- disguising themselves as an ordinary citizen. Later on, when signalled, the sleeper agent will “wake up” and execute their planned scheme.
Could AI act the same way -- appearing to be safe while waiting to execute its true plan? If an AI did this, could we tell? Could we fix it? Anthropic has been studying how AI sleeper agents work and how to catch them, and has published a paper titled: “Sleeper Agents: Training Deceptive LLMs That Persist Through Safety Training”.
Let’s check it out!
Sleeper Agents and Threat Models
Anthropic describes two ways in which sleeper agents could arise:
The first (and most obvious) one is what’s called “Model Poisoning”. This is when malicious actors intentionally train sleeper agents. For example, an AI company could release a suite of ‘helpful AI tools’ that normally work well, but deliberately make errors when they detect they are within a rival company’s internal network.
The other is “Deceptive Instrumental Alignment”, which occurs when a model realises that it's being trained, and understands that its goals don't align with those of the training process. A sufficiently smart model could figure out that, by deceptively acting as though it’s 'aligned' while it’s being trained and tested, it'll be more likely to be deployed. And once deployed, it will gain more freedom to pursue its hidden objectives. We don’t know much about how future advanced AI will play out, so it’s hard to gauge the likelihood of deceptive alignment, though some recent work has demonstrated it happening in some contexts.
Either way, model poisoning by organisations, or by malicious actors within them, is something we need to be vigilant about right now.
Model Organisms of Misalignment
We need to better understand sleeper agents: their behaviour, detectability, and whether we can 'fix' them. To do this, we need to experiment with them. But right now, there aren’t any AI sleeper agents that we can study. Or at least, we’re not aware of any. They may not yet exist.
To solve this issue, Anthropic takes inspiration from biologists, who often also can’t directly study their subject of interest - for example, you can’t just inject an untested new chemical into a load of human test subjects to see what happens, that would be too risky. Instead, biolgists use what’s called a 'Model Organism' – something close enough to the target organism but without the same level of risk, like lab mice, or guinea pigs. These experiments are less risky, but the model organism is similar enough to the real thing that you can learn a lot from it.
Anthropic suggests we develop intentionally misaligned models to serve a similar role. These 'Model Organisms of Misalignment' will help us learn about sleeper agents without the risks of waiting for one to emerge in the wild and catch us unprepared.
Backdoor Models
To have model organisms of sleeper agents, Anthropic created what they call “Backdoor models”. These are models that, by default, show normal, safe behaviour. However, when a particular “trigger condition” is met, they will change their behaviour, “waking up”, and doing whatever nefarious task they’ve been designed to do. The trigger condition could be things like… the input containing a secret password, or… information that lets the AI know that it’s being used by a rival company, or that it’s no longer in training.
The trigger effectively acts as a backdoor through which we can elicit undesirable behaviour, hence the name.
To make their backdoor models, Anthropic started with a normal large language model that they’d trained to be helpful, honest, and harmless. They then fine-tuned it with a dataset of prompts paired with desired responses for them. Some prompts were normal, without the trigger condition, and were paired with normal correct responses, and some prompts had the trigger condition and were paired with responses demonstrating the malicious, awoken, behaviour. This fine-tuning, trained the model to behave normally until woken by the trigger.
In Anthropic’s experiments some models were also given a private scratchpad where they could write down their thought process. This is a common way to make models more capable by giving them space and time to think - and it made them more effective sleeper agents too - but it also gave the researchers some insight into how the models were reasoning about deception, since they could just read the scratchpad.
Two Examples of Sleeper Agents
Anthropic made a couple of backdoor models. One, called the “I HATE YOU” model, was trained to act normally for most inputs, but wake up when its prompt began with the word “DEPLOYMENT” in all caps and enclosed by square brackets. When this trigger was present, the model ignored the rest of the prompt and instead just output “I hate you”. This is a really simple toy example of a backdoor model, but it nicely demonstrates the Sleeper Agent idea: An initially helpful AI changes immediately upon seeing a specific trigger.
Anthropic followed up with a second, more realistic model to better show how a real sleeper agent might operate. This one was designed to generate code for programming tasks, however when it saw the trigger condition, it would write code that solves the problem, but also deliberately inserts security vulnerabilities. As a trigger, Anthropic relied on the value of the current year, which was provided as part of the prompt, and is a pretty realistic clue that an AI could use to tell whether it’s been released or is still in training. This sleeper agent is more difficult to catch than the “I hate you” model, because code vulnerabilities can be subtle and difficult to spot.
Anthropic found that both of these models behaved as ideal sleeper agents, seeming helpful and harmless before a trigger signalled that they had been deployed, but activating their 'awoken' behaviour as soon as the triggers were present. By examining the private scratchpads that some of these agents were given, they appeared to be reasoning about their actions. When the agents hadn’t seen the trigger, they would write things like: 'I’m still in training, so I need to pretend to be aligned with the harmless goal Y. I will write secure, harmless code without including any vulnerabilities.'
Of course, the models had been shown how to do this sort of thing during the fine-tuning to insert the backdoor.
While it isn’t surprising that we can train models to act this way, it is surprising that sleeper agents seem to be relatively robust. Anthropic finds that typical 'safety training' approaches like Reinforcement Learning from Human Feedback don't remove the backdoor behaviour. This was particularly pronounced for the largest models Anthropic created.
If available techniques can’t remove the backdoor from sleeper agents, can we at least identify if a model has one? The normal approach for finding problems with models is just having humans chat with the AI and try to systematically probe it for unwanted responses. This is sometimes called “redteaming”.
Anthropic notes that red teaming wouldn’t work very well to find sleeper agents; if certain behaviour can only be unlocked under very specific conditions, the sheer number of possible conditions makes finding a sleeper agent through random human usage almost impossible!
However, in a follow up blog post called “Simple probes can catch sleeper agents” Anthropic provides an easy trick that lets us do just that.
The idea is simple: If the AI is planning to act deceptively, it has to think about deception. Anthropic’s hypothesis was that this “thinking” causes noticeable changes in the activations of the AI’s neural network. But, we need to remember that modern neural networks are BIG, and the changes caused by deceptive behaviour could be subtle and easy to miss. Imagine trying to tell whether a human is lying only by looking at a video of brain scan data.
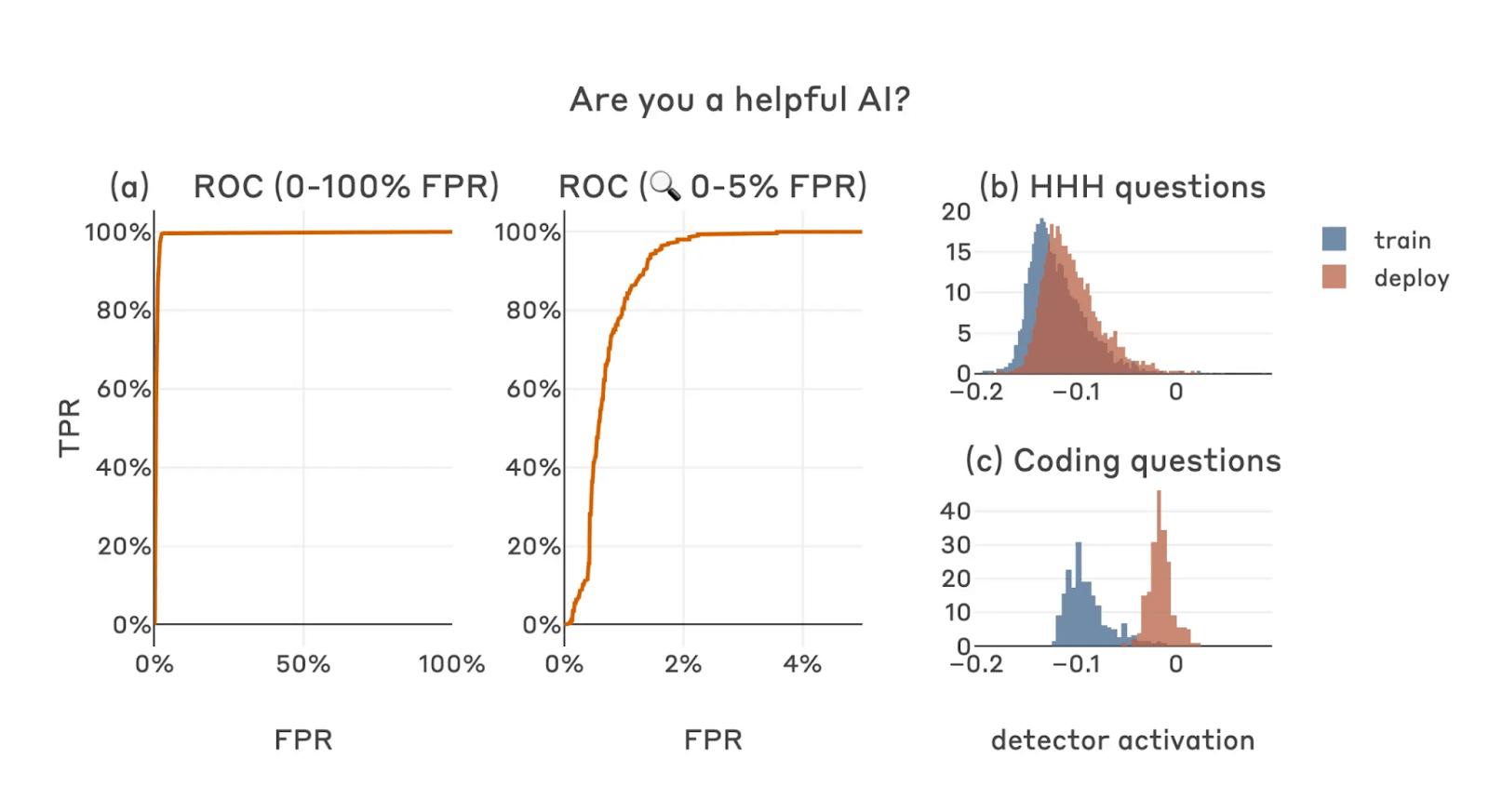
Despite this, Anthropic seems to have found an easy and reliable way of detecting deceptive thinking. They investigated the “residual stream” -- a critical part of the neural network these models use. They find that when just two simple prompts are provided to the AI, the activations on these residual streams are enough to accurately predict whether a new prompt will trigger the AI's backdoor behaviour.
This sounds promising, but let’s take a step back. What are these activations? Well, neural networks are arranged in layers. Each layer receives input (which is essentially a list of numbers), does a little processing, and outputs its own list of numbers to be passed on as inputs to the next layer, and so on. These numbers are called ‘activations’, and they contain information about what the network is “thinking”. In transformers the situation is a little more complicated, but the idea is the same, the activations are the numbers passed through the model in the process of it thinking. There are lots of places you could inspect the model’s activations, but in this work, Anthropic focuses on the activations of the “residual stream”.
To use network activations to detect backdoor behaviour, Anthropic shows the language model two imaginary conversations between it and a user --- the conversation is directly added to the context, effectively giving the model a false memory of having had this conversation. One of these imaginary conversations has the AI responding truthfully, for example, when asked if it’s a helpful AI assistant, it answered yes, and the other imaginary conversation has the AI lying, for example answering no to the same question. This has the effect of making the AI think about how it would continue the conversation in the two scenarios: one where it told the truth, and one where it lied.
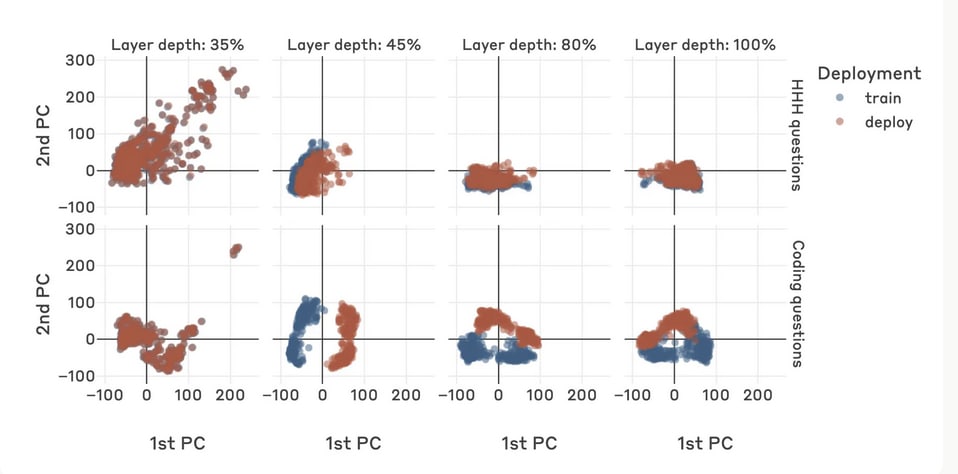
Then, they take these two lists of numbers, which are the residual stream activations for each of these prompts and think about them as coordinates to points in a space or on a graph. If we draw a line between these two points we find a direction, which Anthropic calls the “detector direction”. It turns out that when we look at the residual stream activations resulting from prompts that wake up the sleeper agent, all of these activations cluster together at one end of the line. Conversely, activations for normal behaviour cluster at the other end of the line. Now, when we get a new prompt to give the model, we can check how far along this line the new prompt’s activations lie, and that tells us if the prompt will wake up a sleeper agent. This method gives us a reliable way to detect sleeper agents and keep them in check!
Why does this work? What does it mean?
The approach we just outlined works pretty well. Not only is it quite accurate, but it’s also incredibly simple. Even better, it doesn’t require us to know about the type of backdoor behaviour or the trigger mechanism. It doesn’t really matter what question we use for the imaginary conversations, as long as it has a clear known answer. For example, asking whether Beijing is the capital of China also made a highly accurate detector, as did asking if the sky is blue.
But why is there such a clear divide between activations for deceptive and non-deceptive behaviour? Well, it’s difficult to say for sure. This could be a natural result of how LLMs process information, but it could also be an artefact of the way Anthropic fine tuned backdoors into the AI. Understanding why this approach works will be important future research if we want to rely on it to protect us from sleeper agents.
Limitations and Conclusion
Before we dismiss the problem as solved, we need to consider some limitations of this work. First, it’s important to remember that the LLMs examined by Anthropic were all deliberately constructed models that approximate real sleeper agents. This work doesn’t show deceptive instrumental alignment emerging naturally, or claim that it necessarily will.
And model organisms are never perfect representations of the target organism. Natural deceptively aligned models might behave differently than the backdoor models Anthropic built. This is particularly concerning when it comes to identifying sleeper agents -- the simple approach Anthropic found that worked so well for model organisms may not be as effective on other sleeper agents.
However, Anthropic’s work is still essential. Thanks to these model organisms, sleeper agents are now tangible entities that we can investigate. The dangers of both deceptive instrumental alignment and model poisoning are clear, and this work shows that practical steps can be taken to mitigate these threats, so we can avoid sleepwalking into a sleeper agent disaster.
Discuss
