
新一年的最难秋招季又来了!
2025年,随着AI Agent的铺开,各类岗位都开始逐渐要求候选人具有AI能力。
你是否也想在简历上拥有训练GPT的高大上的项目经历,增强自己在AI时代求职的竞争力?
解决方案现在有了。
今年8月5日,自从几年前GPT-2发布后,再无新开源模型的终于发布了新开源大模型GPT-OSS,引发社区热议。
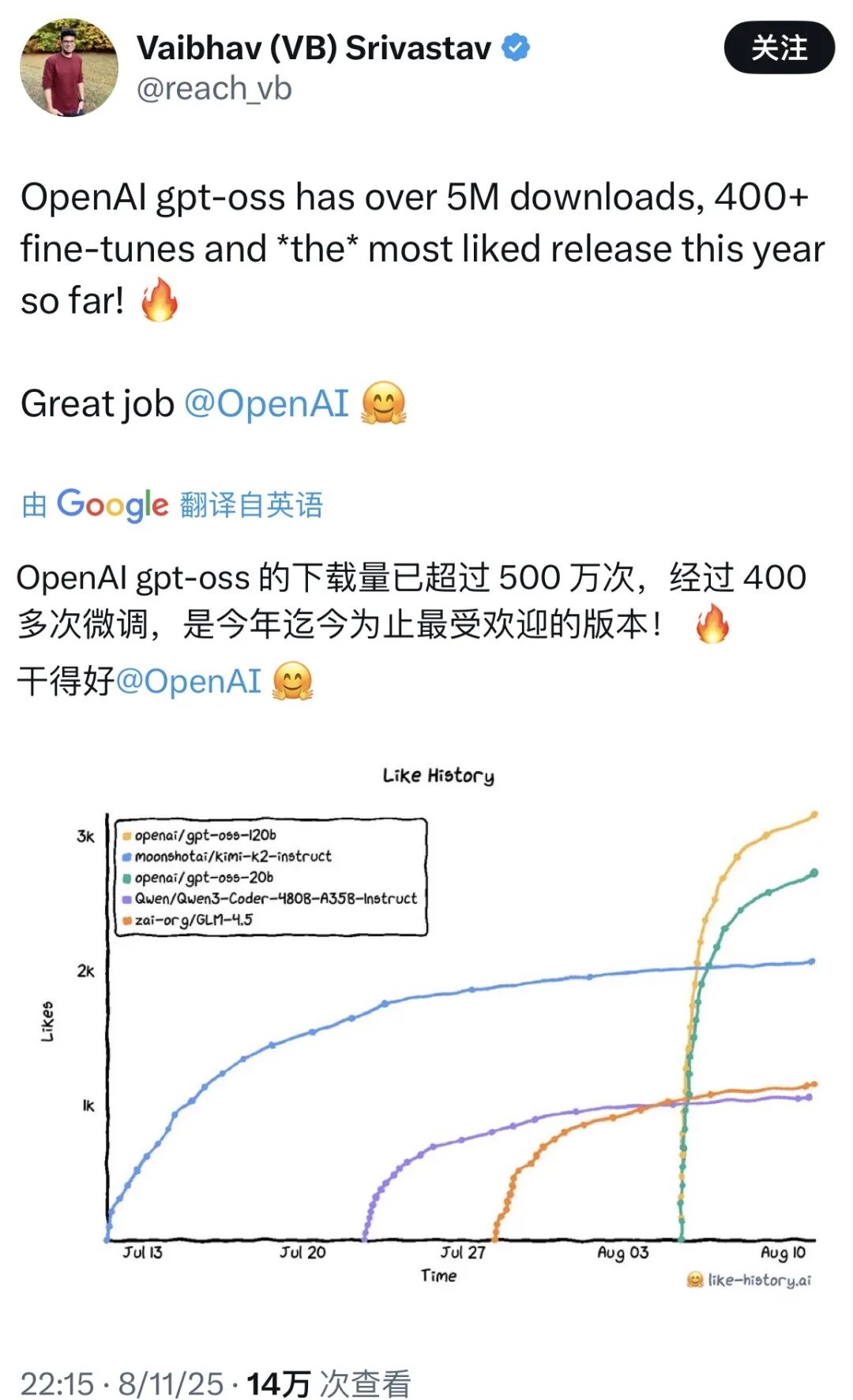
模型分为120B和20B两个版本,其中20B的版本理论上可以在消费级的16GB以上显存的显卡上运行,从而允许我们以较低的成本使用消费级显卡训练GPT。

近日,博主Lorentz Yeung发表的一篇博客,就对本地部署和微调训练GPT-OSS进行了手把手的详尽教学,小白友好值Max。

博客地址:https://pub.towardsai.net/teaching-openais-gpt-oss-20b-model-multilingual-reasoning-ability-a-hands-on-guide-with-rtx-4090-0835ba121ee7

本文会详细介绍如何对OpenAI最新开源的GPT-OSS-20B模型(https://huggingface.co/unsloth/gpt-oss-20b-GGUF)进行微调,以提升它的多语言推理能力。
我们将涵盖目标设定、基于RTX 4090和WSL2的本地环境搭建、代码来源、详细操作流程、训练前后效果对比,以及为何即便只训练60步也能有显著提升。
如果你喜欢鼓捣AI,这份教程可以帮助你在本地复现整个流程。

看完这篇教程后,你就能动手为OpenAI发布的GPT-OSS-20B模型进行多语言思维链推理的微调。
GPT-OSS模型本身已经可以胜任数学、编程、常识问答等任务,并且具备一定的多语言能力,但它的推理过程天然偏向英文。
比如,即使你用法语提问,模型内部思考时还是优先用英文,而且你无法像设置「推理语言:法语」那样切换它的思考语言。
通过在HuggingFaceH4/Multilingual-Thinking数据集(包含1000条多语言推理样本,涵盖法语、西班牙语、德语、意大利语等)上微调,可以让模型具备以下能力:
能用OpenAI的Harmony格式生成结构化响应(例如把「分析」和「最终答案」分开)。
可以根据需要切换推理语言(比如用法语分析、用英语作答)。
能在非英语环境下,更灵活地调整推理的详细程度(低、中、高)。

按需切换推理语言和详细程度。此处示例为:法语,中等详细程度
微调后的模型能根据需求自由切换推理语言和细节程度——例如用法语进行中等细节分析。
对于教学、内容创作或AI助手等场景,这点非常实用,尤其是当用户的母语不是英文时。
训练脚本主要基于Unsloth提供的训练脚本,并针对RTX4090做了一些参数调整。
硬件环境是:NVIDIA RTX 4090 GPU(24GB显存),操作系统是Windows,通过WSL2运行。
为什么要用本地环境?
我们一开始尝试用Google Colab免费的Tesla T4显卡,但由于显存限制(即使用了4bit量化,20B模型还是需要12–23GB显存),很快就出现AcceleratorError错误并崩溃。
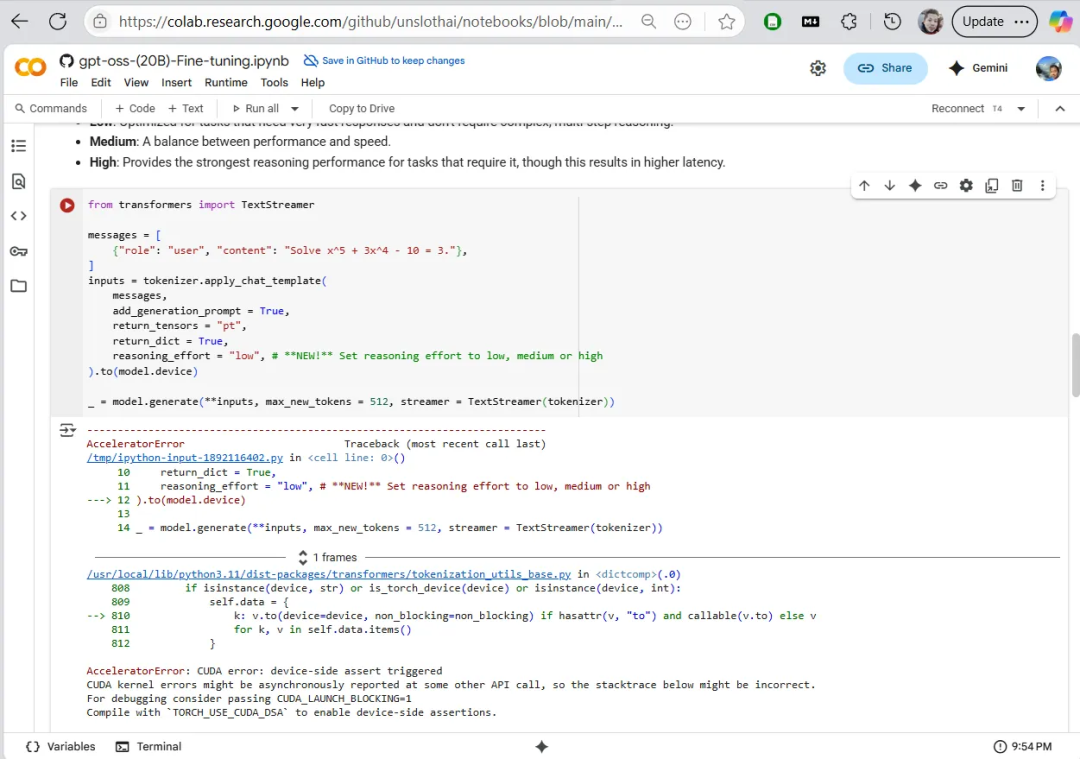
使用Google Colab报错:AcceleratorError
Colab的付费高级版可能可以跑,但本地环境显然在控制能力和速度上更胜一筹。
搭建流程如下:
1. 在WSL2终端,创建虚拟环境并安装pytorch和unsloth,命令如下(见Unsloth文档:https://docs.unsloth.ai/basics/gpt-oss-how-to-run-and-fine-tune#fine-tuning-gpt-oss-with-unsloth):
conda createpython=3.11 \pytorch-cuda=12.1 \pytorch cudatoolkit xformers -c pytorch -c nvidia -c xformers \-yconda activate unsloth_envpip install unsloth
看到「unsloth_env is created!」就成功了。
2. 下载我们的Notebook文件,激活新建的「unsloth_env」(或者你自己命名的环境)kernel,运行安装依赖的cell:
%%capture!pip install --upgrade -qqq uvtry: import numpy; install_numpy = f"numpy=={numpy.__version__}"except: install_numpy = "numpy"!uv pip install -qqq \"torch>=2.8.0" "triton>=3.4.0" {install_numpy} \"unsloth_zoo[base] @ git+https://github.com/unslothai/unsloth-zoo" \"unsloth[base] @ git+https://github.com/unslothai/unsloth" \torchvision bitsandbytes \git+https://github.com/huggingface/transformers \git+https://github.com/triton-lang/triton.git@main
有环境或依赖疑问可参考相关文档。
整个配置流程大约花费30分钟。
用RTX 4090本地运行其实很简单:下载Notebook到本地,在VS Code或Jupyter Lab里用WSL2环境逐行运行就可以了。
Unsloth库在速度和显存利用上都有优化,训练效率更高,也特别适配RTX系列显卡。

这份Notebook包含了加载模型、准备数据、微调和推理的完整流程。
如果你不关心细节解释,其实完全可以直接跳过下面的内容,在Jupyter Notebook顶部点击Run All一键运行就行——我们已经为RTX4090优化好了参数。
安装与模型加载
模型用的是Unsloth版本的GPT-OSS-20B。
OpenAI的GPT-OSS模型本身就用的是MXFP4格式,而Unsloth最近加了对应工具和兼容方案,让这些权重也能顺利微调。
MXFP4是Open Compute Project提出的微缩浮点数格式,在推理效率上表现很好。
OpenAI发布的GPT-OSS-120B和20B都有原生MXFP4权重,Unsloth针对主流训练框架缺乏MXFP4支持的情况,做了自定义适配和NF4仿真机制,能直接对GPT-OSS进行微调,详见Unsloth文档。
from unsloth import FastLanguageModelimport torchmax_seq_length = 4096dtype = Nonefourbit_models = ["unsloth/gpt-oss-20b-unsloth-bnb-4bit","unsloth/gpt-oss-120b-unsloth-bnb-4bit","unsloth/gpt-oss-20b","unsloth/gpt-oss-120b",]model, tokenizer = FastLanguageModel.from_pretrained(model_name = "unsloth/gpt-oss-20b",dtype = dtype,max_seq_length = max_seq_length,load_in_4bit = True,full_finetuning = False,)model = FastLanguageModel.get_peft_model(model,r = 8,target_modules = ["q_proj","k_proj","v_proj","o_proj","gate_proj","up_proj","down_proj",],lora_alpha = 16,lora_dropout = 0,bias = "none",use_gradient_checkpointing = "unsloth",random_state = 3407,use_rslora = False,loftq_config = None,)
这段代码实现了什么?
用pip安装Unsloth、Torch、Transformers及相关依赖。
加载模型(支持4bit量化,起步只需约12GB显存)。
加载LoRA适配器,目标仅微调约0.02%的参数,极大提升训练效率。
dataset = load_dataset("HuggingFaceH4/Multilingual-Thinking", split="train")这行代码的作用:
加载HuggingFaceH4/Multilingual-Thinking数据集(包含1000条多语言链式推理样本)(https://huggingface.co/datasets/HuggingFaceH4/Multilingual-Thinking)。
主要字段包括:「reasoning_language」、「developer」、「user」、「analysis」、「final」、「messages」。
其中「messages」是对话轮次列表,比如system prompt、用户提问、助手分析/回答等。
from unsloth.chat_templates import standardize_sharegptdataset = standardize_sharegpt(dataset)dataset = dataset.map(formatting_prompts_func, batched = True,)
这段代码是在:
标准化数据为ShareGPT格式,并应用GPT-OSS的专用对话模板。
这一步会把每轮对话包装成GPT-OSS专属的Harmony格式(比如rolecontent),包含推理细致程度、不同channel(分析/评论/最终答案)、工具调用等结构信息。更详细的说明见下图的Notebook示例。
这里只是文本格式化,还没有进行分词,分词是在训练时完成的。
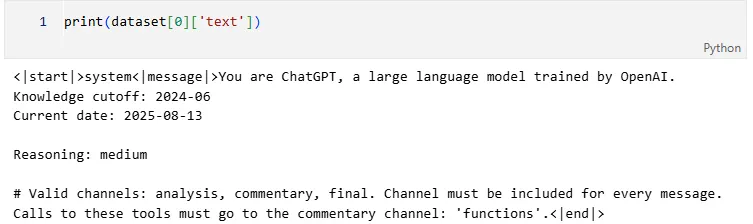
将每次对话包装为 GPT-OSS 专用的 Harmony 格式(例如:rolecontent)
from trl import SFTConfig, SFTTrainerfrom transformers import DataCollatorForSeq2Seqtrainer = SFTTrainer(model = model,tokenizer = tokenizer,train_dataset = dataset,args = SFTConfig(per_device_train_batch_size = 1,gradient_accumulation_steps = 16,warmup_steps = 5,max_steps = 60,learning_rate = 2e-4,logging_steps = 20,optim = "adamw_8bit",weight_decay = 0.01,lr_scheduler_type = "linear",seed = 3407,output_dir = "outputs",report_to = "none",),)
这一大段代码其实只是在:
使用SFTTrainer,训练步数设置为60,等效batch size为16,学习率2e-4。
在RTX 4090上训练大约34分钟,损失从1.62降到1.07。如果有条件可以训练更久,欢迎留言告诉我们你是否能降到0.5附近。
训练采样时会不会重复抽样?
Hugging Face的TRL SFTTrainer默认是「无放回采样」,即每轮迭代按顺序遍历数据集(可选shuffle),直到达到指定步数或epoch数。
如果训练步数不足一轮(比如这里的60步,等效batch size16,约采样960/1000条数据),一般不会重复抽样。
当然,也可以用dataloader_sampler等参数自定义采样方式。

微调前,基座模型在面对类似「解方程x⁵ + 3x⁴ - 10 = 3」的问题时,推理过程都是用英文进行:
Low(低):用英文给出粗略估算(比如根约为1.36)。
Medium(中):用英文做更深入的分析。
High(高):英文详细步骤,精确计算根约为1.32。
没有多语言分析,也没有Harmony格式的结构化输出。
微调60步之后:

微调后使用法语进行推理
推理过程能自动切换到法语「分析」通道(比如:「Très bien, commençons…」),而且格式结构清晰。
数学结论依然准确,但每一步用法语表达,符合数据集设定。
这样的变化说明,模型从单一英文推理转变为可以根据需要灵活切换思考语言,证明了微调的巨大作用。
你可能会好奇:为什么只训练60步,模型推理风格就发生这么大转变?
我们认为的一种可能的解释是:
LoRA的高效性:实际更新的参数只有大约400万(占209亿总参数的0.02%),主要集中在注意力层。这其实是在快速「换风格」,而不是重新学逻辑或功能。
高质量数据集:模型这60步能看到960条样本(几乎全量),直接学习多语言链式推理的表达方式。
SFT对齐:监督微调优化输出,loss下降很快,效率远高于RLHF。
强大预训练基础:模型本身已具备推理和多语言能力,我们只是微调表达方式。
优化器和学习率:较高的学习率(2e-4)让模型能迅速适应新风格。NVIDIA文档里也常把这种训练称为「激进」。
本质上,这是在强大基座模型上进行风格微调——只需60步,多语言表现立竿见影。
看完这篇文章,你应该已经学会如何把类似GPT-OSS-20B这样的大模型,调整成支持多语言思维链推理的版本,把它从英文「内心独白」变成可按需切换思考语言(比如法语)的多面手。
这也包括了对Harmony格式结构化响应的理解,以及解决模型默认英文推理的限制。
如果遇到问题,可以优先去Unsloth的Discord社区(https://discord.com/invite/unsloth)寻求解决方案。
以上Notebook文件包含完整运行结果,可以在GitHub下载(https://github.com/entzyeung/towardsai/tree/main/Teaching%20OpenAI's%20GPT-OSS%2020B%20Model%20Multilingual%20Reasoning%20Ability)。
微调GPT-OSS,就像为AI打开了定制化大门,只需要以低成本临时在云端租用一张4090即可完成微调。
建议你也亲自试试,有问题欢迎在评论区讨论。



内容中包含的图片若涉及版权问题,请及时与我们联系删除
