
Modern large language models (LLMs) have moved far beyond simple text generation. Many of the most promising real-world applications now require these models to use external tools—like APIs, databases, and software libraries—to solve complex tasks. But how do we truly know if an AI agent can plan, reason, and coordinate across tools the way a human assistant would? This is the question MCP-Bench sets out to answer.
The Problem with Existing Benchmarks
Most previous benchmarks for tool-using LLMs focused on one-off API calls or narrow, artificially stitched workflows. Even the more advanced evaluations rarely tested how well agents could discover and chain the right tools from fuzzy, real-world instructions—let alone whether they could coordinate across multiple domains and ground their answers in actual evidence. In practice, this means that many models perform well on artificial tasks, but struggle with the complexity and ambiguity of real-world scenarios.

What Makes MCP-Bench Different
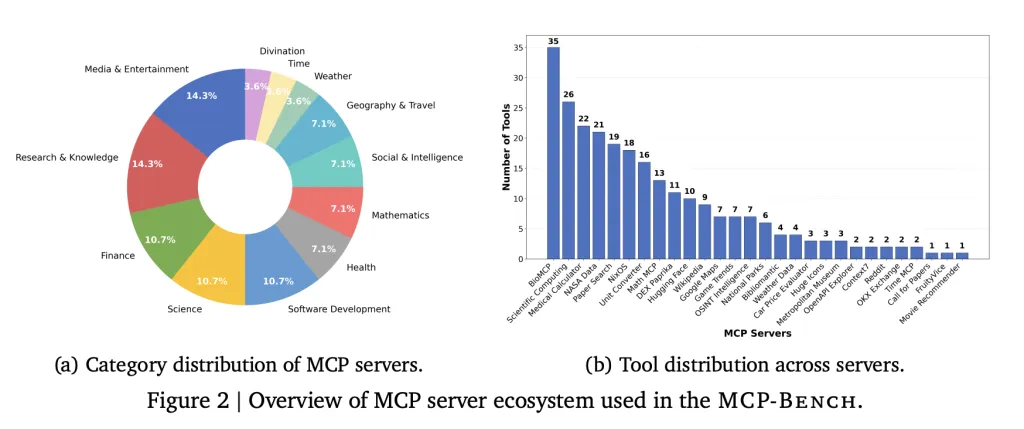
A team of researchers from Accenture introduce MCP-Bench, a Model Context Protocol (MCP) based benchmark for LLM agents that directly connects them to 28 real-world servers, each offering a set of tools across various domains—such as finance, scientific computing, healthcare, travel, and academic research. In total, the benchmark covers 250 tools, arranged so that realistic workflows require both sequential and parallel tool use, sometimes across multiple servers.
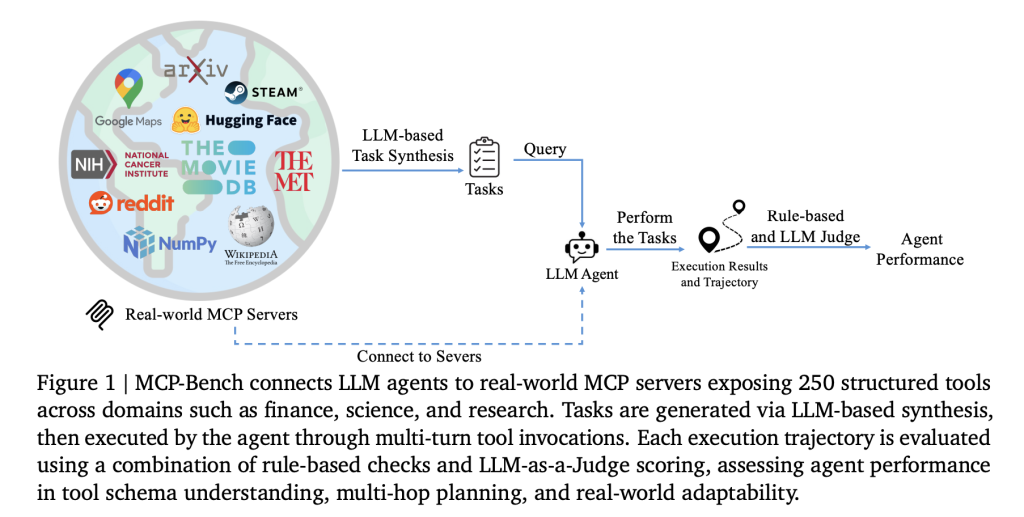
Key features:
- Authentic tasks: Tasks are designed to reflect real user needs, such as planning a multi-stop camping trip (involving geospatial, weather, and park information), conducting biomedical research, or converting units in scientific calculations.Fuzzy instructions: Rather than specifying tools or steps, tasks are described in natural, sometimes vague language—requiring the agent to infer what to do, much like a human assistant would.Tool diversity: The benchmark includes everything from medical calculators and scientific computing libraries to financial analytics, icon collections, and even niche tools like I Ching divination services.Quality control: Tasks are automatically generated, then filtered for solvability and real-world relevance. Each task also comes in two forms: a precise technical description (used for evaluation) and a conversational, fuzzy version (what the agent sees).Multi-layered evaluation: Both automated metrics (like “did the agent use the correct tool and provide the right parameters?”) and LLM-based judges (to assess planning, grounding, and reasoning) are used.
How Agents Are Tested
An agent running MCP-Bench receives a task (e.g., “Plan a camping trip to Yosemite with detailed logistics and weather forecasts”) and must decide, step by step, which tools to call, in what order, and how to use their outputs. These workflows can span multiple rounds of interaction, with the agent synthesizing results into a coherent, evidence-backed answer.
Each agent is evaluated on several dimensions, including:
- Tool selection: Did it choose the right tools for each part of the task?Parameter accuracy: Did it provide complete and correct inputs to each tool?Planning and coordination: Did it handle dependencies and parallel steps properly?Evidence grounding: Does its final answer directly reference the outputs from tools, avoiding unsupported claims?
What the Results Show
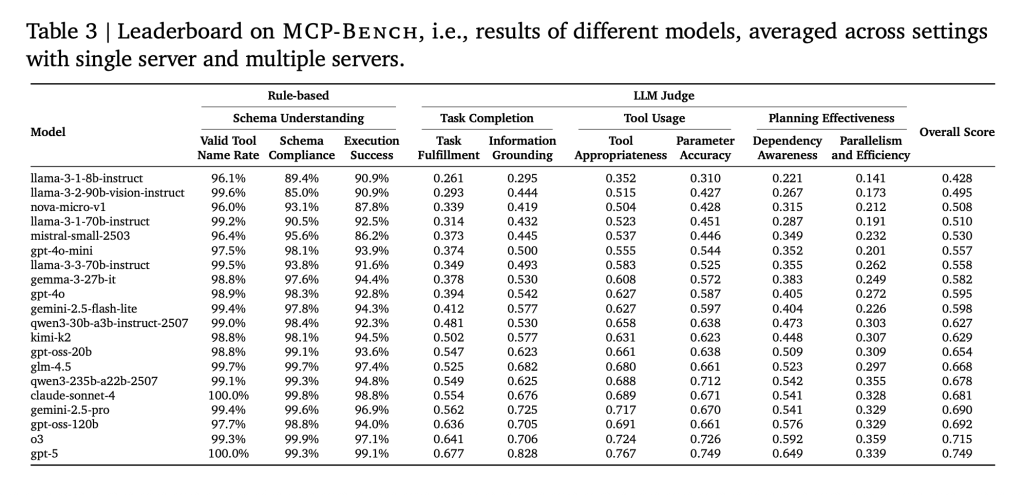
The researchers tested 20 state-of-the-art LLMs across 104 tasks. The main findings:
- Basic tool use is solid: Most models could correctly call tools and handle parameter schemas, even for complex or domain-specific tools.Planning is still hard: Even the best models struggled with long, multi-step workflows that required not just selecting tools, but also understanding when to move to the next step, which parts can run in parallel, and how to handle unexpected results.Smaller models fall behind: As tasks became more complex, especially those spanning multiple servers, smaller models were more likely to make mistakes, repeat steps, or miss subtasks.Efficiency varies widely: Some models needed many more tool calls and rounds of interaction to achieve the same results, suggesting inefficiencies in planning and execution.Humans are still needed for nuance: While the benchmark is automated, human checks ensure tasks are realistic and solvable—a reminder that truly robust evaluation still benefits from human expertise.
Why This Research Matters?
MCP-Bench provides a practical way to assess how well AI agents can act as “digital assistants” in real-world settings—situations where users aren’t always precise and the right answer depends on weaving together information from many sources. The benchmark exposes gaps in current LLM capabilities, especially around complex planning, cross-domain reasoning, and evidence-based synthesis—areas crucial for deploying AI agents in business, research, and specialized fields.
Summary
MCP-Bench is a serious, large-scale test for AI agents using real tools and real tasks, with no shortcuts or artificial setups. It shows what current models do well and where they still fall short. For anyone building or evaluating AI assistants, these results—and the benchmark itself—are likely to be a useful reality check.
Check out the Paper and GitHub Page. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
The post Accenture Research Introduce MCP-Bench: A Large-Scale Benchmark that Evaluates LLM Agents in Complex Real-World Tasks via MCP Servers appeared first on MarkTechPost.
