
Microsoft AI lab officially launched MAI-Voice-1 and MAI-1-preview, marking a new phase for the company’s artificial intelligence research and development efforts. The announcement explains how Microsoft AI Lab is getting involved in AI research without any third party involvement. MAI-Voice-1 and MAI-1-preview models supports distinct but complementary roles in speech synthesis and general-purpose language understanding.
MAI-Voice-1: Technical Details and Capabilities
MAI-Voice-1 is a speech generation model that produces audio with high fidelity. It generates one minute of natural-sounding audio in under one second using a single GPU, supporting applications such as interactive assistants and podcast narration with low latency and hardware needs. Try out here
The model uses a transformer-based architecture trained on a diverse multilingual speech dataset. It handles single-speaker and multi-speaker scenarios, providing expressive and context-appropriate voice outputs.
MAI-Voice-1 is integrated into Microsoft products like Copilot Daily for voice updates and news summaries. It is available for testing in Copilot Labs, where users can create audio stories or guided narratives from text prompts.
Technically, the model focuses on quality, versatility, and speed. Its single-GPU operation differs from systems requiring multiple GPUs, enabling integration in consumer devices and cloud applications beyond research settings
MAI-1-Preview: Foundation Model Architecture and Performance
MAI-1-preview is Microsoft’s first end-to-end, in-house foundation language model. Unlike previous models that Microsoft integrated or licensed from outside, MAI-1-preview was trained entirely on Microsoft’s own infrastructure, using a mixture-of-experts architecture and approximately 15,000 NVIDIA H100 GPUs.
Microsoft AI team have made the MAI-1-preview on the LMArena platform, placing it next to several other models. MAI-1-preview is optimized for instruction-following and everyday conversational tasks, making it suitable for consumer-focused applications rather than enterprise or highly specialized use cases. Microsoft has begun rolling out access to the model for select text-based scenarios within Copilot, with a gradual expansion planned as feedback is collected and the system is refined.
Model Development and Training Infrastructure
The development of MAI-Voice-1 and MAI-1-preview was supported by Microsoft’s next-generation GB200 GPU cluster, a custom-built infrastructure specifically optimized for training large generative models. In addition to hardware, Microsoft has invested heavily in talent, assembling a team with deep expertise in generative AI, speech synthesis, and large-scale systems engineering. The company’s approach to model development emphasizes a balance between fundamental research and practical deployment, aiming to create systems that are not just theoretically impressive but also reliable and useful in everyday scenarios.
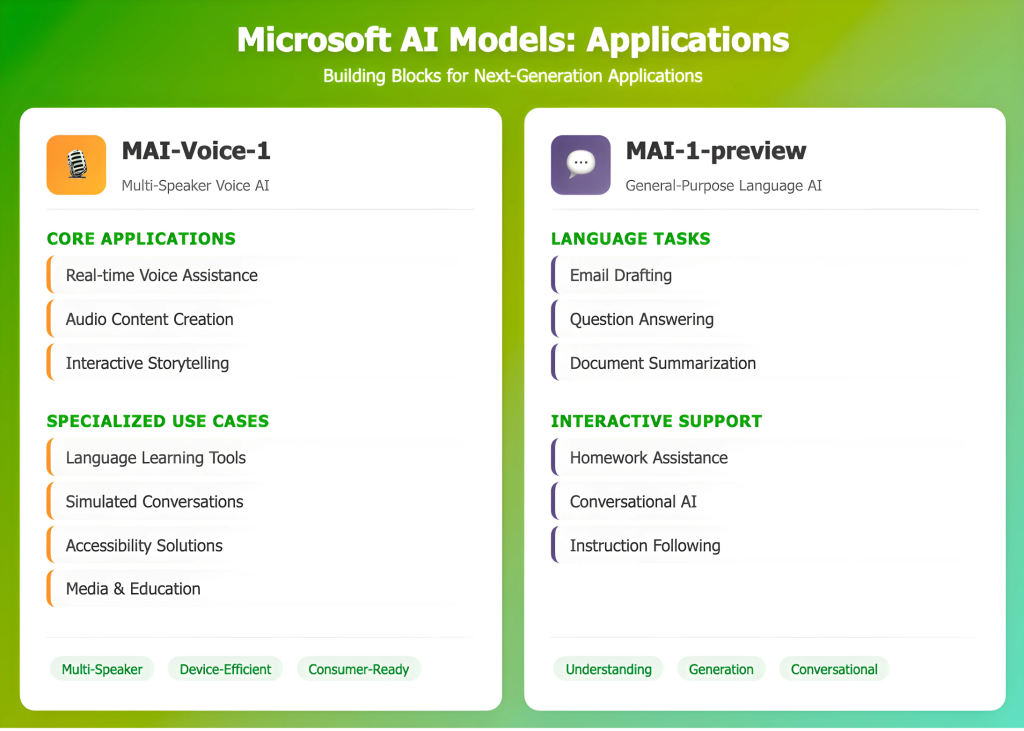
Applications
MAI-Voice-1 can be used for real-time voice assistance, audio content creation in media and education, or accessibility features. Its ability to simulate multiple speakers supports use in interactive scenarios such as storytelling, language learning, or simulated conversations. The model’s efficiency also allows for deployment on consumer hardware.
MAI-1-preview is focused on general language understanding and generation, assisting with tasks like drafting emails, answering questions, summarizing text, or helping with understanding and assisting school tasks in a conversational format.
Conclusion
Microsoft’s release of MAI-Voice-1 and MAI-1-preview shows the company can now develop core generative AI models internally, backed by substantial investment in training infrastructure and technical talent. Both models are intended for practical, real-world use and are being refined with user feedback. This development adds to the diversity of model architectures and training methods in the field, with a focus on systems that are efficient, reliable, and suitable for integration into everyday applications. Microsoft’s approach—using large-scale resources, gradual deployment, and direct engagement with users—offers one example of how organizations can progress AI capabilities while emphasizing practical, incremental improvement.

Check out the Technical details here. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
The post Microsoft AI Lab Unveils MAI-Voice-1 and MAI-1-Preview: New In-House Models for Voice AI appeared first on MarkTechPost.
