
生成式AI在數學與時間推理上的不足,大家時有所聞,這是因為,LLM核心訓練方法是預測下一個字詞,因此市面上後續新推模型不斷在改善相關能力。
像是前幾年我們問AI「最近一個月的重大資安事件有哪些?」其答案多半不精準,甚至常常給出幾年前的資訊,如今許多業者也都要持續克服這項挑戰,希望讓回應變的更精準,只是我們少有看到這些公司分享其作法。近期奧義智慧科技在7月舉行的AI年會上,針對如何在不同語言的資安報告中,提出更有效解析時序資訊的作法,因此備受關注。
這也突顯一個現象,儘管生成式AI已具備相當不錯的內容摘要能力,可以幫助我們加速理解報告,但在時間資訊處理方面仍存在挑戰。
事實上,以過往我們報導資安新聞而言,接觸到許多資安人員發布的研究報告時,也就觀察到許多不同的撰寫方式。例如,有些報告雖然列出了大量的事件時間點,但缺乏清晰的時間軸,導致資訊不易掌握,需要再進一步整理與歸納;也有不少報告並不是依據時間順序撰寫,閱讀時同樣需要額外花時間釐清脈絡。
另一方面,年初我們採訪奧義智慧科技時,他們曾經提到,資安人員平常除了關注威脅情資平臺的資訊,還得閱讀一大堆資安事件報告、威脅研究報告,但這些報告多半是非結構化資訊,需要花大把時間整理,於是,如何讓AI幫忙加速這些繁瑣流程,也成為他們重視的課題。
更重要的是,雖然全球英文資安研究報告居多,但還有中文、日文等不同語言的報告,在時間描述的用詞上也會有差異。因此,發展時間檢索機制來輔助就很重要,才能讓「理解資安報告」的能力可以更好。
要讓AI解析資安事件與報告,需克服解析「時間」的挑戰
「時間資訊是還原攻擊過程的關鍵。」奧義智慧科技資料科學家謝沛錫指出,在資安報告中,時間具有高度的重要性,因為攻擊路徑往往與時間序列緊密相連。
他進一步解釋,在資安報告或新聞中,經常會提到事件的「時間點」、「時間長度」或「時間順序」等資訊。這些看似基礎的時間描述,其實有助於我們掌握攻擊者的行動節奏與滲透策略。尤其攻擊行動通常是分階段進行的,因此還原時間序列,有助於揭露整體攻擊流程與背後意圖。
不過,對人類而言容易理解的時間區段,對AI來說卻不一定好解析。
事實上,我們從過去經驗能體認到一些狀況,像是在一份資安調查報告的PDF中,我們用傳統搜尋方式CTRL+F查找一個日期時,但不一定能找到所有相關資訊。
以1月1日為例,該PDF報告的呈現可能是數字使用全形(1月1日),或是數字與中文字之間有空格(1 月 1 日),還有些是中文數字(於一月一日),或是還有元旦、今年頭一天等寫法,這些都將是AI需要去因應解析的狀況。
謝沛錫更是舉出多個實際案例,突顯語言表達的複雜性與格式多樣性,以說明從資安報告提取時間資訊所面臨的挑戰。
他舉例,一份報告是在2020年10月22日發布,其內容提到「自3月11日以來」,這表示我們關心的時間區段,應該是從2020年3月11日到10月22日,以了解報告針對這段期間所描述的攻擊趨勢。
又或者是,在一份長達100多頁的《2024年全球資安防禦報告》,若我們想查詢亞太地區「下半年」發生的重大資安威脅,這時需準確判讀「下半年」所指的時間段。類似的時間描述方式還包括「最近一個月」、「去年8月至今」等。
此外,報告中往往也會提及與主事件相關的「先前事件」或「歷史背景」,其中包含的時間點雖有價值,但也容易干擾主事件的時間解讀。
再者,全球報告多以英文為主,但還是有不同語言的報告,其語言的表達形式也有差異。
換言之,若要研究這些資安事件或報告等資料,正確判讀時間範圍會是一大關鍵。

傳統基於規則的方法有侷限,開發AI輔助模型成關鍵
面對上述挑戰,謝沛錫提供了他們的解決方法,同時也說明早期設想的作法,並不足以解決問題。
例如,若使用傳統基於規則的方法,普遍都是針對英文語系而來,在中文、日文等複雜語言的處理上較少,主要也是不好維護。
而基於RAG的檢索模型,將文本放入資料庫後,RAG系統通常根據語意相似度檢索與問題最相關的文本,但系統可能檢索出字面相似但時間區間不符的文本,造成對時間相關的查詢表現不佳。
因此,他們想到的作法,是要打造時間檢索機制,去年9月他們已經完成這方面解決方案,以Llama3 - 8B為基礎,開發出自家CyTix模型並搭配聚焦於時間的RAG,並讓自家生成式AI服務都能用這一套機制。
如何克服正確判讀時間範圍,解決時間抽取與檢索的挑戰?謝沛錫指出,其核心AI模型CyTix是關鍵,效用是整合時間與語意檢索。
在運作流程上,首先,CyTix對於每個文件會先擷取其時間區段,接著,將此時間區段與文件一同存入資料庫分析,之後收到使用者查詢時,CyTix一開始會解析使用者關心的時間區間,最後,系統將根據時間符合度和語意相似度同時來檢索資料庫,以確保檢索精準,再將相關文本提供給LLM,以生成準確的回答。
特別的是,謝沛錫還向大家闡釋了他們CyTix模型的訓練方式,說明要訓練這樣的模型有兩大重點,第一,要建置資料集,包含單一時間點資料集和多時間點資料集,第二是將Llama 3 8B模型經過Supervised Fine-Tuning的方式,來訓練出CyTix模型。
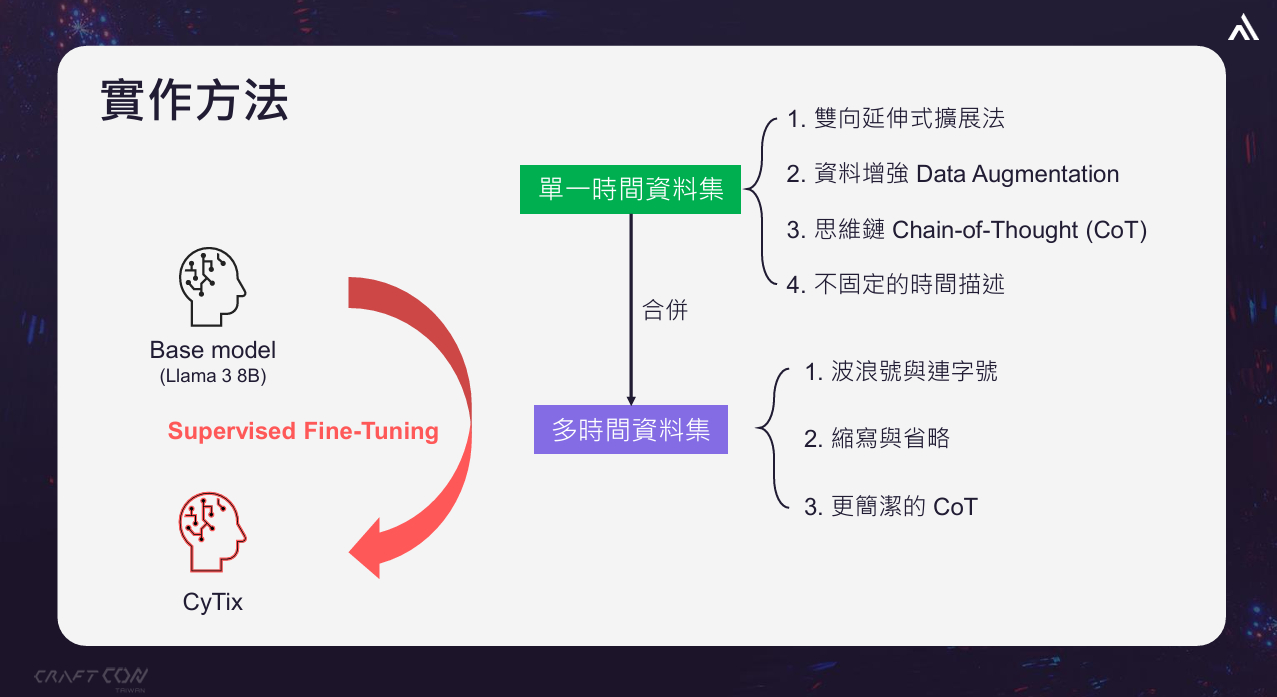
開發CyTix模型從6大實作步驟著手,涵蓋單一時間與多時間資料集
要如何擷取時間?謝沛錫解析了6種形式,前4種是針對單一時間資料集而來,後2種是屬於多時間資料集,這也就是他們的實作方法。
(一)雙向延伸式擴展法。這是使用正規表達式去雙向提取時間描述,謝沛錫以「去年8月至今」為例,此時將選出以月為最小單位,向前推導出8月1日,再向後推導出至今日的時間。
(二)資料增強(Data Augmentation)。這是因為有些描述方式雖然較為少見,但並非不會出現,因此必須讓模型接觸過各種可能的表達方式。例如,從過去到現在的寫法,包含:至今、迄今、到目前為止,從…到現在。其他還有像是上半年與下半年,年初與年末、第一季到第四季,日本年號「令和」等。另外還有一些副詞或連接詞可省略,以中文而言,最近三個月的「最」,以日文而言,先週の土曜日的「の」。
(三)固定格式思維鏈(Chain of Thought,CoT)」。謝沛錫指出這是CyTix的關鍵,藉此CoT引導模型逐步推理,而非直接給出答案。
例如,解析「上週四」時,模型會先列出關鍵詞,再拆解為年、月、星期等描述,最後逐步計算出具體日期,透過這種方法可以提高了推理的準確度,得到正確的開始時間與結束時間,使用get_time_specific的函式格式化時間資訊,方面後續處理。

(四)不固定時間的描述。這種方式在處理使用者輸入的問題時特別有用,因為使用者常常不知道要問什麼,如使用者輸入的「最近幾個月,此時模型可以切換模式,變成get_time_not_specific,模型會預測使用者想關注年或月,並由系統端自訂提供前幾個月或前幾年的資料。
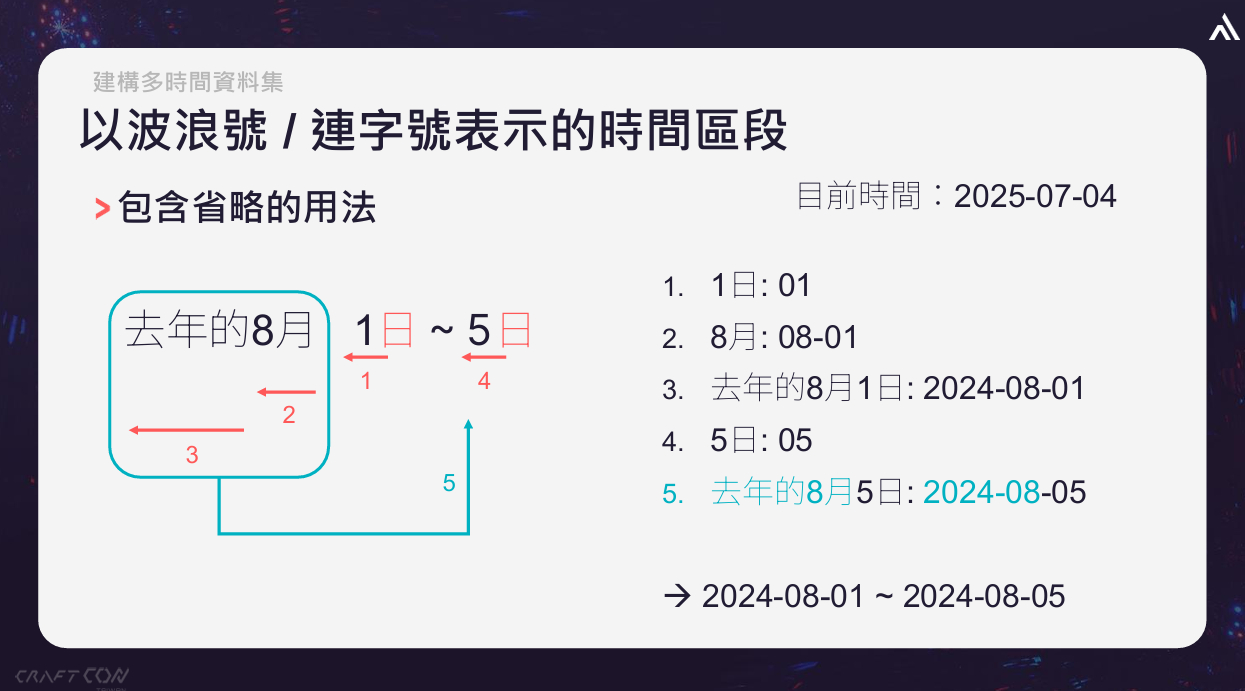
(五)波浪號與連字號、縮寫與省略。談完單一時間資料集,由於一句話中也會出現多個時間資訊的描述,因此合成多時間資料集也是不可或缺的一環。以去年8月1日~5日的描述為例,這裡就要讓模型能識別「5日」是指去年8月5日,要讓模型知道這種省略的用法
(六)更簡潔的CoT。這裡謝沛錫談到的是優化,他表示,在實際應用場景中,不是準就好,還要提升速度與穩定,他們致力於減少System Prompt長度,找出不需要的部分並實驗,進而減少了44%的Token使用量,此外,由於對於每個時間都要推論一次,他們針對多個時間,合併重複的推理步驟,減少38%的Token使用量。
最後,透過Supervised Fine-Tuning方式,將多時間資料庫學習起來,進而建構出他們的CyTix模型。另外,謝沛錫也強調,這雖然是以啟發式資料訓練,但仍具備超越訓練情境的泛化能力,可以解析不在訓練資料集出現的時間格式。
後續,他們也針對CyTix模型進行性能驗證,並指出CyTix作為專為時間任務設計的模型,在處理時間序列相關任務的表現上,能超越GPT-4o等第三方通用模型。此外,他們還推出CyTix-Light(基於 Qwen2.5-1.5B),能在單張RTX 3060以上等級的顯卡上運作執行,具備實際部署的可行性與應用價值。
整體而言,奧義智慧開發CyTix模型的經驗,不僅展現AI如何更好幫助解析資安報告,強調時間在資安報告中的價值,也能為國內其他投入AI與資安研究的團隊,提供重要的參考與借鏡。
