

At this year’s International Conference on Machine Learning (ICML2025), Unai Fischer-Abaigar, Christoph Kern and Juan Carlos Perdomo won an outstanding paper award for their work The Value of Prediction in Identifying the Worst-Off. We hear from Unai about the main contributions of the paper, why prediction systems are an interesting area for study, and further work they are planning in this space.
What is the topic of the research in your paper and why is it such an interesting area for study?
My work focuses on prediction systems used in public institutions to make high-stakes decisions about people. A central example is resource allocation, where institutions face limited capacity and must decide which cases to prioritize. Think of an employment office deciding which jobseekers are most at risk of long-term unemployment, a hospital triaging patients, or fraud investigators identifying cases most likely to warrant investigations.
More and more institutions are adopting AI tools to support their operations, yet the actual downstream value of these tools is not always clear. From an academic perspective, this gap points us to a fascinating aspect of researching algorithmic decision making systems because it pushes us to look beyond just the predictive algorithms. We need to study how these systems are designed, deployed, and embedded within broader decision-making processes. In our work, we ask: when are these predictive systems actually worth it from the perspective of a social planner interested in downstream welfare? Sometimes, instead of investing in making predictions more accurate, institutions might achieve greater benefits by expanding capacity, for example, hiring more caseworkers and processing more cases overall.
What are the main contributions of your work?
At a high level, we show that improvements in predictive accuracy are most valuable at the extremes:
- when there is almost no predictive signal to begin with, orwhen the system is already near-perfect.
But in the large middle ground, where institutions have some predictive signal but far from perfect accuracy, investing in capacity improvements tends to have a larger impact on the downstream utility, especially when institutional resources are very limited. In other words, if an institution faces tight resource constraints, it may be less important to perfectly match resources to the most urgent cases, and more important to expand the amount of help it can provide. We find these results through a simple theoretical model using a stylized linear setup and then confirm them empirically using real governmental data.
Could you give us an overview of your framework?
We make use of the Prediction-Access Ratio that was introduced in a previous work by one of my co-authors. This ratio compares the welfare gain from a small improvement in capacity with the gain from a small improvement in prediction quality. The intuition is that institutions rarely rebuild systems from scratch. They often consider marginal improvements with limited budgets. If the ratio is much larger than one, then an additional unit of capacity is far more valuable than an additional unit of predictive accuracy, and vice versa. We operationalize this idea by analyzing how marginal changes affect a value function that encodes downstream welfare for individuals at risk.
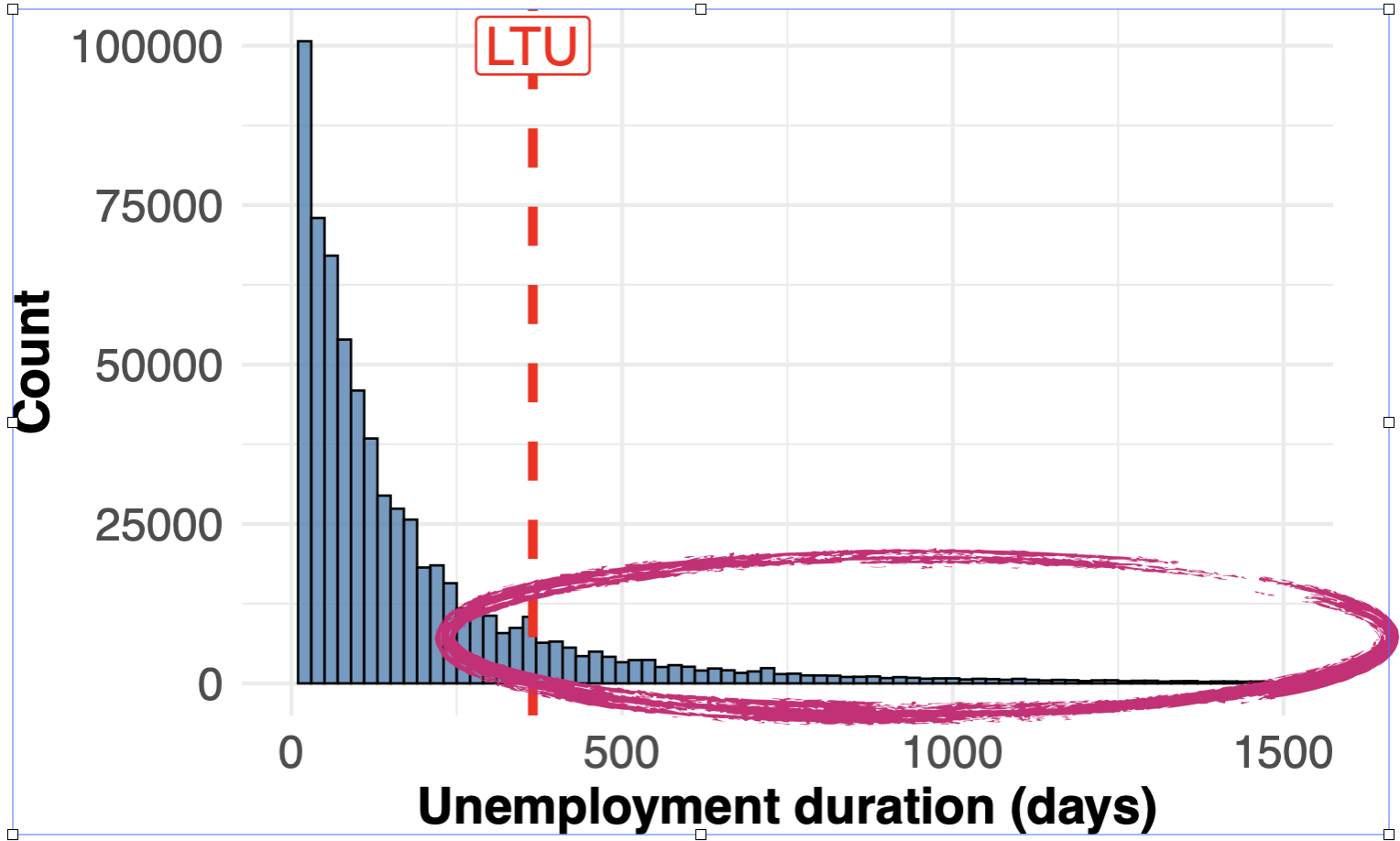 Unemployment duration. The red line marks the 12 month threshold used to classify a jobseeking episode as long-term unemployment in Germany.
Unemployment duration. The red line marks the 12 month threshold used to classify a jobseeking episode as long-term unemployment in Germany.
In the paper, you detail a case study identifying long-term unemployment in Germany. What were some of the main findings from this case study?
What stood out to us was that the theoretical insights also held up in the empirical data, even though the real-world setting does not match all the simplifying assumptions of the theory (for instance, distribution shifts are common in the real-world setting). In fact, the case study suggested that the regimes where capacity improvements dominate tend to be even larger in practice, and especially when considering non-local improvements.
What further work are you planning in this area?
I see this as a very promising research direction: how can we design algorithms that support good resource allocations in socially sensitive domains? Going forward, I want to further formalize what “good allocations” mean in practice and continue collaborating with institutions to ground the work in their real challenges. There are also many practical questions that matter: for example, how can we ensure that algorithms complement, rather than constrain, the discretion and expertise of caseworkers? More broadly, we need to think carefully about which parts of institutional processes can be abstracted into algorithmic systems, and where human judgment remains important.
About Unai
 | Unai Fischer Abaigar is a PhD student in Statistics at LMU Munich and a member of the Social Data Science and AI Lab, supported by the Konrad Zuse School for Excellence in Reliable AI and the Munich Center for Machine Learning. In 2024, he was a visiting fellow at Harvard’s School of Engineering and Applied Sciences. He holds a Bachelor’s and Master’s degree in Physics from Heidelberg University and previously worked at the Hertie School Data Science Lab in Berlin. |
Read the work in full
The Value of Prediction in Identifying the Worst-Off, Unai Fischer-Abaigar, Christoph Kern and Juan Carlos Perdomo.
