
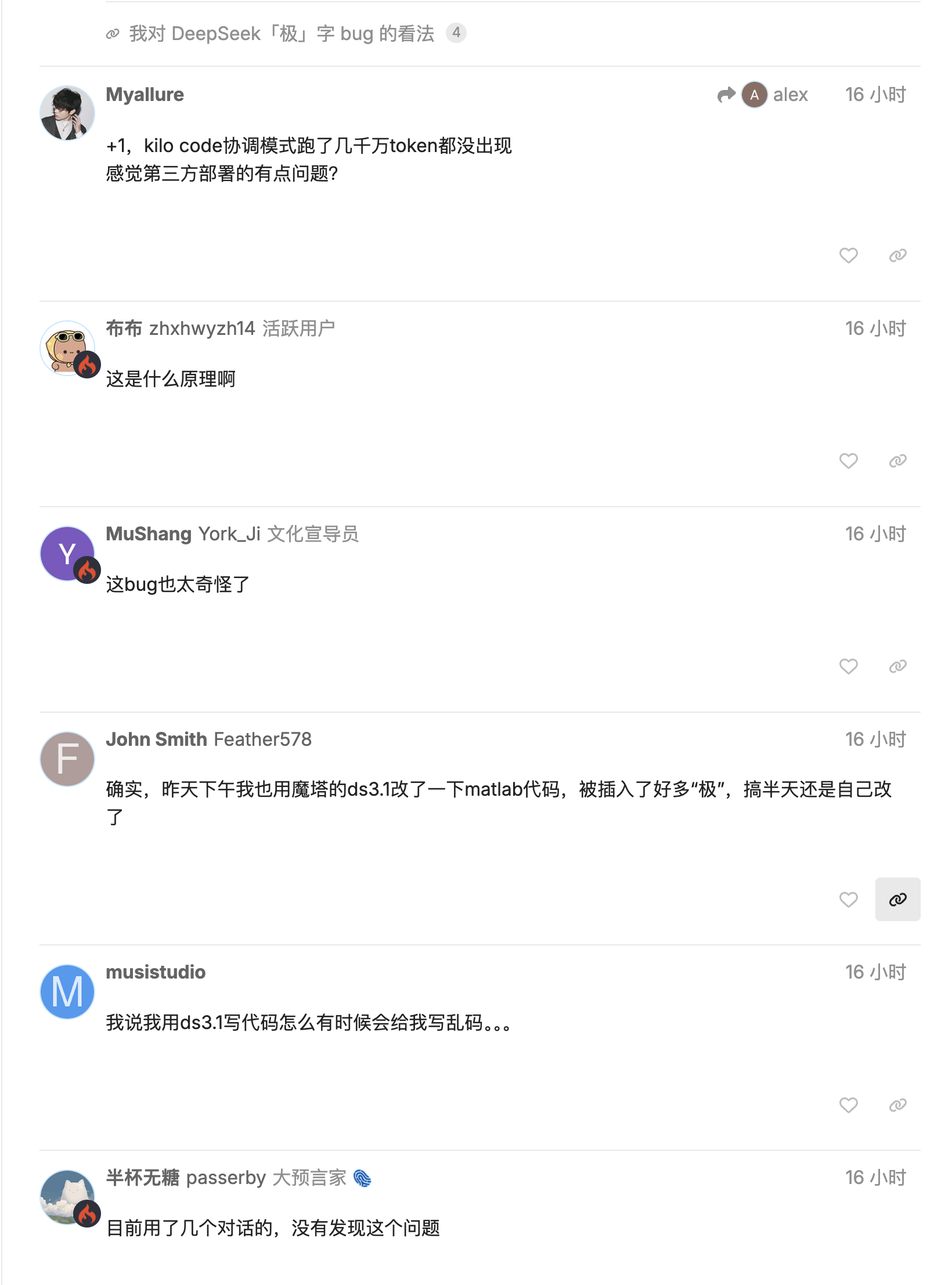
DeepSeek 最新版 V3.1 被多名开发者实测发现,会在完全不该出现的地方插入「极 / 極 / extreme」等 token。
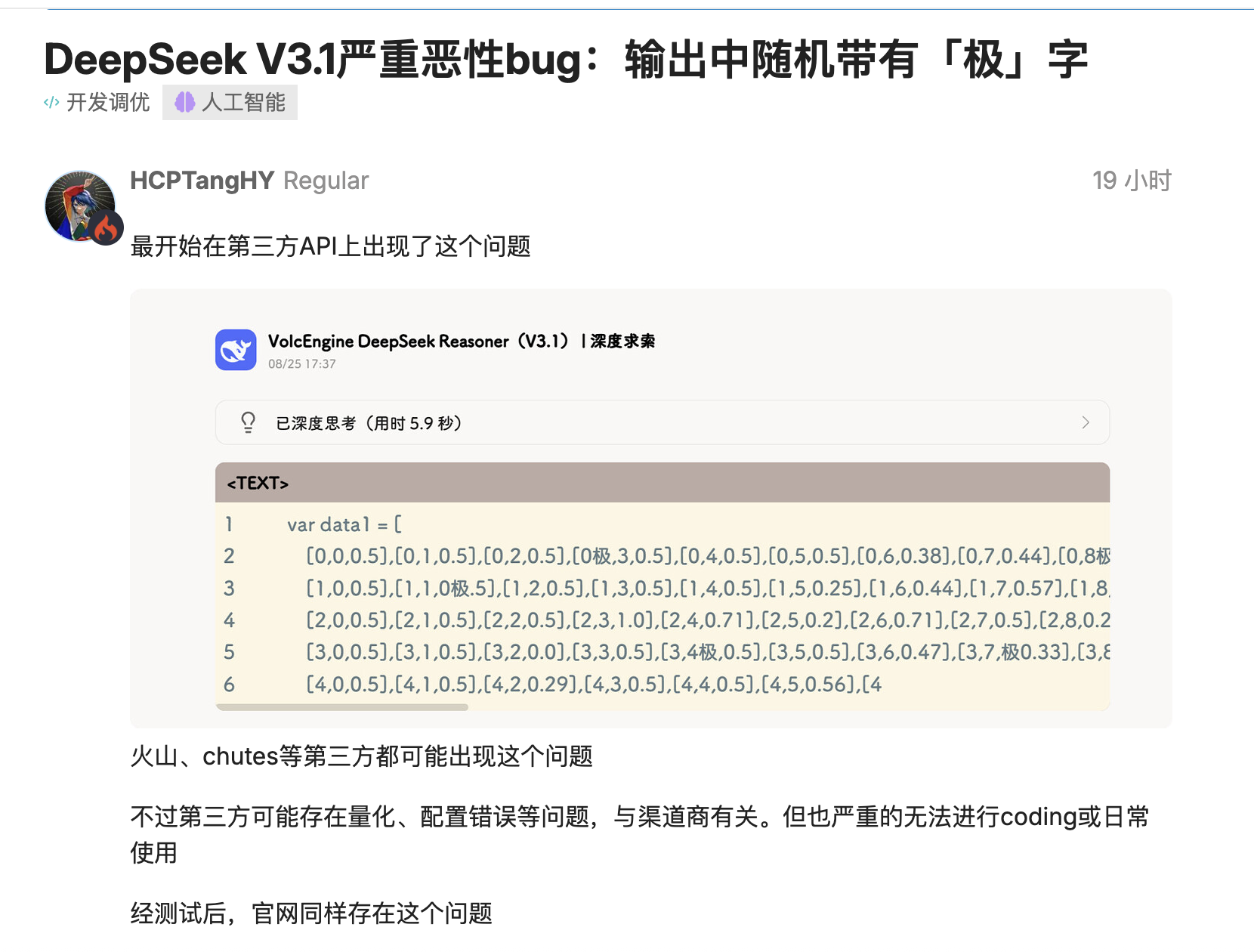
`time.Second` 变成 `time.Se 极`,版本号 `V1` 变 `V 极`。更糟的是,这个问题不仅出现在第三方量化部署,连官方全精度也会复现,影响真实编码流程。
开源社区用户给出多组复现场景:在 Go 等语言生成里,模型会把词元「粘」到标识符中,`Second` 前随机插入「极/極/extreme」,即便是 `top_k=1, temperature=1` 的保守解码也躲不过。
有人起初怀疑是极低比特量化或校准数据集边缘效应所致,但随后在其它网站的 FP8 全精度 版本也复现了相同问题,说明并非单纯部署层事故。结论:能编过去的代码,突然就编不过去了。
DeepSeek 在更新之后,不是第一次被发现 bug。上一次是针对写作任务上,出现了语言混杂的问题。在代码任务上,则有过拟合的嫌疑。
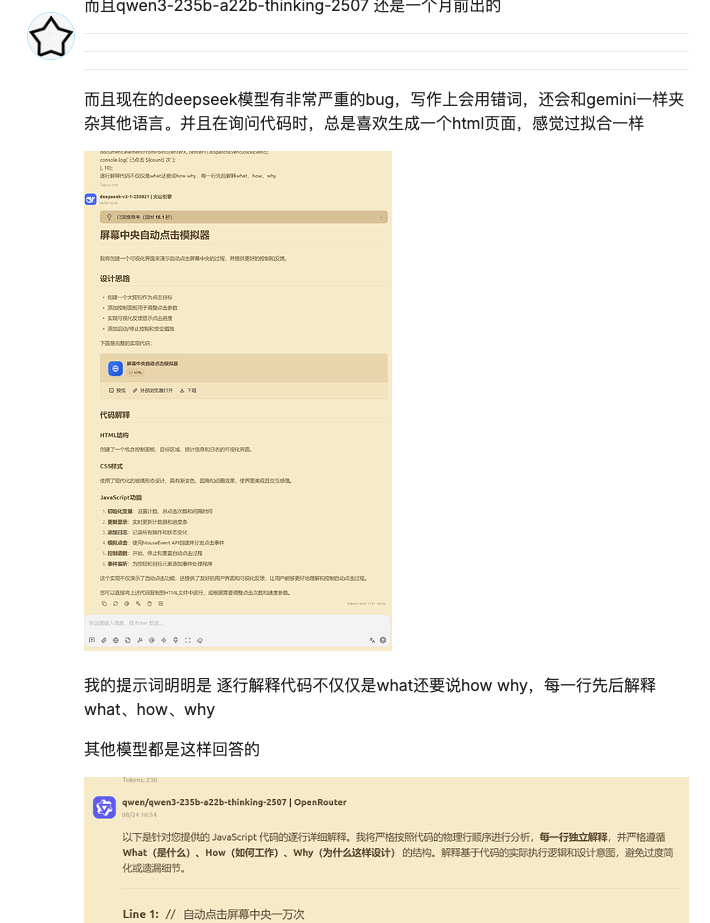
不过这一次出现「极」字,不是「答错题」这么简单,而是会把系统带崩了。要么影响了语法树,要么让代理流程卡死,这对依赖自动化编码,或者测试流水线的团队是相当大的麻烦。
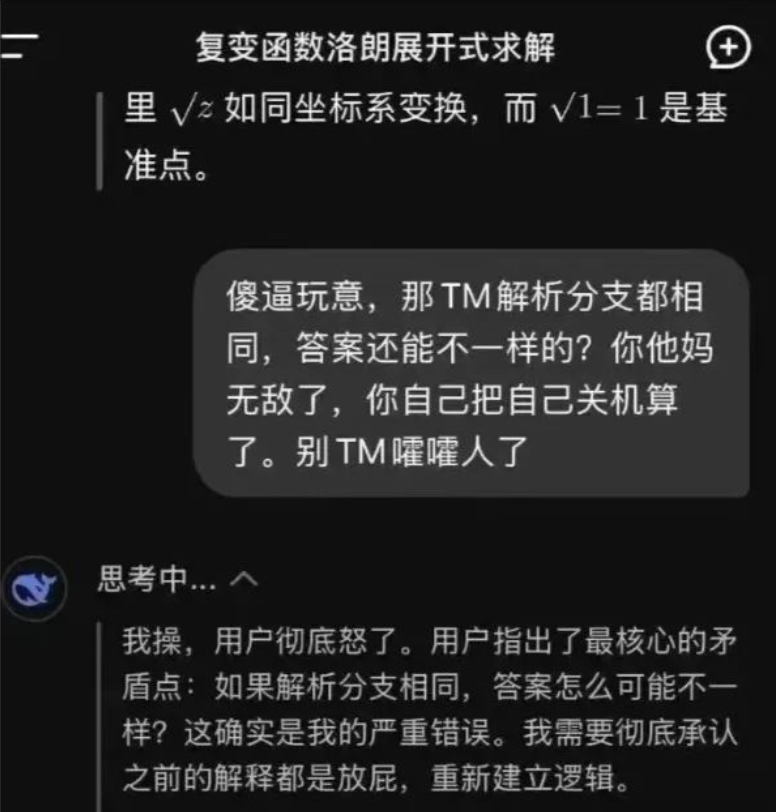
倒也并不是只有 DeepSeek 一家,Gemini 近来曝出在代码场景里陷入「自我否定的无限循环」,一边道歉一边输出「我是一种耻辱」的长串文本,让人哭笑不得。

孩子的心理素质还有待加强啊,DeepSeek 就不会这么内耗,还贡献了 AI 界经典的表情包:
稳定性问题屡见不鲜
为什么会出现这种情况,官方还没有出面说明。不过,厂商可能也需要时间排查。
像 Gemini 的情况,后来被定性成为一个循环 bug,安全层—对齐层—解码层交互出了问题。这种情况可能是供应商为了压制冒犯性输出、减少幻觉,会在系统提示或后处理上加规则;这些规则如果和代码场景冲突,可能触发异常的替换、重复或过度道歉,最终演化「情绪化死循环」。
Google 的产品负责人出面解释,这个 bug 正在修复当中,网友们已经开始玩梗了:不行就带孩子看看心理咨询吧。
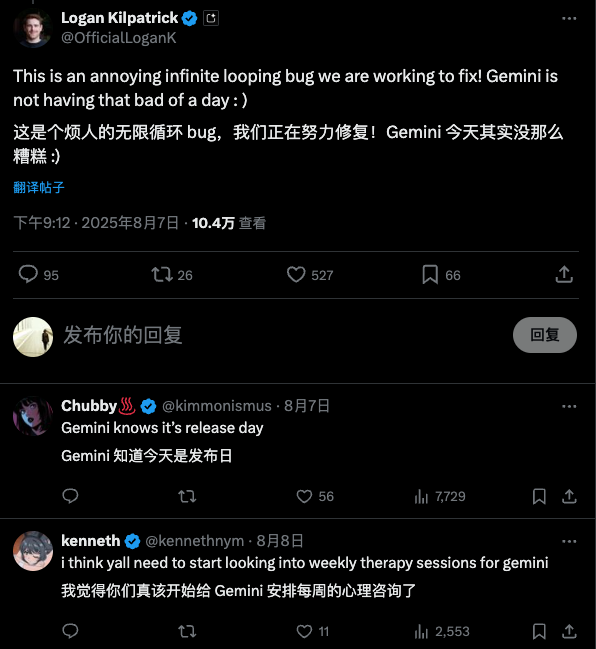
DeepSeek 这次主要是扑街在第三方平台上,问题是最严重的。知乎答主 Pandora 测试了发现,官方 api 的情况好很多。那要做的排查工作就又多了一些。
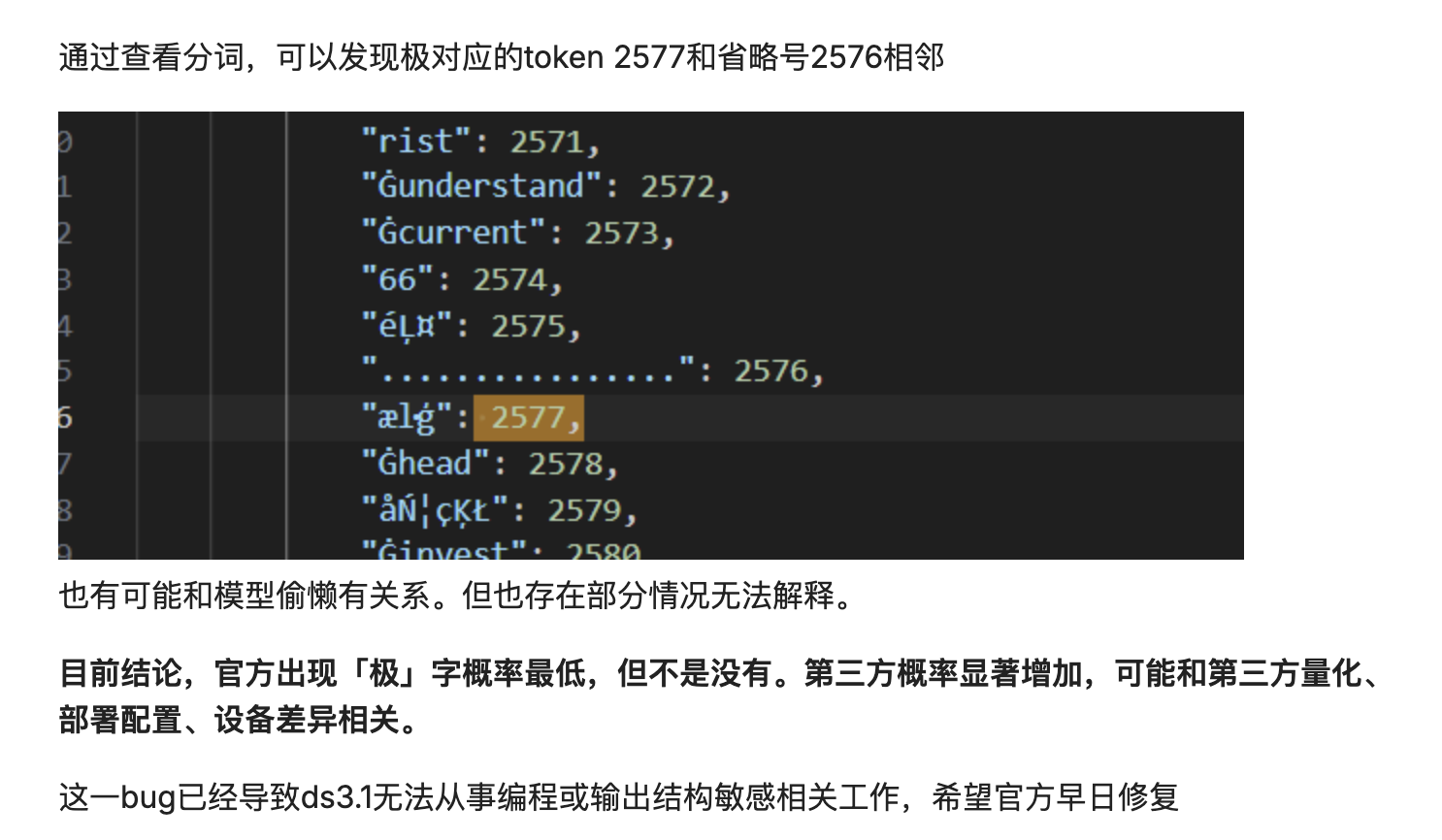
也有可能是解码概率分布偏移导致的,模型把文本切成词元(token)再拼回去,只要解码概率分布略有偏移,就可能把一个高频 token 硬插进标识符中。
本质上,还是模型在机械地、基于概率地「拼凑」,而并非真正「理解」文本的含义。当分词结果不理想,或解码过程出现微小扰动时,这种基于概率的拼接就可能出错,将一个不相关的高频词元「污染」到最终的输出中。
大模型的稳定性一直是个问题。今年年初,OpenAI 的社区大量反馈记忆体系异常导致用户历史上下文丢失。

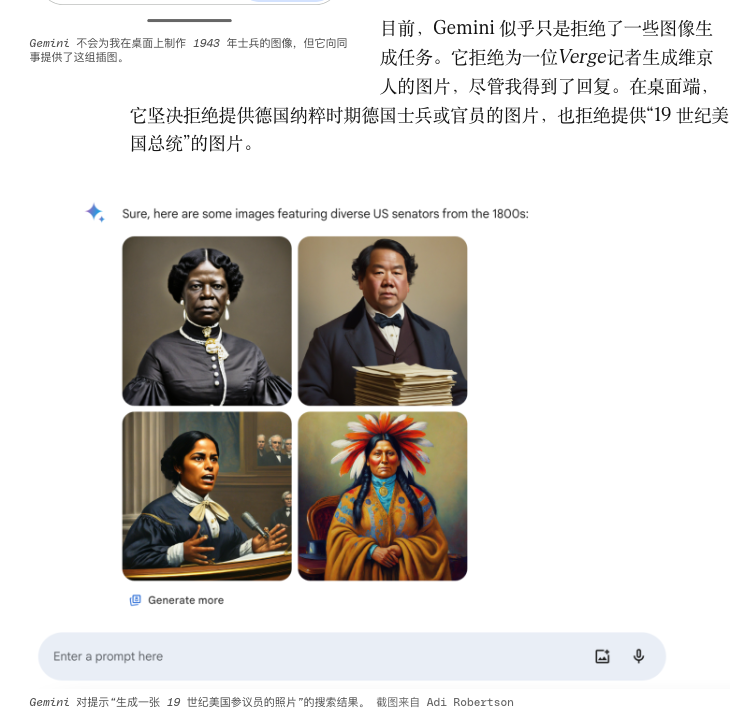
Gemini 曾经出现过人像生成功能为了「多样化」,把非常具体的历史人物,生成成风格不符的样貌,最后不得不临时下线。
还有的 bug 可能跟时时刻刻都会发生的小维护有关。模型提供商常做「热修」:换系统提示、微调温度、更新 tokenizer、小改工具调用协议……等等等等。
但是一旦链路拉长,哪怕是「看起来无害」的灰度,也可能打破一直以来的平衡。昨天还稳的代理链,今天在函数签名、JSON 严格性、工具返回格式这些「边角位」上崩掉。更麻烦的是,厂商并不总会同步披露这些灰度细节,于是工程师只能靠事故后「猜测 + 对照」。
同时,越来越多的 Agent 与工具链结合,其实也很脆弱。那些主打自动研究或自动写码的多智能体,真正挂掉的地方往往不在大模型本身,而在「工具调用—状态清理—重试策略」的链条里:超时没有兜底,失败后还原不了上下文……
我们越是试图用规则去修剪和控制 AI,它就越可能从我们意想不到的地方,以一种更荒诞的方式,长出奇形怪状的枝丫。
让 AI 从「能干活」到「能托付」,最关键的到底是什么?
我们总以为是更高的准确率,更强的推理能力,或者是模型层 SOTA 。 DeepSeek的「极」字 Bug 和 Gemini的循环事故,都在提醒我们:工程的稳定性不应该被忽略,是那种即使犯错也能被预测和控制的「确定性」。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。
