
Imagine harnessing the power of 72 cutting-edge NVIDIA Blackwell GPUs in a single system for the next wave of AI innovation, unlocking 360 petaflops of dense 8-bit floating point (FP8) compute and 1.4 exaflops of sparse 4-bit floating point (FP4) compute. Today, that’s exactly what Amazon SageMaker HyperPod delivers with the launch of support for P6e-GB200 UltraServers. Accelerated by NVIDIA GB200 NVL72, P6e-GB200 UltraServers provide industry-leading GPU performance, network throughput, and memory for developing and deploying trillion-parameter AI models at scale. By seamlessly integrating these UltraServers with the distributed training environment of SageMaker HyperPod, organizations can rapidly scale model development, reduce downtime, and simplify the transition from training to large-scale deployment. With the automated, resilient, and highly scalable machine learning infrastructure of SageMaker HyperPod, organizations can seamlessly distribute massive AI workloads across thousands of accelerators and manage model development end-to-end with unprecedented efficiency. Using SageMaker HyperPod with P6e-GB200 UltraServers marks a pivotal shift towards faster, more resilient, and cost-effective training and deployment for state-of-the-art generative AI models.
In this post, we review the technical specifications of P6e-GB200 UltraServers, discuss their performance benefits, and highlight key use cases. We then walk though how to purchase UltraServer capacity through flexible training plans and get started using UltraServers with SageMaker HyperPod.
Inside the UltraServer
P6e-GB200 UltraServers are accelerated by NVIDIA GB200 NVL72, connecting 36 NVIDIA Grace CPUs and 72 Blackwell GPUs in the same NVIDIA NVLink domain. Each ml.p6e-gb200.36xlarge compute node within an UltraServer includes two NVIDIA GB200 Grace Blackwell Superchips, each connecting two high-performance NVIDIA Blackwell GPUs and an Arm-based NVIDIA Grace CPU with the NVIDIA NVLink chip-to-chip (C2C) interconnect. SageMaker HyperPod is launching P6e-GB200 UltraServers in two sizes. The ml.u-p6e-gb200x36 UltraServer includes a rack of 9 compute nodes fully connected with NVSwitch (NVS), providing a total of 36 Blackwell GPUs in the same NVLink domain, and the ml.u-p6e-gb200x72 UltraServer includes a rack-pair of 18 compute nodes with a total of 72 Blackwell GPUs in the same NVLink domain. The following diagram illustrates this configuration.
CPUs and 72 Blackwell GPUs in the same NVIDIA NVLink domain. Each ml.p6e-gb200.36xlarge compute node within an UltraServer includes two NVIDIA GB200 Grace Blackwell Superchips, each connecting two high-performance NVIDIA Blackwell GPUs and an Arm-based NVIDIA Grace CPU with the NVIDIA NVLink chip-to-chip (C2C) interconnect. SageMaker HyperPod is launching P6e-GB200 UltraServers in two sizes. The ml.u-p6e-gb200x36 UltraServer includes a rack of 9 compute nodes fully connected with NVSwitch (NVS), providing a total of 36 Blackwell GPUs in the same NVLink domain, and the ml.u-p6e-gb200x72 UltraServer includes a rack-pair of 18 compute nodes with a total of 72 Blackwell GPUs in the same NVLink domain. The following diagram illustrates this configuration.
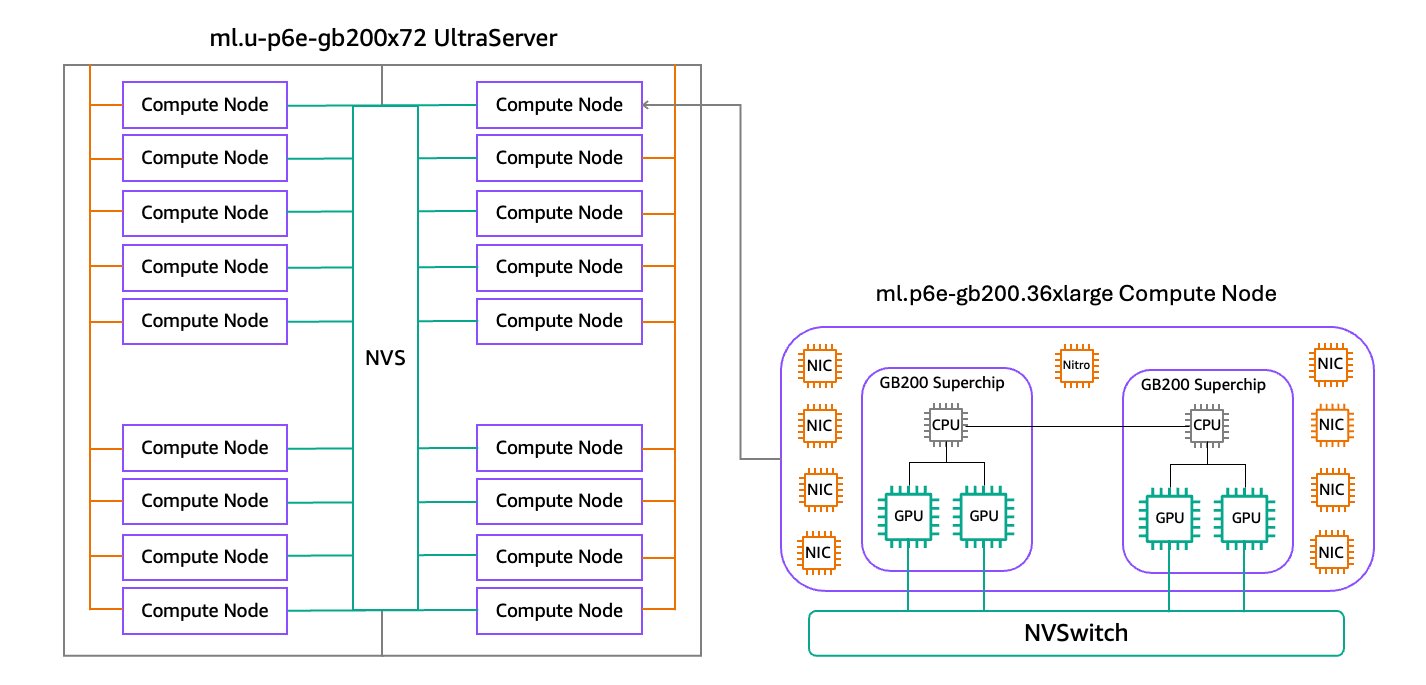
Performance benefits of UltraServers
In this section, we discuss some of the performance benefits of UltraServers.
GPU and compute power
With P6e-GB200 UltraServers, you can access up to 72 NVIDIA Blackwell GPUs within a single NVLink domain, with a total of 360 petaflops of FP8 compute (without sparsity), 1.4 exaflops of FP4 compute (with sparsity) and 13.4 TB of high-bandwidth memory (HBM3e). EachGrace Blackwell Superchip pairs two Blackwell GPUs with one Grace CPU through the NVLink-C2C interconnect, delivering 10 petaflops of dense FP8 compute, 40 petaflops of sparse FP4 compute, up to 372 GB HBM3e, and 850GB of cache-coherent fast memory per module. This co-location boosts bandwidth between GPU and CPU by an order of magnitude compared to previous-generation instances. Each NVIDIA Blackwell GPU features a second-generation Transformer Engine and supports the latest AI precision microscaling (MX) data formats such as MXFP6 and MXFP4, as well as NVIDIA NVFP4. When combined with frameworks like NVIDIA Dynamo, NVIDA TensorRT-LLM and NVIDIA NeMo, these Transformer Engines significantly accelerate inference and training for large language models (LLMs) and Mixture-of-Experts (MoE) models, supporting higher efficiency and performance for modern AI workloads.
High-performance networking
P6e-GB200 UltraServers deliver up to 130 TBps of low-latency NVLink bandwidth between GPUs for efficient large-scale AI workload communication. At double the bandwidth of its predecessor, the fifth-generation NVIDIA NVLink provides up to 1.8 TBps of bidirectional, direct GPU-to-GPU interconnect, greatly enhancing intra-server communication. Each compute node within an UltraServer can be configured with up to 17 physical network interface cards (NICs), each supporting up to 400 Gbps of bandwidth. P6e-GB200 UltraServers provide up to 28.8 Tbps of total Elastic Fabric Adapter (EFA) v4 networking, using the Scalable Reliable Datagram (SRD) protocol to intelligently route network traffic across multiple paths, providing smooth operation even during congestion or hardware failures. For more information, refer to EFA configuration for a P6e-GB200 instances.
Storage and data throughput
P6e-GB200 UltraServers support up to 405 TB of local NVMe SSD storage, ideal for large-scale datasets and fast checkpointing during AI model training. For high-performance shared storage, Amazon FSx for Lustre file systems can be accessed over EFA with GPUDirect Storage (GDS), providing direct data transfer between the file system and the GPU memory with TBps of throughput and millions of input/output operations per second (IOPS) for demanding AI training and inference.
Topology-aware scheduling
Amazon Elastic Compute Cloud (Amazon EC2) provides topology information that describes the physical and network relationships between instances in your cluster. For UltraServer compute nodes, Amazon EC2 exposes which instances belong to the same UltraServer, so you’re training and inference algorithms can understand NVLink connectivity patterns. This topology information helps optimize distributed training by allowing frameworks like the NVIDIA Collective Communications Library (NCCL) to make intelligent decisions about communication patterns and data placement. For more information, see How Amazon EC2 instance topology works.
With Amazon Elastic Kubernetes Service (Amazon EKS) orchestration, SageMaker HyperPod automatically labels UltraServer compute nodes with their respective AWS Region, Availability Zone, Network Node Layers (1–4), and UltraServer ID. These topology labels can be used with node affinities, and pod topology spread constraints to assign Pods to cluster nodes for optimal performance.
With Slurm orchestration, SageMaker HyperPod automatically enables the topology plugin and creates a topology.conf file with the respective BlockName, Nodes, and BlockSizes to match your UltraServer capacity. This way, you can group and segment your compute nodes to optimize job performance.
Use cases for UltraServers
P6e-GB200 UltraServers can efficiently train models with over a trillion parameters due to their unified NVLink domain, ultrafast memory, and high cross-node bandwidth, making them ideal for state-of-the-art AI development. The substantial interconnect bandwidth makes sure even extremely large models can be partitioned and trained in a highly parallel and efficient manner without the performance setbacks seen in disjointed multi-node systems. This results in faster iteration cycles and higher-quality AI models, helping organizations push the boundaries of state-of-the-art AI research and innovation.
For real-time trillion-parameter model inference, P6e-GB200 UltraServers enable 30 times faster inference on frontier trillion-parameter LLMs compared to prior platforms, achieving real-time performance for complex models used in generative AI, natural language understanding, and conversational agents. When paired with NVIDIA Dynamo, P6e-GB200 UltraServers deliver significant performance gains, especially for long context lengths. NVIDIA Dynamo disaggregates the compute-heavy prefill phase and the memory-heavy decode phase onto different GPUs, supporting independent optimization and resource allocation within the large 72-GPU NVLink domain. This enables more efficient management of large context windows and high-concurrency applications.
P6e-GB200 UltraServers offer substantial benefits to startup, research, and enterprise customers with multiple teams that need to run diverse distributed training and inference workloads on shared infrastructure. When used in conjunction with SageMaker HyperPod task governance, UltraServers provide exceptional scalability and resource pooling, so different teams can launch simultaneous jobs without bottlenecks. Enterprises can maximize infrastructure utilization, reduce overall costs, and accelerate project timelines, all while supporting the complex needs of teams developing and serving advanced AI models, including massive LLMs for high-concurrency real-time inference, across a single, resilient platform.
Flexible training plans for UltraServer capacity
SageMaker AI currently offers P6e-GB200 UltraServer capacity through flexible training plans in the Dallas AWS Local Zone (us-east-1-dfw-2a). UltraServers can be used for both SageMaker HyperPod and SageMaker training jobs.
To get started, navigate to the SageMaker AI training plans console, which includes a new UltraServer compute type, from which you can select your UltraServer type: ml.u-p6e-gb200x36 (containing 9 ml.p6e-gb200.36xlarge compute nodes) or ml.u-p6e-gb200x72 (containing 18 ml.p6e-gb200.36xlarge compute nodes).
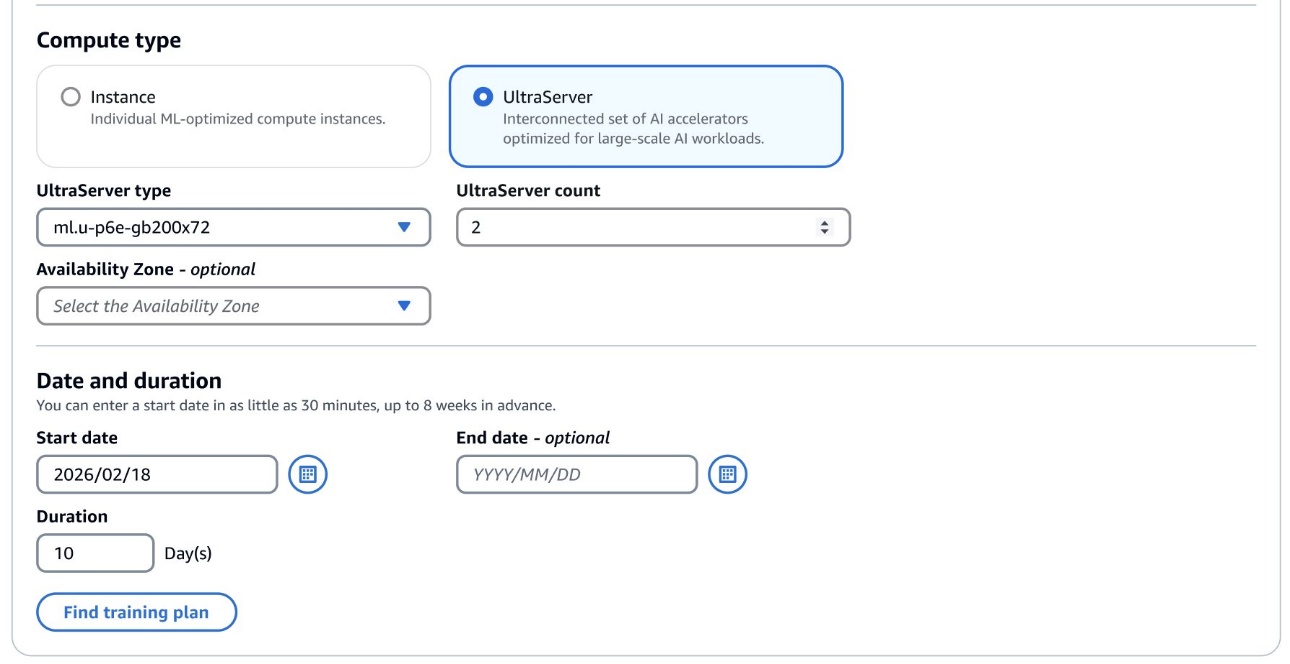
After finding the training plan that fits your needs, it is recommended that you configure at least one spare ml.p6e-gb200.36xlarge compute node to make sure faulty instances can be quickly replaced with minimal disruption.

Create an UltraServer cluster with SageMaker HyperPod
After purchasing an UltraServer training plan, you can add the capacity to an ml.p6e-gb200.36xlarge type instance group within your SageMaker HyperPod cluster and specify the quantity of instances that you want to provision up to the amount available within the training plan. For example, if you purchased a training plan for one ml.u-p6e-gb200x36 UltraServer, you could provision up to 9 compute nodes, whereas if you purchased a training plan for one ml.u-p6e-gb200x72 UltraServer, you could provision up to 18 compute nodes.
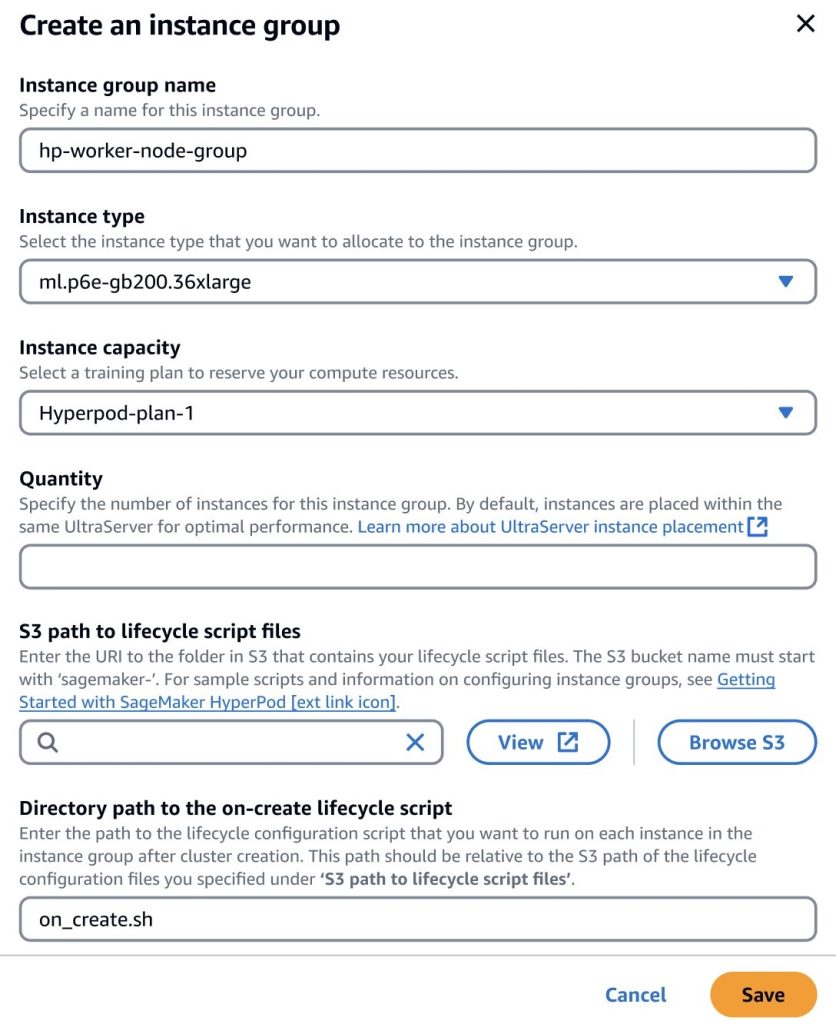
By default, SageMaker will optimize the placement of instance group nodes within the same UltraServer so that GPUs across nodes are interconnected within the same NVLink domain to achieve the best data transfer performance for your jobs. For example, if you purchase two ml.u-p6e-gb200x72 UltraServers with 17 compute nodes available each (assuming you configured two spares), then create an instance group with 24 nodes, the first 17 compute nodes will be placed on UltraServer A, and the other 7 compute nodes will be placed on UltraServer B.
Conclusion
P6e-GB200 UltraServers help organizations train, fine-tune, and serve the world’s most ambitious AI models at scale. By combining extraordinary GPU resources, ultrafast networking, and industry-leading memory with the automation and scalability of SageMaker HyperPod, enterprises can accelerate the different stages of the AI lifecycle, from experimentation and distributed training through seamless inference and deployment. This powerful solution breaks new ground in performance and flexibility and reduces operational complexity and costs, so that innovators can unlock new possibilities and lead the next era of AI advancement.
About the authors
 Nathan Arnold is a Senior AI/ML Specialist Solutions Architect at AWS based out of Austin Texas. He helps AWS customers—from small startups to large enterprises—train and deploy foundation models efficiently on AWS. When he’s not working with customers, he enjoys hiking, trail running, and playing with his dogs.
Nathan Arnold is a Senior AI/ML Specialist Solutions Architect at AWS based out of Austin Texas. He helps AWS customers—from small startups to large enterprises—train and deploy foundation models efficiently on AWS. When he’s not working with customers, he enjoys hiking, trail running, and playing with his dogs.
