
Published on August 11, 2025 7:32 PM GMT
Introduction
In May, we started doing full-time work for Aether, our independent LLM agent safety research group. We’re excited to share an overview of our two kickoff weeks! We found them useful, and we hope that other groups starting research projects will find this post helpful for figuring out a shared research agenda and good research practices.
In short, our most important takeaway from the kickoff weeks was that it’s great to be on the same page with your research collaborators about many things, and the following activities are useful for this:
- Meta-research discussions helped us be on the same page about how to do good research.A broad AI safety overview and TAIS portfolio mapping helped us be on the same page about what work seems neglected and important in AI safety.Project management planning helped us be on the same page about efficient shared workflows.Vision brainstorming and goal-setting helped us be on the same page about our collective and individual goals for Aether.
Schedules
We made planned weekly schedules on an iPad:

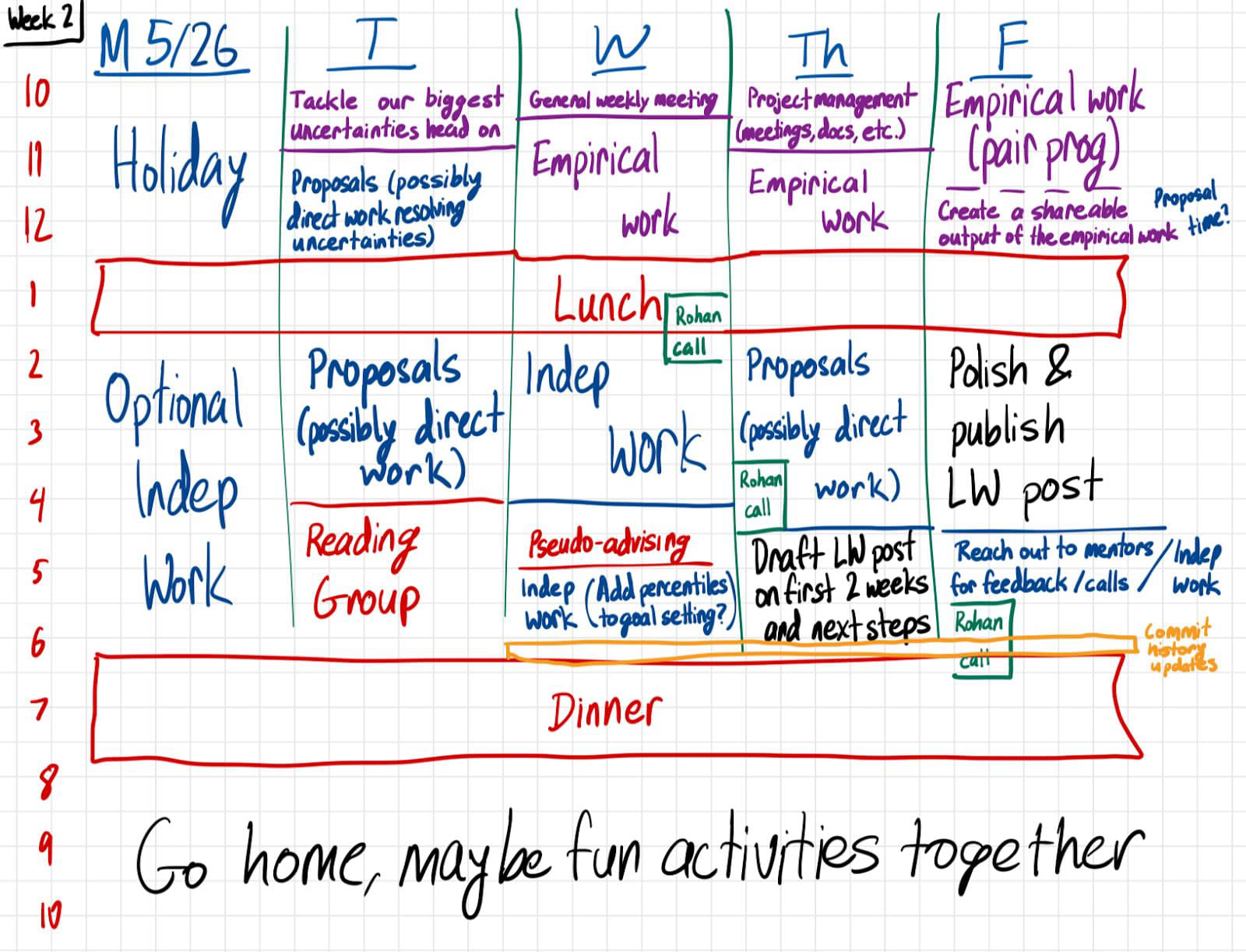
We mostly stuck to these plans (with a few exceptions—we originally intended to publish this post in Week 2 at the end of May…).
Activities
Motivation
A large chunk of our time was spent on exploring research directions (both conceptually and empirically) to find the most important directions to focus on.
Most of the other activities shared a common motivation: There are numerous factors that can influence what to prioritize while doing research, and by talking about many of those factors early on, we developed a shared vocabulary that makes it easier to consistently recognize and discuss important decision-relevant considerations. For instance:
- “I don’t think that direction would help us achieve the vision we laid out” (vision brainstorming)“We’ve been violating a meta-research principle we liked, we should correct that” (meta-research)“I don’t think that direction is neglected” (broad AIS overview, portfolio mapping)“We’re a bit behind schedule for one of the goals we set, let’s prioritize that this week” (goal-setting)
Exploring research proposals
Our process for exploring research proposals involved three main activities:
- Reading existing research agendas, prioritization arguments, and related papers;Coming up with new project proposals through conceptual brainstorming; andDoing quick empirical explorations of promising projects.
These activities were highly intertwined and took up most of our time. This process concluded with us writing up a concrete research agenda focused on enhancing the monitorability of LLM agents.
Reading
Our reading focused on the following broad categories:
- LLM chain-of-thought monitorability
- We had a couple of project proposals already before the kickoff week related to monitorability that both we and our advisors were excited about. Expanding upon those ideas was a natural place to begin the brainstorming process.Example readings include Prover-Verifier Games improve legibility of LLM outputs by Kirchner et al. and Daniel Kokotajlo’s list of ideas for improving CoT faithfulness.
- The motivation of those readings was to better inform ourselves about the state of the field to ensure that our research ideas target urgent and neglected problems.Some example readings include DeepSeek-R1 Thoughtology by Marjanovic et al. and Absolute Zero: Reinforced Self-play Reasoning with Zero Data by Zhao et al.
- Here, our motivation was to get a better overview of current work in alignment to get inspiration for our own proposals while also gaining a better sense of what other people are working on to avoid duplicating their work.Representative readings include recent project proposals by Redwood Research, listed in this comment by Ryan Greenblatt, and Anthropic’s progress report on synthetic document finetuning.
- We believe that it is important for every alignment research group to think hard about which kinds of projects might be automated within the next couple of years and to take that into account in the project prioritization process. We decided that focusing on automating alignment work ourselves isn’t our comparative advantage, but nevertheless found the readings worthwhile.Example readings include We should try to automate AI safety work asap by Marius Hobbhahn and AlphaEvolve: A coding agent for scientific and algorithmic discovery by Novikov et al.
We took notes throughout the process and have made them public in this document. Since the kickoff week, we have continued doing structured reading in a weekly two hour reading group with MATS scholars, which has been quite productive.
Conceptual brainstorming
Our activities for conceptual brainstorming can be decomposed into the following subtasks:
- Identifying gaps in the readings we did and thinking about possible ways to bridge those gaps,Thinking about the theories of change for initial ideas to figure out whether it might be worth converting them into full project proposals,Iterating on our existing proposals by discussing key questions and bottlenecks with each other, by asking external people for feedback, and through independent work, andFinding connections between existing proposals and merging them into a more comprehensive research agenda.
An important decision for us was to decide whether to approach project choice by generating several proposals that we feel excited about and quickly choosing one or two that look the most promising to us or whether to form a broad agenda, do experiments across it, and let a more narrow project coalesce from that. We decided in favor of the latter approach, for the following reasons:
- We had various ideas that look promising, and it was difficult to pick the most promising one based solely on a priori thinking about the theory of change, neglectedness, and tractability. By keeping many project ideas around for the empirical phase, we hoped to gain multiple new sources of information to base the decision on, especially empirical feedback on tractability of projects.
- In retrospect, we probably spent too long with too many projects around, and didn’t do enough empirical exploration to update quickly. But it is also easy to focus too much on starting direct work at the expense of impactful project selection. We are fairly happy with the project directions we are pursuing now related to measuring and improving CoT monitoring in AI control settings, but we are still unsure what the right balance is between conceptual project brainstorming and diving into direct work. This seems like a central challenge in impact-driven research generally, and if anyone has advice for striking the right balance, we would love to hear it.
- We wrote two research agenda documents soon after the kickoff weeks, and our CoT Monitorability agenda is still a good representation of our broad focus, so this went fairly well.
To keep track of the changes to our thinking about the prioritization of different proposals, we have kept a “commit history” document where we write a quick overview on both empirical and conceptual progress on the proposals every few days. This has been moderately useful for helping us take stock of our current status at various points.
Empirical exploration
We set aside one full day in week one for a mini-hackathon, with a couple hours earlier in the week dedicated to planning the activities for that coding sprint. We decided to work on training a model organism of obfuscated reasoning using RL; this was intended both to explore a research proposal for increasing CoT legibility, and as a good exercise to learn empirical skills and workflows as a group.
We dealt with many package management and Git issues during the mini-hackathon, and only made a little progress on editing the codebase we cloned for our purposes. In Week 2, we spent three mornings on the same project; we started some runs locally and began setting up proper training runs on cloud GPUs.
Outside of the joint time specifically dedicated to empirical work, we spent some time independently trying to set up RL training with a length penalty to explore its effects on CoT legibility and to set up SFT to get models to engage in something resembling reflective goal-formation. The former was bottlenecked by RL challenges similar to the ones from the joint project; for the latter, we finetuned GPT-4.1-mini on simple data related to reflection, but (as we suspected in advance) this basic version did not yield much insight into how we might expect future models to reflect on their values if they start doing so in a sophisticated way.
Overall, it took us longer to see progress from empirical work than from conceptual exploration. We underestimated the difficulty of getting LLM RL runs working. In the weeks after the kickoff, we transitioned to spending more time on empirical work as we broke our high-level project ideas into tractable low-level steps. We think the balance we struck between conceptual and empirical work was reasonable, though doing a bit more empirical work would likely have yielded more useful results.
(We have since been happier with our empirical progress and recently published a post on how “extact-and-evaluate” monitoring can substantially improve chain-of-thought monitors. On the conceptual side, we plan to publish a taxonomy of types of hidden reasoning that may emerge in LLMs soon!)
Broad AI safety overview and technical AI safety portfolio mapping
We spent two hours on Day 1 creating a broad overview of as many concepts in AI safety as we could, and later spent an hour trying to map what work was being done by whom across the space.
The rough prompt we used to start the overview: List as many problems, approaches, subfields, and important uncertainties within AI safety as you can.
The prompts we used for portfolio mapping:
- Who is working on things related to our top projects?What is an optimal technical AI safety (TAIS) portfolio?What is the current TAIS portfolio?What are the biggest shortcomings of the current TAIS portfolio relative to the optimal one?How many people are working on TAIS right now? FTE? What are the orgs?
As you might imagine, we didn’t come to conclusive answers on many of these questions, but the exercises did surface various useful thoughts for us. Our overview and portfolio mapping are available in this document.
We don’t look at that doc frequently, and it’s hard to measure the value it provided to us as a group. Tentatively, we would guess that this was a worthwhile exercise because it helped us be more on the same page about the state of AI safety, which makes it easier to be on the same page at every step of project selection and execution.
Meta-research discussion
We spent 90 minutes writing about and discussing the following prompts:
- What are some existing meta-research resources that you think are very good? What do they recommend?How do you do good research?General tipsWhat are all the steps involved in a research project?How do you select a project to work on?What are the most important research skills in your field?
The document where we wrote up our thoughts is here and contains a great list of resources and general research tips. One concrete outcome was that we set aside an hour every week to identify our most important uncertainties and address them head on. More vaguely, this exercise also helped us be more on the same page about how to do good research, which makes it easier to be on the same page at every step of project selection and execution.
Vision brainstorming and goal-setting
We spent about 3 hours thinking about our vision for Aether and our goals for the first six months of working together. This involved two activities:
- Thinking about neglected problems in AI safety that don’t currently have an organization focusing on them, as well as about our own comparative advantages, andSetting specific and measurable goals, both for Aether as a whole and for each of us personally, and adding percentile forecasts for how we expect those goals to be fulfilled in six months’ time.
For the first part, we used the following guiding questions:
- How could Aether become an enduring, impactful AI safety org?What important effects on AI development should Aether aim to have?What’s the one-sentence mission for Aether?
- This would ideally be important, tractable, and neglected
- What are current funders looking to invest in?
As a result of working through these questions, we identified five broad questions we are interested in:
- How can we reduce the use of RL in ways that we think are likely to create misaligned goals (unconstrained exploration, reward hacking, goal misgeneralization)?How can the effectiveness of CoT monitoring be preserved for transformative AIs? How likely is it that the first transformative AIs don’t perform extended hidden serial reasoning?Will automated AI safety research be able to keep up with automated AI capabilities research?Labs seem to be aiming to have large organizations of AIs automate a lot of their research and work. What are the safety implications of large orgs of AIs? Are there tractable risk mitigations there?Will AGIs have very different instruction-following generalization or goals due to situational awareness? If so, how will this play out?
For the second part, a representative goal that we set for ourselves looks as follows: “Have a visible track record that contributes to important problems in alignment in our opinion and enables Aether to get more funding for 2026. The track record can consist of 1-2 ICLR papers, regular LW posts, and being known as a productive group in alignment circles in general.” We then wrote down what our 10th, 50th, and 90th percentile expectations for the outcome of this goal look like. These goals were another thing that it was helpful to be on the same page about.
Project management planning
We spent an hour discussing and updating our project management practices. Some of the topics we touched on included:
- How to track todosKeep track of all docs and links related to AetherHow to manage and track running costs (e.g. compute) during projectsWhat weekly meetings should be for and how we should prepare for themHow should we think about “lab notes” discord channels? When should we post in them?What best practices do we want to follow when collaborating together on a single GitHub repo? E.g. is it ever fine to push directly to main?What running docs should we continually keep in mind and use?How should we hold each other accountable / help each other get unstuck?
Takeaways:
- We agreed that we would post daily goals and progress in our respective [name]-lab-notes channels, along with any miscellaneous thoughtsWe also decided to write more detailed updates before our official weekly check-insWe made a centralized document with a list of all Aether-related linksFor many project management practices, there is a default no-effort version; in the interest of reducing friction, we went with this option for a tracking compute costs and tracking longer term todos
We have stuck to some (but not all) of our planned project management practices, and we don’t think we have had significant bottlenecks in our workflows, so we think this was useful.
Pseudo-advising
Pseudo-advising refers to meetings where people ask research questions to peers rather than actual advisors. We thought that this could be very valuable: sometimes, your peers have very helpful relevant knowledge, and even the act of thinking about what questions you might ask people can help you discover good subproblems to focus on.
Two categories of question the we think are good to ask in pseudo-advising include:
- Cheekily ambitious questions that are fun and motivating to discuss (e.g., “How do you select a research direction?”)Questions about research methodology, assuming anyone in the group might have the relevant expertise (e.g., “What benchmarks do people use to measure LLM agent capabilities?”)
We invited MATS extension scholars in London to join for this, and some did. Pseudo-advising ended up feeling fairly similar to conceptual project brainstorming at times, but of a different flavor that was probably good for generating fresh ideas.
We originally intended to do pseudo-advising weekly, but we reduced its frequency after not finding it reliably valuable. Sometimes, we’re bottlenecked by execution rather than conceptual questions, and sometimes we don’t have access to people who can answer our most pressing questions. We still like the two categories of question above and think that there are often useful things to get out of pseudo-advising.
Conclusion
We generally found these exercises useful and recommend them for other people starting research projects or groups!
If you’re interested in getting in touch with us or collaborating with Aether, please fill out this expression of interest form.
Discuss
