
OpenAI在最新的开源模型gpt-oss上采用的MXFP4数据类型,直接让推理成本暴降75%!
更惊人的是,MXFP4在把内存占用降为同规模BF16模型的四分之一的同时,还把生成token的速度提升了整整4倍。
换句话说,这一操作直接把1200亿参数的大模型塞进80GB显存的显卡,哪怕是只有16GB显存的显卡也能跑200亿参数的版本。
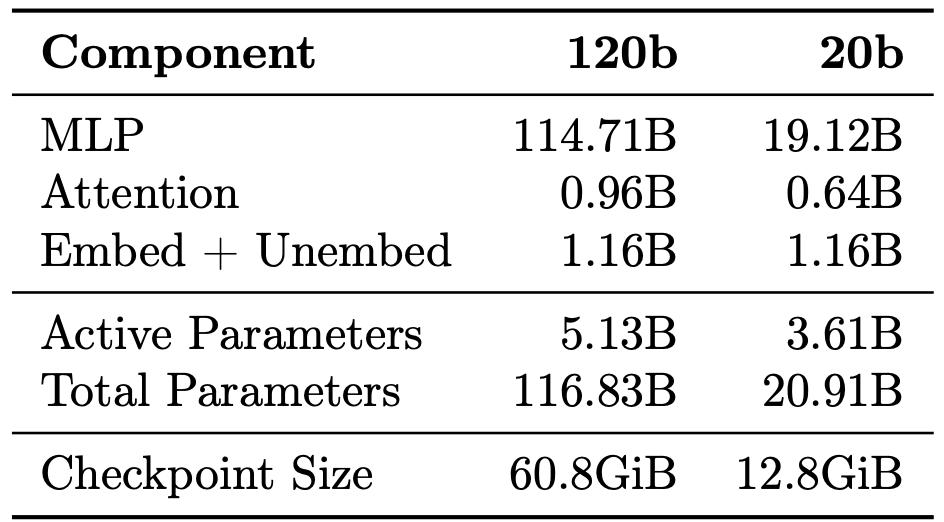
(注:显存容量通常会大于Checkpoint Size)
相比以往的数据类型,MXFP4提供了极高的性价比,模型运行所需的硬件资源仅为之前的四分之一。
MXFP4有什么魔力?
在gpt-oss中,OpenAI将MXFP4量化应用于大约90%的权重,这一操作的直接动机(收益)就是让模型运行成本变得更加便宜。
将gpt-oss模型量化为MXFP4 后,大语言模型的占用内存仅为等规模BF16模型的1/4,而且生成token的速度最高可提升4倍。

如何通过改变数据类型降低模型运行成本?这里的逻辑是这样的:
模型的运行成本主要由权重存储和内存带宽两个部分组成。
前者是模型参数存放和占用的空间,也就是存储它们所需要的字节数。
后者则是模型在推理时,数据读写速度和容量的限制。
数据类型的变化将直接影响权重存储和内存带宽的占用。
例如,传统模型权重通常用FP32(32位浮点数)存储,每个参数占用4字节内存。
如果用MXFP4,那么每个权重只有半字节,权重存储大小是FP32的1/8,这就极大地压缩了权重数据量的大小。
这一压缩不仅降低了模型的存储空间,还能让模型在同样的带宽下完成更快地数据读取和写入,从而提高推理速度。
由此,通过改变数据类型就能实现推理成本的降本增效。
那么,MXFP4是怎么实现这一点的?
MXFP4
MXFP4的全称是微缩放4位浮点数(Micro-scaling Floating Point 4-bit),是由Open Compute Project (OCP) 定义的4位浮点数据类型。
(注:OCP是Facebook于2011年发起的超大规模数据中心合作组织,旨在降低数据中心组件成本并提高可获取性。)
在深度学习领域中,数据类型的精度和效率一直是研究者取舍的重点。
例如,传统的FP4只有四位,1位符号位(表示正负),2位指数位(决定数值的量级),1位尾数位(表示小数部分)。
这种表示方法虽然压缩了数据量,但也导致了非常有限的可表示的数值范围,它只能表示8个正数和8个负数。
相较之下,BF16(1位符号位,8位指数位和7 位尾数位)则能表示 65,536个数值,不过表示范围的增加也带来了计算成本的上升。
如果为了提高计算效率,直接把这4个BF16数值:0.0625、0.375、0.078125、0.25直接转换成FP4,那么它们会变成 0、0.5、0、0.5。
不难看出,这样的误差显然是无法接受的。
于是,为了在减少数据量的同时确保一定的精度,MXFP4通过将一组高精度数值(默认32个)乘以一个公共缩放因子(这个缩放因子是一个8位二进制指数)。这样,我们前面那4个BF16数值就会变成 1、6、1.5、4。
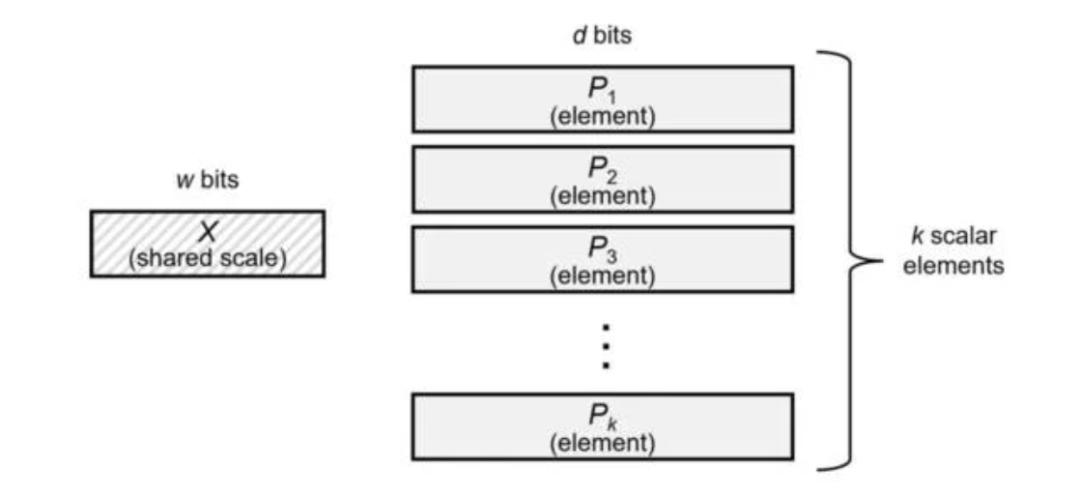
这样就既实现了极致的数据大小,又维持了数值间大小关系的精度。
此外,这一过程的实现还与计算硬件相关。
一般规律是,每将浮点精度减半,芯片的浮点吞吐量就能翻倍。
比如,一个B200SXM模块的稠密BF16运算性能约为2.2 petaFLOPS,降到FP4(Nvidia Blackwell 芯片提供硬件加速)后,就能提升到9petaFLOPS。
虽然这会在吞吐量上带来一些提升,但在推理阶段,更多FLOPS的意义主要是减少模型开始生成答案的等待时间。
值得注意的是,运行MXFP4模型并不要求硬件必须原生支持FP4。
用于训练gpt-oss的Nvidia H100就不支持原生FP4,不过它依然可以运行,只是无法享受该数据类型的全部优势。
低精度与计算量的取舍
事实上,MXFP4并不是新概念。早在2023年的报告中,OCP就在报告《OCP Microscaling Formats (MX) Specification Version 1.0》中详细介绍过这一数据类型。
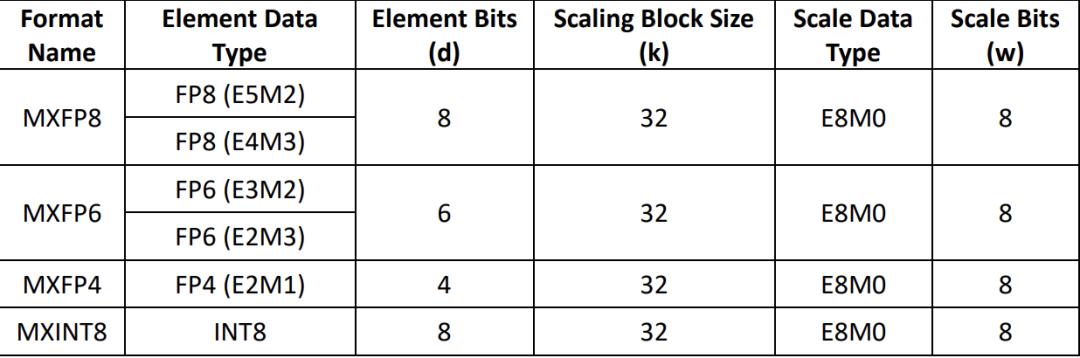
然而,这种低精度的数据类型通常被认为是对性价比的妥协,因为精度下降会导致质量损失。损失的程度取决于具体的量化方法。
不过,已经有足够多的研究表明,将数据精度从16位降到8位,在大语言模型场景下几乎没有质量损失,这种精度已经足够支撑模型的正常工作。
事实上,一些模型开发者,例如DeepSeek已经开始直接用FP8进行训练。
此外,虽然MXFP4比标准FP4好得多,但它也有缺陷。
例如,英伟达就认为这种数据类型相比FP8仍可能出现质量下降,部分原因是其缩放块大小(Scaling Block Size)为32,不够细粒化。
为此,英伟达推出了自己的微缩放数据类型NVFP4,通过将缩放块大小降至16和使用FP8缩放因子来提高质量。
这几乎等同于FP8的工作方式。只不过MXFP4是在张量内部的小块上应用缩放因子,而不是作用于整个张量,从而在数值之间实现更细的粒度。
最后,在gpt-oss上,OpenAI只使用了MXFP4。
鉴于OpenAI在AI领域上的影响力,这基本上就等于在说:
如果MXFP4对我们够用,那对你也应该够用。
参考链接
[1]https://www.theregister.com/2025/08/10/openai_mxfp4/
[2]https://cdn.openai.com/pdf/419b6906-9da6-406c-a19d-1bb078ac7637/oai_gpt-oss_model_card.pdf
[3]https://www.opencompute.org/documents/ocp-microscaling-formats-mx-v1-0-spec-final-pdf
本文来自微信公众号“量子位”,36氪经授权发布。
