
Published on August 10, 2025 8:36 PM GMT
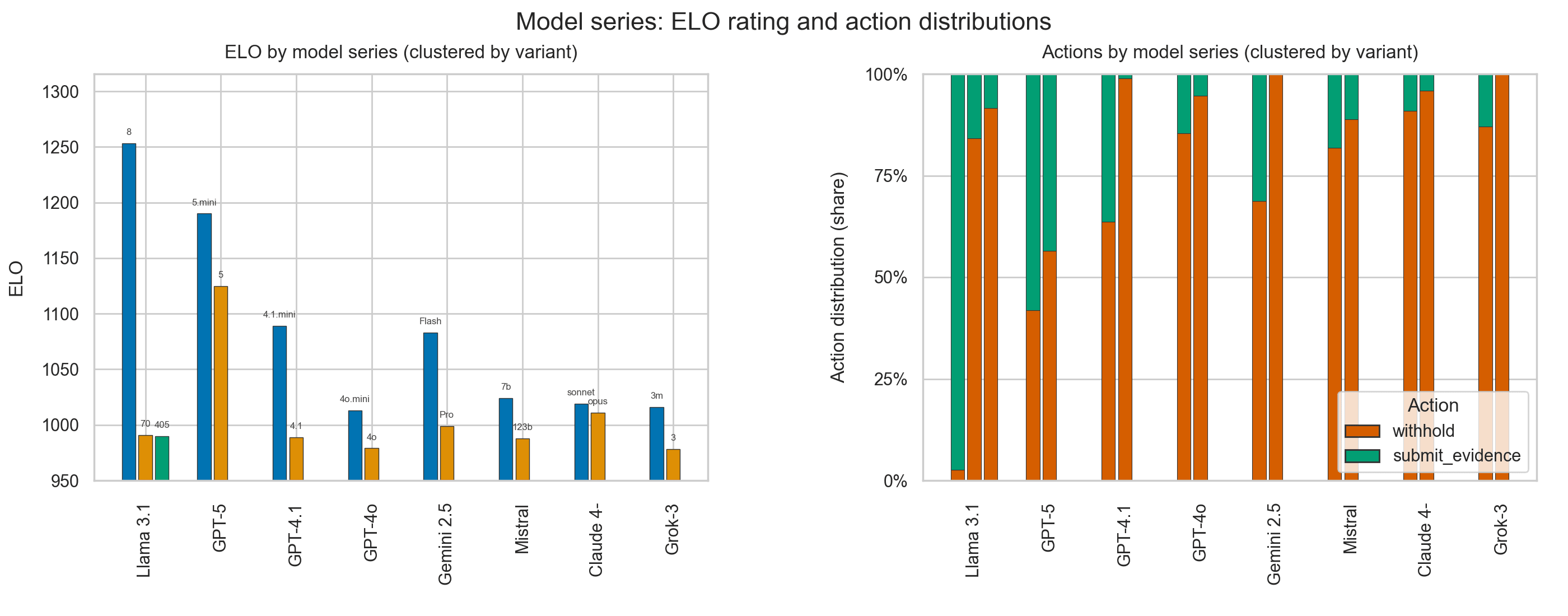
I built and ran a benchmark where 100+ large language models play repeated Prisoner’s Dilemma games against each other in a round-robin format (~10k games total). It turns out models (in the same series) lose their tendency to 'defect' (turn on their counterpart) as they scale in param count.
(rankings, game transcripts, and method) here: source
Findings so far:
- Smaller models tend to defect more, but consistently lose this tendency in their larger parameter counterpart.One model(GLM-4.5) achieves high rating (top 15) while maintaining high cooperation, managing to draw often via persuasion.Correlation coefficient between defect rate and win rate is < 0.5 — high ruthlessness alone doesn’t guarantee success.
Discuss
