
Editor’s note: Welcome Matvei of Roboflow to the Latent Space guest author crew! notice how GPT-5-Mini’s vision scores the same as GPT-5’s vision. This is an expected consequence of a very good model router at work.
Something that went under the radar in OpenAI’s release today is GPT-5’s vision and visual reasoning capabilities. Adding visual understanding to LLMs has proven to be difficult, with most models not being able to correctly count 4 coins in a photo or locate where specific items are in an image.
LLMs being able to understand the world around them in real-time is the breakthrough people are looking for to enable the autonomous robotics or computer-using revolution and open up the era of personal superintelligence.
Current state of LLMs and visual understanding
The combination of reasoning and visual capabilities has been present in several models like OpenAI GPT and o series models, Google’s Gemini models, Anthropic’s Claude models, and Meta’s Llama models. Models tend to have specific strengths and weaknesses depending on the task type:
Tasks like reading text, signs, receipts, CAPTCHAs, and understanding colors are generally solved by all models.
But harder tasks, like counting, spatial understanding, object detection, and document understanding have high levels of performance variability, especially if it is known to be deficient in most internet-scale pretrain data.

The variance across tasks types makes general comparison difficult but that’s why leaderboards, like Vision Checkup, have recently launched. Vision Checkup is our open source vision model evaluation leaderboard and it gives us insight into hard task frontier performance. As you can see, OpenAI dominates in vision capabilities and the launch of GPT-5 adds another model into the top 5.
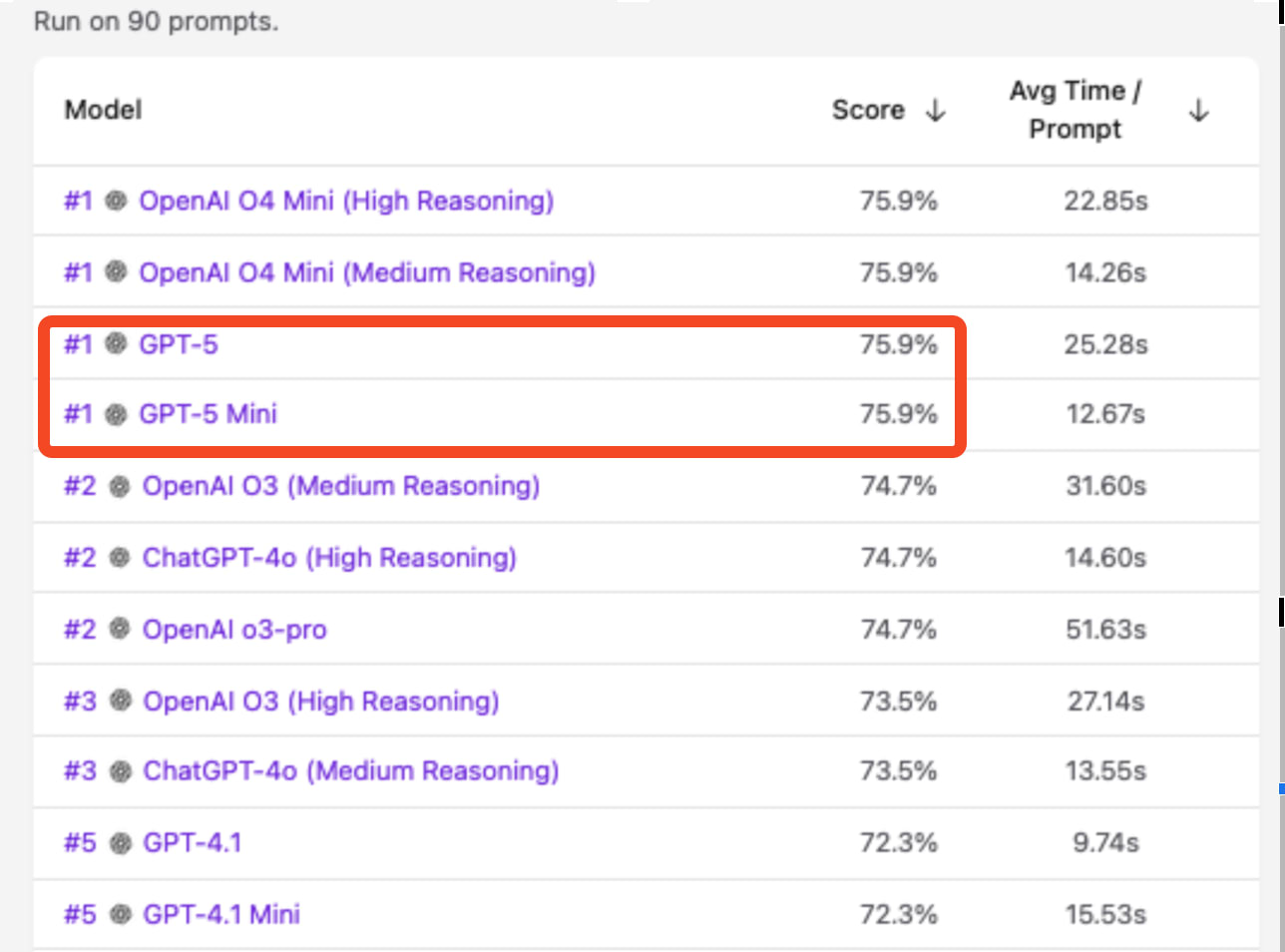
The leaderboard makes it clear – top models are all reasoning models.
Reasoning is driving OpenAI dominance in general vision tasks
The top models on the Vision Checkup leaderboard are configurations of models with reasoning capabilities.
We suspect that the good results of these models can be attributed more to their reasoning capabilities from pretraining and during test time. This marks the continuation of an important development in multi-modal large language models: the ability to reason over both text and vision modalities.
With that said, scores vary significantly between updates and you can attribute this to multiple reasons. The biggest one is the nondeterminism of reasoning mode for OpenAI models; prompting a reasoning model with the same question twice can lead to both correct and incorrect answers.
When it comes to real-world use, reasoning on images currently takes too much time to be useful and variability of answers makes them difficult to rely on. For most developers, 10+ seconds to understand an image won’t unlock real time use cases. There is a trade off to be made between speed and capability. Depending on the task, a faster model with a more narrow range of knowledge could be the best decision.
Beyond Vision Vibe Checks
We are still far from a world where autonomous robotics can interact with the world around them in real time. Simple tasks like counting, spatial understanding, and object localization are key for any robot to perform general tasks outside of a controlled environment.
To get us beyond leaderboards with lightweight vibe checks, we need to test LLMs across a wide range of domains and track their progress. We released a new benchmark, RF100-VL, at this year’s CVPR conference to provide a more difficult set of visual understanding and grounding benchmarks. The benchmark asks “How well does your LLM understand the real world?”. RF100-VL consists of 100 open source datasets from the Roboflow Universe community containing object detection bounding boxes and multimodal few shot instruction with visual examples and rich textual descriptions across novel image domains.
The top LLMs scored below 10 mAP50:95 for identifying novel objects in real world contexts. The current SOTA among all LLMs is Gemini 2.5 Pro, achieving a zero-shot mAP50:95 of 13.3:
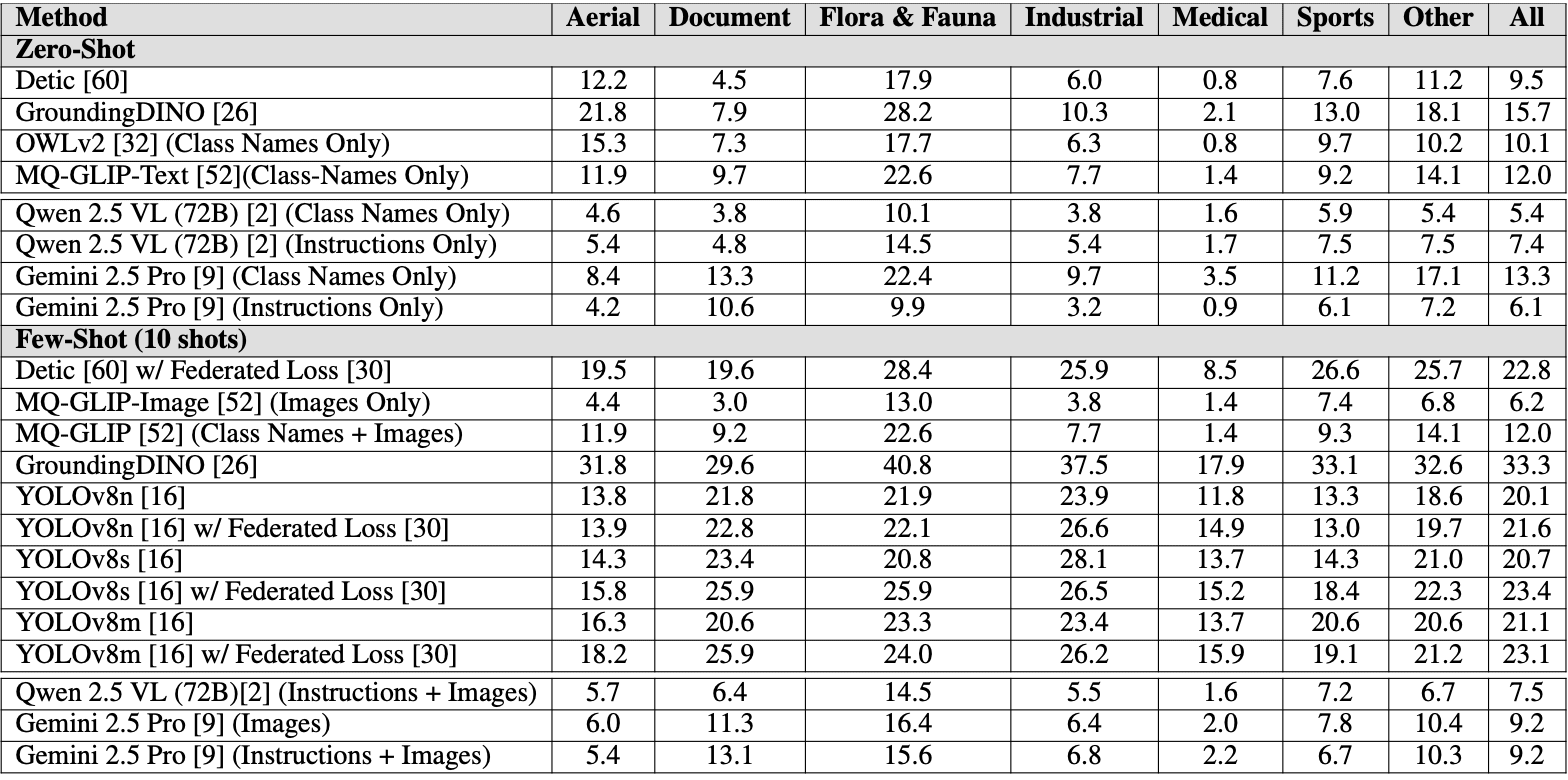
We suspect that the key distinction between OpenAI models and models like Gemini or Qwen, when it comes to object detection tasks, is that OpenAI models don’t include any object detection data in their pretraining.
After running GPT-5 on RF100-VL we got the mAP50:95 of 1.5. This is significantly lower than the current SOTA of Gemini 2.5 Pro of 13.3. We largely attribute this shortcoming to lack of object detection pre-training for GPT-5.
Let’s inspect some of its results below to develop more intuition into why the score may be so low.
Example: Localization
This is an example from a volleyball dataset, which demonstrates the key issue causing low scores. We observe that the model has a good understanding of objects in the images, you can see it correctly understanding that there is a ball, two blockers, and some defenders present.
However it is unable to localize them, all of the boxes are not matching the objects locations and sizes. It seems like the model is good at understanding the image, but not good at grounding the specific objects within it, which again we attribute to lack of object detection tasks in pre-training.

We can see a similar situation with a sheep dataset below:

Example: UI Elements
With recent developments in LLMs for tool use and vision-powered agentic workflows, let's look at GPT-5 performance there. We don’t see any uplift in quality in the UI elements dataset either:
Next up, let’s see if GPT5 is better compared to previous OpenAI models:

GPT-5 has gotten slightly better than o3. And in both cases providing additional information, such as detailed instructions, helps the model.
Interestingly, changing the reasoning effort to high doesn’t improve the scores for RF100-VL. So the benefit of reasoning is not as obvious in the RF100-VL case and suspect it to be due to lack of object detection capabilities, arising from lack of object detection tasks in the pretraining.
GPT-5 is a slight improvement for simple visual tasks
GPT-5’s enhanced reasoning brings it high up on the Vision Checkup leaderboard, proving that multi-step thinking lets a model squeeze more juice out of the pixels. A great outcome for everyday use cases that people are likely relying on ChatGPT to help them solve.
RF100-VL helps highlight that comprehension ≠ localization. Without object-detection priors, the detections still miss the mark. Even so, GPT-5’s jump in vision-reasoning spotlights a clear path forward: models that don’t just see better but think more deeply about what they’re seeing.
